我们知道,MySQL 的索引设计使用了 B+ 树,而 PostgreSQL 使用了 B- 树,那 PostgreSQL 为什么不使用 B+ 树做索引结构呢?今天就来聊一聊这个话题。
B+ 树和 B- 树
B+ 树
B+ 树主键索引的叶子节点存储数据,非叶子节点(索引节点)则存储 key 和指针。这样存储的优势是可以在索引节点通过二分查找快速找到数据所在页,时间复杂度为 O(logmN),其中 N 是总的节点数量,m 是每个节点的子节点个数。找到数据页后再去数据页中找数据就很容易了。
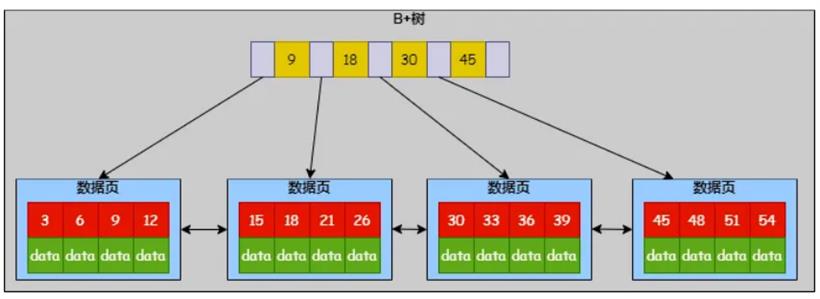
B+ 树的第二个特点是叶子节点用双向链表串联起来,这样范围查询优势很大,时间复杂度为O(logmN+K)。
B- 树
跟 B+ 树不一样的是,B- 树所有节点都可以存储数据,包括根节点,内部节点,叶子节点。
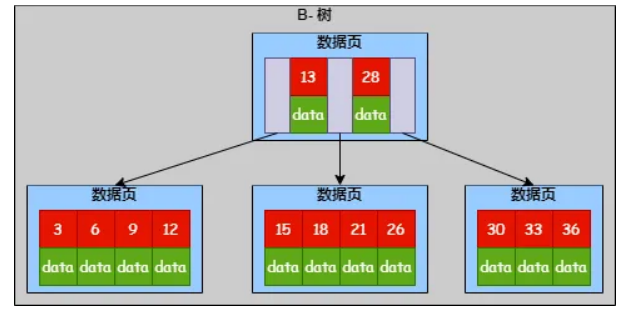
随机查询:因为 B- 树在非叶子节点也能存储数据,B- 树可能在非叶子节点提前终止查询,查询路径更短。
范围查询:B- 树查询一个数据范围时需要中序遍历多个层级,这一点效率不如 B+ 树。
PostgreSQL 索引
索引介绍
PostgreSQL 索引对 B- 树进行了改造。改造后的索引结构如下图:
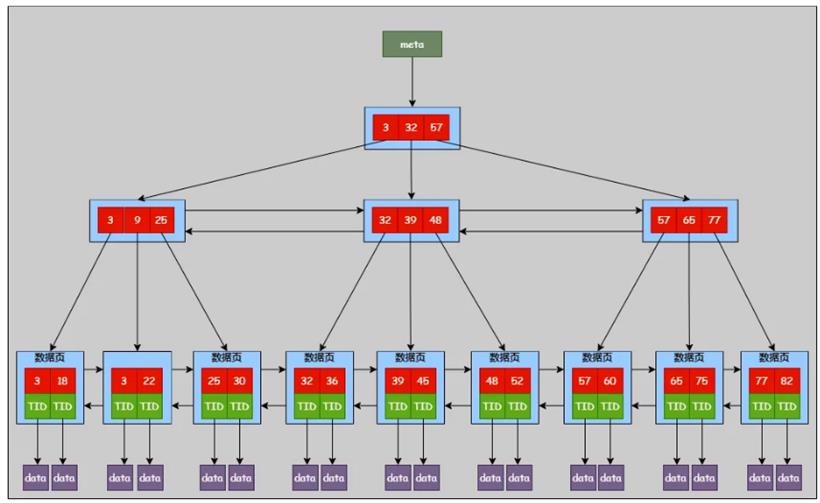
上图的索引结构中最顶层是元数据页,存储索引根节点页相关信息。内部节点位于根节点下面,只包含键值和指向子页面的指针。叶子页位于最下面一层,存储所有指向实际表数据行(TIDs)的指针。什么是 TID?PostgreSQL 采用堆表存储,数据独立于索引存储在一个无序的结构中。数据行插入时,数据库会找到一个空闲的空间来存放它,并记录一个唯一的物理地址,称为 TID,由页号和行指针组成。
因为 B- 树的叶子节点只保存 TIDs,不保存真实数据,因此每个数据页能保存更多的叶子节点。跟 B+ 树相比,在相同数据量下,B- 树高度更低。PostgreSQL 索引中无论是内部节点还是叶子节点,数据都以递增顺序存储,同一层的数据页由双向链表连接。因此通过遍历链表就可以获取一个有序的数据集,范围查询并不需要中序遍历。
PostgreSQL 索引页格式如下,(下图来自官网):
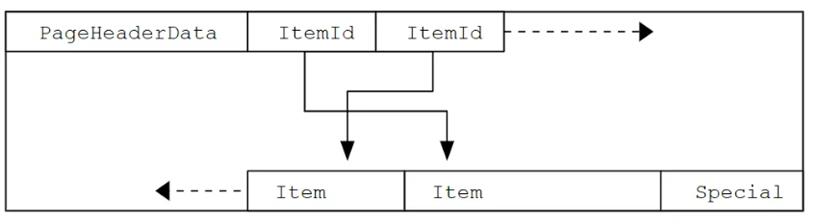
下表对每个属性进行解释:
|
Item
|
Description
|
|
PageHeaderData
|
24 bytes long. Contains general information about the page, including free space pointers.
|
|
ItemIdData
|
Array of item identifiers pointing to the actual items. Each entry is an (offset,length) pair. 4 bytes per item.
|
|
Free space
|
The unallocated space. New item identifiers are allocated from the start of this area, new items from the end.
|
|
Items
|
The actual items themselves.
|
|
Special space
|
Index access method specific data. Different methods store different data. Empty in ordinary tables.
|
再回到文章题目的问题,虽然 PostgreSQL 的索引结构在工程上被称作 B-Tree,但其实它实现了 B+ 树的功能,从功能上看,他其实也是一棵 B+ 树。
三个优化
1.Deduplication
在索引中,如果存在大量相同的键值(比如一个被频繁更新的状态标志),PostgreSQL 会将这些重复的键值合并存储,只保留一个键值和多个对应的 TID 列表,这大大节省了空间,提高了缓存效率。
2.Index Only Scan
虽然叶子节点不保存完整数据,但叶子节点中除了存储键值和 TID,也可以保存查询中需要的某几个字段值(非索引列值),类似于覆盖索引。这样,对于只查询索引列和包含列的语句,可以不用通过 TID 去堆上查找数据,直接通过索引就获取到查询结果。
3.反向键索引
PostgreSQL 可以创建反向排序的索引,这对于缓解插入热点(如递增主键、时间等字段)问题非常有效。创建索引的时候需要指定反向索引,例如下面 SQL 给员工编号(emp_id)创建一个反向键索引:
# 堆代码 duidaima.com
CREATE INDEX idx_emp_id ON tb_emploee(emp_id REVERSE);
总结
PostgreSQL 的索引结构虽然叫 B- 树,但其实它实现了 B+ 树的功能,并且在索引上做了一些优化,使索引效率更高。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






