“打包”——一个前端研发无比熟悉的词语,打包工具从来都不是必要,后端(nodejs)几乎可以不使用,但在前端,又几乎不可以不用。本文会带读者探究关于打包的一切,前辈们是从什么时候开始打包,又从什么时候开始分包?再发展到现在的在开发环境逐渐不再打包,这个过程我们到底经历了哪些故事?我们又可以依靠哪些工具来实现我们不同时期的目标?这一切离不开前端工程的模块化的演进史~
为什么要打包
生活在 script 标签中
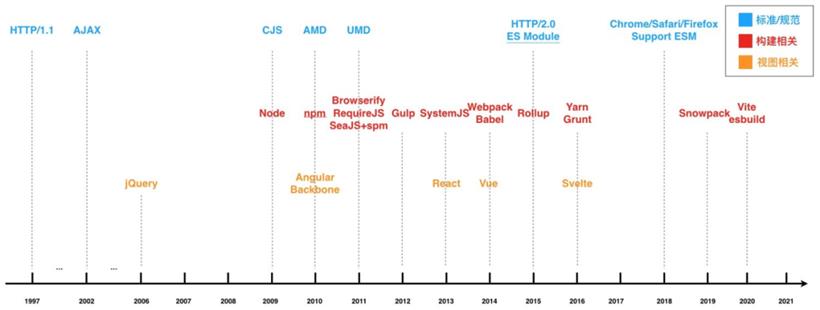
在广泛使用 http1.x 的时代,我们并不能很好的利用带宽:一个 TCP 连接同时只能有一个 http 请求和响应。如果正在发送一个 http 请求,那其他的 http 请求就得排队。为了缓解这个问题,浏览器会对同一个域名建立多个 TCP 连接,来实现 http 的并发。但这也对服务器造成不小的负担,所以浏览器做了限制,所以同一个域名下 TCP 连接数最多会在 6 ~ 8 个左右。
而在 node.js 未诞生时,Javascript 做为一门脚本语言,只能运行在 HTML 的 <script> 中,如果一个网站功能很多,我们要按照功能划分写多个 js 文件,那就要添加多个 <script src=""> 去引用这些 js 文件,还需要注意不同 js 文件之间的依赖关系,这一方面导致难以维护相关模块顺序,另一方面也增加了网页加载时的请求数量。
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.6/umd/popper.min.js" integrity="sha384-wHAiFfRlMFy6i5SRaxvfOCifBUQy1xHdJ/yoi7FRNXMRBu5WHdZYu1hA6ZOblgut" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.2.1/js/bootstrap.min.js" integrity="sha384-B0UglyR+jN6CkvvICOB2joaf5I4l3gm9GU6Hc1og6Ls7i6U/mkkaduKaBhlAXv9k" crossorigin="anonymous"></script>
备注:在最早的不基于任何前端现代库(React / Vue 等)的原生页面中,如果我们想快捷的搭建一套 b 端页面,bootstrap 是一个很好的选择,你只需要在 script 标签中引入对应库的 cdn 链接即可,然而由于 bootstrap 依赖于 jquery,我们必须把引入 jquery 的标签写在 bootstrap 的前面,不然就会导致报错。
模块化
如果代码都需要像上面说的那样写在标签里,那我们的开发节奏也太难受了!难道要手动粘贴多份代码到一个 js 文件?变量重名该怎么处理?先别急,请看下面:随着模块化方案:Commonjs、AMD、UMD、ESM 的出现,我们的代码组合方法变得多种多样,也变得更加灵活。
Commonjs:简称 cjs,是 nodejs 中默认采用的模块化规范 ,不能直接在浏览器中运行。模块为同步的运行时加载,同时导出变量为值拷贝。
const axios = require("axios");
AMD:模块异步加载,使用 requirejs 库后可在浏览器端和服务端运行,同时导出变量也为值拷贝。
var requirejs = require('requirejs');
requirejs.config({
paths: {
lib1: 'module/index1',
lib2: 'module/index2'
}
})
require(["lib1","lib2"], function(l1,l2) {
l1.doSomething();
