

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

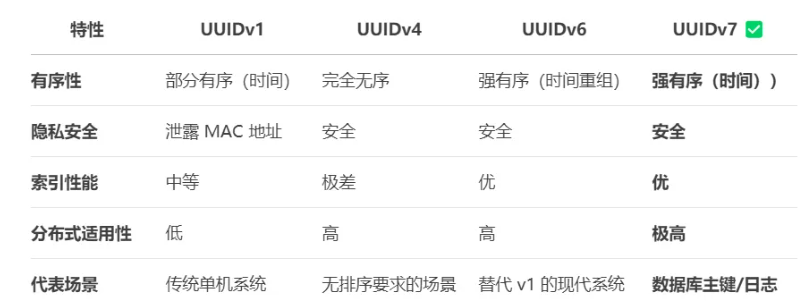
.导致索引更大,占用更多内存/磁盘,缓存效率降低,查询变慢
.尾部随机位(74位):保证分布式唯一性,避免 v1 的 MAC 地址泄露风险。
import com.github.f4b6a3.uuid.UuidCreator;
public class UuidUtils {
public static UUID generateUuidV7() {
return UuidCreator.getTimeOrdered(); // 生成 UUIDv7
}
// 转为数据库存储格式
public static byte[] toBytes(UUID uuid) {
ByteBuffer bb = ByteBuffer.wrap(new byte[16]);
bb.putLong(uuid.getMostSignificantBits());
bb.putLong(uuid.getLeastSignificantBits());
return bb.array();
}
// 堆代码 duidaima.com
// 从数据库读取转换
public static UUID fromBytes(byte[] bytes) {
ByteBuffer bb = ByteBuffer.wrap(bytes);
return new UUID(bb.getLong(), bb.getLong());
}
}
// 使用示例
UUID id = UuidService.generateUuidV7();
数据库作为主键CREATE TABLE users (
id BINARY(16) PRIMARY KEY, -- 二进制存储 UUID
name VARCHAR(50) NOT NULL,
email VARCHAR(100)
);
插入数据库和查询// 插入数据
UUID userId = UuidUtils.generateUuidV7();
String sql = "INSERT INTO users (id, name) VALUES (?, ?)";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setBytes(1, UuidUtils.toBytes(userId));
ps.setString(2, "John Doe");
ps.executeUpdate();
}
// 查询数据
String query = "SELECT * FROM users WHERE id = ?";
try (PreparedStatement ps = conn.prepareStatement(query)) {
ps.setBytes(1, UuidUtils.toBytes(userId));
ResultSet rs = ps.executeQuery();
while (rs.next()) {
UUID id = UuidUtils.fromBytes(rs.getBytes("id"));
String name = rs.getString("name");
}
}
五. 关于UUIDv7 常见问题解答




