你是否曾听说过避免在Kubernetes中运行数据库的建议?有人认为Kubernetes不适合有状态的应用程序,但这些说法是否属实?让我们深入探讨并挑战这些说法。
Kubernetes:有关有状态工作负载的误解平台
在涉及有状态应用程序时,Kubernetes经常受到不公平的抨击。这种误解源自早期阶段,当时我们的选择局限于部署(Deployments)和有状态集(StatefulSets)。最初认为有状态集应该是数据库的首选。然而,这忽略了Kubernetes的真实本质——一种设计用于定制化的可扩展平台。
网络和存储是Kubernetes的典型例子。我们并不依赖内置功能,而是通过CNI和CSI插件增强功能以适应我们特定的需求。这个原则也适用于数据库,尽管由于缺乏标准的数据库接口,这条路并不那么直接。
有状态集的困境
最初,早期采用者使用有状态集在Kubernetes上运行数据库。它们提供了一定程度的秩序——可预测的扩展性、稳定的网络标识符和持久化存储。然而,仅有有状态集是不足以在生产环境中管理数据库的,生产环境需要备份、故障转移、可观察性等更多功能。
自定义资源定义
对于Kubernetes中的数据库来说,真正改变游戏规则的是自定义资源定义(CRDs)和自定义控制器,也称为运算符(operators)。这些Kubernetes扩展允许创建具有自定义逻辑和生命周期管理的复杂有状态应用程序。换句话说,它们赋予了Kubernetes智能、高效地处理数据库的能力。这种方法将Kubernetes的功能扩展到了远远超出其核心功能的领域,使其能够满足数据库管理的复杂需求。
使用Cloud Native PG运行PostgreSQL
为了说明问题,让我们探讨一下使用Cloud Native PG项目在Kubernetes上运行PostgreSQL。CloudNativePG的设计允许在多个区域扩展PostgreSQL架构,提供了一个强大的灾难恢复框架,RPO(恢复点目标)极小。使用Cloud Native PG,你不仅仅是通过有状态集来管理Pods;你正在利用一个专用控制器,它封装了数据库管理的一系列扩展职责。该项目体现了Kubernetes作为基础平台到成为一个完全成熟的运行数据库的强大平台的转变。它支持从高可用设置到备份、扩展和配置管理的所有内容,都是通过CRDs进行声明性定义。
Cloud Native PG的架构
高可用性和流复制
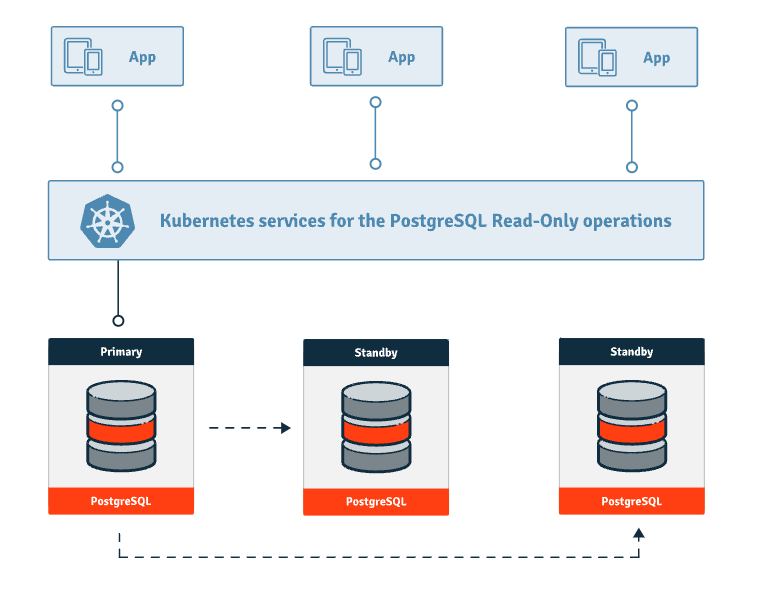
在核心层,CNPG同时支持异步和同步流复制。它允许配置一个主实例,以及多个热备份副本以实现同一Kubernetes集群内的高可用性。服务可供应用程序连接到主实例(**-rw**)、热备份副本(**-ro**)或任何实例进行只读工作负载(**-r**)。
共享无
CNPG推荐采用共享无体系结构以增强韧性。这意味着PostgreSQL实例位于不同的Kubernetes工作节点上,跨越不同的可用区,不共享存储。每个节点理想情况下使用本地卷(local volumes)存储PostgreSQL数据,从而提高集群的容错性。CNPG自动化地更新服务以适应集群拓扑的变化。例如,在故障转移期间,它会更新**-rw**服务,将应用程序流量重定向到新晋升的主实例,确保无缝的连续性。
读写和只读工作负载
应用程序可以连接到**-rw**服务以在主实例上执行写操作。对于只读工作负载,应用程序使用**-ro**服务连接到热备份副本,从而分担主节点的查询负载。这种设置旨在优化集群中的工作负载分布。
 多集群部署和灾难恢复
多集群部署和灾难恢复