l2.doSomething();
})
CMD:CMD 的基本逻辑跟 AMD 是一致的,需要使用sea.js库且 CMD 仅支持浏览器端使用。
<script src="https://cdn.duidaima.com/ajax/libs/seajs/3.0.3/sea.js"></script>
<script>
seajs.config({
base: './module/',
alias: {
libAMD: 'index.js',
}
})
seajs.use('./main.js')
</script>
// main.js
define(function(require) {
let libAMD = require("libAMD")
libAMD.doSomething()
})
ESM:ECMAscript 的模块化规范,该规范在浏览器端和服务端都得到了支持,在非 default 导出的情况下,导出变量为值的引用,否之亦为值的拷贝。
.编译时加载
.支持 tree-shaking
import { value, getValue, Obj, name } from "./module/index.js"
环境兼容
了解了上面所说的模块化,我们就可以依赖上述某一种规范进行各个模块开发,但是这不能让我们立刻开始愉快的“大写特写”。因为我们所使用的 ESM 模块系统本身就存在环境兼容问题。尽管现如今主流浏览器的最新版本都支持这一特性,但是在几年前的我们还无法忽略用户存在使用老版本浏览器的 case, 所以我们还需要考虑兼容问题。
同时,模块化的方式划分出来的模块文件过多,而前端应用又运行在浏览器中,每一个文件都需要单独从服务器请求回来。零散的模块文件必然会导致浏览器的频繁发送网络请求,由于上文所述的 http1.x 的能力局限性,进而会影响应用使用体验。随着应用日益复杂,在前端应用开发过程中不仅仅只有 JavaScript 代码需要模块化,HTML 和 CSS 这些资源文件也会面临需要被模块化的问题。 而且从宏观角度来看,这些文件也都应该看作前端应用中的一个模块,只不过这些模块的种类和用途跟 JavaScript 不同。
如果我们的应用能在开发阶段继续享受模块化带来的优势,又不被模块化对生产环境所产生的影响,这样就完美啦!所以打包这一节点出现在了研发环节之中。
打包时的额外工作
在打包时我们的打包工具往往还会通过一些插件(eg. Babel)帮我们做编译和代码混淆等工作:
ES6 -> ES5
TS -> JS
less / scss -> css
......
Webpack VS Rollup
我们的项目有可能是一个业务平台,也有可能是一个工具 SDK,这两种不同的类型的项目选择打包工具时也会有不同的选择。


webpack 打包处理后会把我们自己的代码放在最后面,由于编译结果过于长,就不在文档放编译完整结果了~
上面右图注入的大段代码都是 webpack 自己的兼容代码,目的是自己实现 require、modules.exports、export,让浏览器可以兼容 Commonjs 和 ESM 语法。 可以理解为,webpack 自己实现 polyfill 支持模块语法,rollup 是利用高版本浏览器原生支持 ESM,所以 rollup 无需代码注入。
总结:
业务平台:
如果是需要兼容老版本浏览器的场景,更加适合用 Webpack 进行打包,插件生态丰富,提供各种兼容性保障。
工具 SDK:
.更加适合用 Rollup 进行打包,打包内容结构纯净,无多余代码。
.并且 ESM 对打包工具来说更容易正确地进行 tree-shaking。
为什么要分包
性能优化的考虑
“天下大势分久必合,合久必分”
