

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号


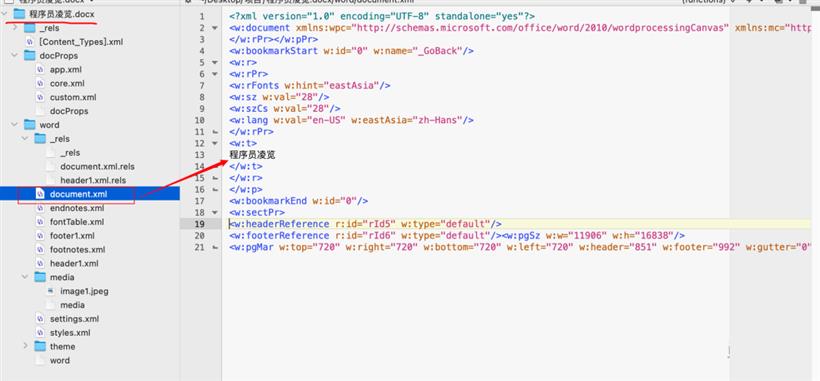
3.doc是二进制文件,docx是xml文件。docx扩展名可修改为zip、rar等压缩包格式,使用压缩软件打开,查看内部各类文件,实现批量替换图片等
const mammoth = require("mammoth");
mammoth.convertToHtml({path: "path/to/document.docx"})
.then(function(result){
const html = result.value; // 转换的HTML
const messages = result.messages;
})
.catch(function(error) {
console.error(error);
});
这是在Node.js环境中的案例,浏览器环境是无法通过{path: "path/to/document.docx"}来读取到docx文件。如果是要在浏览器环境中执行它,需要docx文件转化为arrayBuffer数组再作为参数传递给convertToHtml:const updateWord = {
handleFileSelect(event) {
const self = this
this.readFileInputEventAsArrayBuffer(event, function (arrayBuffer) {
mammoth.convertToHtml({ arrayBuffer: arrayBuffer }, {
//堆代码 duidaima.com
})
}
},
//文件转化成arrayBuffer数据类型
readFileInputEventAsArrayBuffer(event, callback) {
const file = event.target.files[0];
const reader = new FileReader();
reader.onload = function (loadEvent) {
const arrayBuffer = loadEvent.target.result;
callback(arrayBuffer);
};
reader.readAsArrayBuffer(file);
}
}
//获取文件file后,传递给handleFileSelect函数
updateWord.handleFileSelect(file)
Word文档也许存在图片,Mammoth默认会把图片转成base64格式,这样我们得到的HTML内容会特殊的大。正常情况我们肯定是想要把图片上传到我们自己的服务器,HTML内容保留图片链接即可。const updateWord = {
//base64格式转blob
base64ToBlob(base64, mimeType) {
let bytes = window.atob(base64);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ia], { type: mimeType });
},
handleFileSelect(event,{success, fail}) {
const self = this
this.readFileInputEventAsArrayBuffer(event, function (arrayBuffer) {
mammoth.convertToHtml({ arrayBuffer: arrayBuffer }, {
//处理图片
convertImage: mammoth.images.imgElement(function (image) {
return image.read("base64").then(async (imageBuffer) => {
//base64转blob
const blob = self.base64ToBlob(imageBuffer, 'image/png')
blob.name = Date.now() + '.png'
const result = await new Promise((resolve, reject) => {
//图片上传逻辑,可以自定义
upImage({ file: blob }, {
resolve,
reject
})
})
const url = result.default
return {
src: url
}
});
})
}).then(success, fail);
}
},
//...
}
upImage是上传图片到我们自己服务器的逻辑,这个逻辑大家自定义发挥,只要最后把图片链接返回return {src: url},它会把base64替换掉。




