

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

前言:
我在开发系统这么多年终,经常遇到的一个问题就是中文乱码问题。所以,今天我们就乱码的相关话题展开讨论。
为什么会出现乱码
乱码也就是英文常说的mojibake(由日语的文字化け音译)。 简单的说乱码的出现是因为:编码和解码时用了不同或者不兼容的字符集。对应到真实生活中,就好比是一个英国人为了表示祝福在纸上写了bless(编码过程)。而一个法国人拿到了这张纸,由于在法语中bless表示受伤的意思,所以认为他想表达的是受伤(解码过程)。这个就是一个现实生活中的乱码情况。在计算机科学中一样,一个用UTF-8编码后的字符,用GBK去解码。由于两个字符集的字库表不一样,同一个汉字在两个字符表的位置也不同,最终就会出现乱码。 我们来看一个例子:假设我们用UTF-8编码存储很屌两个字,会有如下转换:
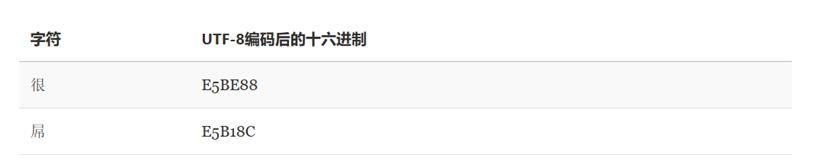
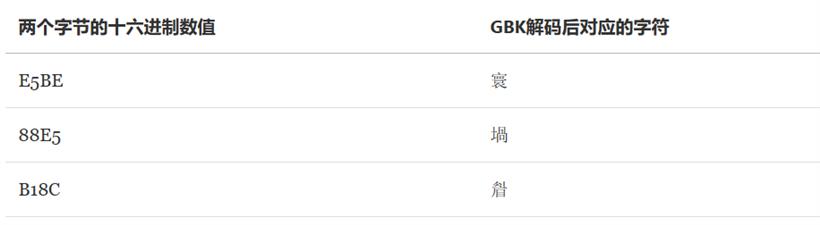
解码后我们就得到了寰堝睂这么一个错误的结果,更要命的是连字符个数都变了。
如何识别乱码的本来想要表达的文字
要从乱码字符中反解出原来的正确文字需要对各个字符集编码规则有较为深刻的掌握。但是原理很简单,这里用最常见的UTF-8被错误用GBK展示时的乱码为例,来说明具体反解和识别过程。
第1步 编码
假设我们在页面上看到寰堝睂这样的乱码,而又得知我们的浏览器当前使用GBK编码。那么第一步我们就能先通过GBK把乱码编码成二进制表达式。当然查表编码效率很低,我们也可以用以下SQL语句直接通过MySQL客户端来做编码工作:
# 堆代码 duidaima.com
mysql [localhost] {msandbox} > select hex(convert('寰堝睂' using gbk));
+-------------------------------------+
| hex(convert('寰堝睂' using gbk)) |
+-------------------------------------+
| E5BE88E5B18C |
+-------------------------------------+
1 row in set (0.01 sec)

mysql [localhost] {msandbox} ((none)) > select convert(0xE5BE88E5B18C using utf8);
+------------------------------------+
| convert(0xE5BE88E5B18C using utf8) |
+------------------------------------+
| 很屌 |
+------------------------------------+
1 row in set (0.00 sec)
常见问题处理之Emoji

 那么Emoji字符表情会对我们平时的开发运维带来什么影响呢?
那么Emoji字符表情会对我们平时的开发运维带来什么影响呢?
最常见的问题就在于将他存入MySQL数据库的时候。一般来说MySQL数据库的默认字符集都会配置成UTF-8(三字节),而utf8mb4在5.5以后才被支持,也很少会有DBA主动将系统默认字符集改成utf8mb4。那么问题就来了,当我们把一个需要4字节UTF-8编码才能表示的字符存入数据库的时候就会报错:ERROR 1366: Incorrect string value: '\xF0\x9D\x8C\x86' for column 。
如果认真阅读了上面的解释,那么这个报错也就不难看懂了。我们试图将一串Bytes插入到一列中,而这串Bytes的第一个字节是\xF0意味着这是一个四字节的UTF-8编码。但是当MySQL表和列字符集配置为UTF-8的时候是无法存储这样的字符的,所以报了错。
那么遇到这种情况我们如何解决呢?有两种方式:升级MySQL到5.6或更高版本,并且将表字符集切换至utf8mb4。第二种方法就是在把内容存入到数据库之前做一次过滤,将Emoji字符替换成一段特殊的文字编码,然后再存入数据库中。之后从数据库获取或者前端展示时再将这段特殊文字编码转换成Emoji显示。第二种方法我们假设用-*-1F601-*-来替代4字节的Emoji,那么具体实现python代码可以参见Stackoverflow上的回答





