使用消息队列时,我们经常会遇到一个可能对业务产生影响的问题,消息重复。在订单、扣款、对账等对幂等有要求的场景,消息重复的问题必须解决。那怎样应对重复消息呢?今天来聊一聊这个话题。
1.三个语义
正确使用消息队列,我们会考虑到消息防丢失、防重复,我们介绍 3 个语义:
At Least Once:在消息队列中,指消息不丢失,一条消息最少被消费一次,但是可能会有重复消费。
Exactly Once:在消息队列中,消息被精准消费一次,不丢失,也不会重复;
At Most Once:在消息队列中,消息不会被重复消费,但是可能会有消息丢失
不同的消息场景,需要的语义不同。比如 Exactly Once 最难实现,一般需要引入事务消息。
不同使用场景,对语义的要求也不一样。比如日志收集类的场景,At Most Once 就可以满足,而支付类的场景则要求 Exactly Once。
2.消息重复
什么情况下会导致消息重复呢?生产者发送消息后,Broker 保存成功,但是没有成功给生产者返回 ACK,生产者以为消息发送失败,重试,再次给 Broker 发送。Broker 保存了重复消息,导致 Consumer 多次消费。
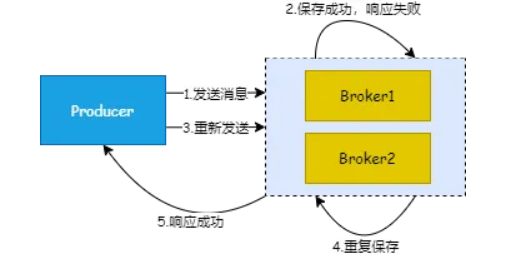
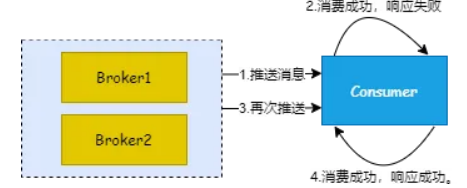
消费者消费消息后,给 Broker 返回 ACK 失败,导致 Broker 没有修改偏移量,同一条消息再次发送给消费者,或者被消费者拉取到。
 3.生产者防重
3.生产者防重
有的消息中间件是支持生产者幂等的。比如 Kafka 从 0.11.0 版本开始引入了幂等 Producer,可以使用下面代码开启幂等 Producer:
Properties props = new Properties();
// 堆代码 duidaima.com
//省略其他代码
//配置幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
//创建生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
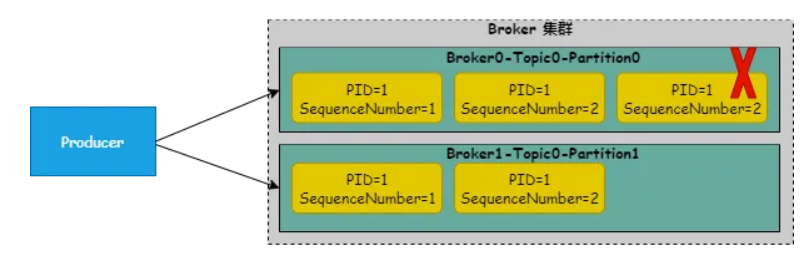
Kafka 实现生产者幂等的原理是在生产者引入了 Producer ID(PID)和 Sequence Number 这两个参数。
PID:Producer 拥有的 ID,唯一标识一个 Producer。
Sequence Number:自增的数值,唯一标识同一个 Producer 发送到指定分区的消息 ID。
有了这两个参数,Broker 单分区就可以唯一标识一个生产者发送的唯一一条消息<PID,SequenceNumber>。Broker 收到消息时,如果检查到消息的<PID,SequenceNumber>已经存在,就不会再保留这条消息。但幂等 Producer 只能在单分区下生效,多分区情况下是不生效的。因为多个分区之间并不能相互访问对方的<PID,SequenceNumber>。
 4.Broker 防重
4.Broker 防重
Broker 如果可以防重,那对于生产者和消费者来说,节省了大量的工作。下面我们看下 Pulsar 是怎样防重的。Broker 通过参数 BrokerDeduplicationEnabled 开启防重功能。对于 Producer 发送的重复消息,Broker 返回响应 -1:-1。
Producer 发送消息时,会带一个 sequenceId 字段,Broker 会按照 ProducerName 维度记录当前生产者最大的 sequenceId(highestSequenceId)。Broker 收到消息时,首先会判断消息中的 sequenceId 是否大于自己保存的当前生产者的 highestSequenceId,如果是则保存消息并更新 highestSequenceId,否则丢弃消息,并且给 Producer 返回 -1:-1。
下面是三个极端情况:
Producer 断开连接:这种情况下,跟 Broker 重新建立连接后,本地保存的 sequenceId 还在,只要使用 sequenceId 递增后发送消息即可;
Producer 宕机:Producer 重启后,缓存的 sequenceId 肯定不存在了,这时跟 Broker 重新建立连接后,Broker 会根据 ProducerName 找出 highestSequenceId 发给 Producer,Producer 使用这个 sequenceId 来发送消息;
Producer 和 Broker 都宕机:Broker 重启后,可以从宕机前保存的快照中恢复各 Producer 对应的 highestSequenceId 发送给各 Producer。但这个 highestSequenceId 不一定准确,因为 Broker 宕机瞬间很有可能最新的 sequenceId 没有来得及保存快照。
需要注意的是,跟 Kafka 的幂等 Producer 类似,Pulsar 的 Broker 幂等也只能保证 Topic/Partition 级别。
5.消费者防重
从上面的分析可以看出,靠生产者防重和 Broker 防重,只能在 Topic/Partition 级别生效,这通常并不能满足我们的需求。而为了避免消费者重复消费对业务造成影响,消息防重还是必要的。这就要求我们做最后一道防线,在消费端进行防重或幂等处理。消费端做防重,就不再考虑消息中间件层面的配置(比如 sequenceId),而是从消息体进行下手。
生产者发送消息时,给消息体赋值一个全局唯一的 ID,消费者处理消息时,根据全局唯一 ID 做防重。比如消费端的逻辑是保存一条订单消息,那把唯一 ID 保存到数据库并且加一个唯一索引,这样根据唯一索引就可以做消息去重。
不过使用唯一索引也有缺点:
.如果使用 MySQL 数据库,不能使用 Change Buffer;
.非插入的场景(比如更新库存)不能去重。
对于唯一索引的缺点,我们可以引入 Redis 对唯一 ID 做保存,利用 setNx 判断消息是否已经处理过。如下图:
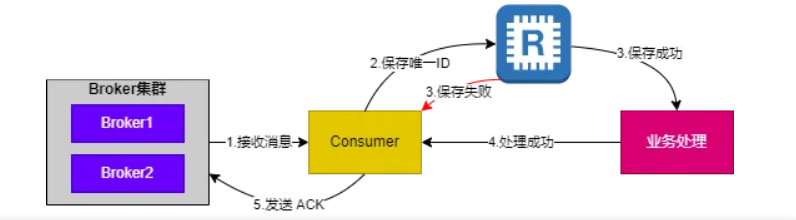
if (jedis.setnx(ID, "1") == 1) {
//处理业务,返回 ACK
}else {
//直接返回 返回 ACK
}
6.总结
使用消息队列,在一些场景下是需要防重的。主流消息队列提供了一些防重的能力,但并不是完全可靠的。在对重复消息敏感的场景下,最好是在消费端处理消息时,从业务层面进行消息防重。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