CNPG通过一个名为副本集群(Replica Cluster)的功能,支持跨多个Kubernetes集群的部署。这种设置涉及在一个集群中拥有一个可写主实例,以及在其他集群中拥有只读副本集群,促进全球性的灾难恢复,并减少RPO(恢复点目标)和RTO(恢复时间目标)。
部署运算符
要开始使用CloudNativePG(CNPG),你需要在你的Kubernetes环境中部署运算符。可以通过使用**kubectl**应用一个YAML清单文件来完成。按照以下步骤安装CNPG运算符:
•安装所需版本的运算符清单文件。可以使用以下命令:
kubectl apply -f https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.20/releases/cnpg-1.20.4.yaml
•通过检查部署状态来验证安装:
kubectl get deploy -n cnpg-system cnpg-controller-manager
默认情况下,运算符作为Kubernetes的**Deployment**安装在**cnpg-system**命名空间中。此部署的名称取决于安装方法。
•使用**kubectl**中的**describe**命令获取有关运算符部署的更多详细信息:
kubectl describe deploy -n cnpg-system
部署PostgreSQL集群
一旦CNPG运算符安装完成,你可以通过应用定义所需的**Cluster**配置文件来部署PostgreSQL集群。下面是一个示例配置文件(**cluster-example.yaml**),它定义了一个使用默认存储类的简单的3节点PostgreSQL集群:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
instances: 3
primaryUpdateStrategy: unsupervised
storage:
size: 1Gi
使用以下命令应用配置文件来创建一个3节点的PostgreSQL集群:
kubectl apply -f cluster-example.yaml
你可以使用**get pods**命令检查集群Pods的状态:
kubectl get pods
通过按照这些步骤,你可以在Kubernetes环境中快速设置CNPG运算符并部署PostgreSQL集群。为了将你的集群与其他工作负载隔离开来,考虑创建一个单独的命名空间或使用标签来识别与特定集群相关的对象。运算符将为了便于管理将**cnpg.io/cluster**标签应用于相关对象。
Kubernetes和数据库的未来
Cloud Native PG证明了Kubernetes适合数据库,特别是在增强了CRDs和自定义控制器的情况下。它已经提交给CNCF进行孵化,有望成为生态系统中的PostgreSQL旗舰项目。
选择正确的数据库管理路径
关键的决策在于选择托管数据库服务还是自管理方法。在后一种情况下,Kubernetes在如Cloud Native PG这样的解决方案中表现出色,为其采用提供了一个有力的论据。
结论:拥抱Kubernetes的方式
Kubernetes已经成长为运行数据库的最佳平台,前提是我们要接受其可扩展的本质。Cloud Native PG不仅是一个选择;它是PostgreSQL的首选,提供了丰富的功能集和开源社区支持的保证。如果你倾向于自管理数据库,考虑Cloud Native PG——它不是替代方案,而是未来发展的最佳方式。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