通过打包工具(eg.webpack)实现前端项目整体模块化的优势固然很明显,但是它同样存在一些弊端,那就是我们项目中的所有代码最终都被打包到了一起,如果我们应用非常复杂,模块非常多的话,我们的打包结果就会特别的大,进而导致我们的系统性能也会变差,首屏加载时间变长。
我们可以使用 webpack-bundle-analyzer 插件来进行打包分析,根据包产物结构图进行分解:
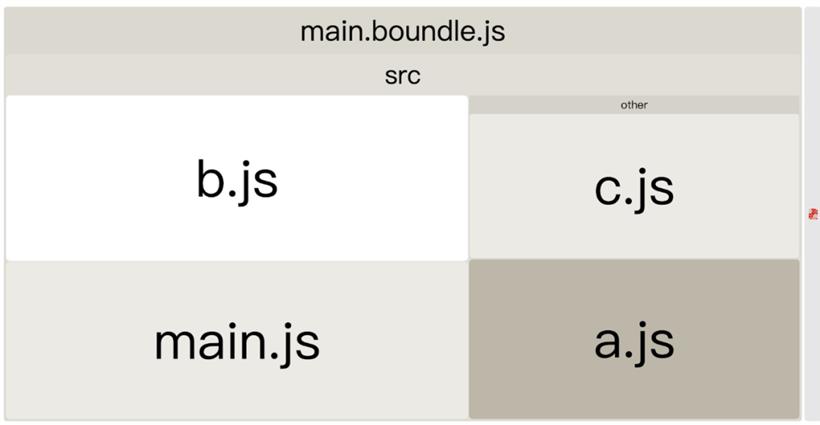
手动分包:将体积很小、改动很频繁的业务模块和体积很大、很少改动的第三方库分开打包,这样修改业务模块的代码不会导致第三方库的缓存失效。
自动分包:配置好分包策略后 webpack 每次都会自动完成分包的流程,webpack4 中支持了零配置的特性,同时对块打包也做了优化,CommonsChunkPlugin 已经被移除了,现在使用 optimization.splitChunks 作为 CommonsChunkPlugin 的代替。
为什么不打包
以下内容基于 Vite 3
 专注于开发体验
专注于开发体验
如果使用打包式构建,无论是项目启动还是文件变更,都需要完整的走一遍打包过程。 以 Webpack 为例,我们就会经历依赖分析、代码转译和打包的过程,哪怕我们只是简单的修改了一行文案。当然分包会在一定程度上缓解这一问题,但我们仍然需要对分包后的业务代码包也执行完整的打包流程。
当我们开始构建越来越大型的应用时,需要处理的 JavaScript 代码量也呈指数级增长。包含数千个模块的大型项目相当普遍。基于 JavaScript 开发的工具就会开始遇到性能瓶颈:通常需要很长时间才能启动开发服务器,即使使用模块热替换(HMR),文件修改后的效果也需要几秒钟才能在浏览器中反映出来。如此循环往复,每次几分钟的起步时间让开发者变得很痛苦。
bundleless 工具旨在利用生态系统中的新进展解决上述问题:浏览器更好的原生支持 ESM,且越来越多 JavaScript 工具使用编译型语言编写。
使用 bundleless 工具,我们不用对业务代码进行依赖分析、打包,ESM 会帮助我们在浏览器中完成依赖的分析。当文件发生变更时,本地开发服务只是提供了文件的映射,只需要重新转译对应的文件,并重新替换即可。
核心原理
我们声明一个 script标签类型为 module 时,如:
<script type="module" src="/src/main.tsx">
当浏览器解析资源时,会往当前域名发起一个GET请求main.js文件。
// main.js
import React from 'react'
import ReactDOM from 'react-dom/client'
import App from './App'
import './index.css'
ReactDOM.createRoot(document.getElementById('root') as HTMLElement).render(
<React.StrictMode>
<App />
</React.StrictMode>,
)
请求到了main.js文件,会检测到内部含有 import 引入的包,又会 import 引用发起 http 请求获取模块的内容文件。Vite 其核心原理是利用浏览器现在已经支持 ESM ,碰见 import 语句就会发送一个 http 请求去加载文件,vite 启动一个服务拦截这些请求,并在后端进行相应的处理,将为项目中的文件执行一些转换逻辑,然后再以 ESM 格式返回返回给浏览器。所以 vite 做到了真正的按需加载,所以其运行速度比原始的 webpack 打包编译速度快出许多。
tips :jsx-dev-runtime[3]:React 17 为编译器提供的 jsx to js 库,使用它你甚至不需要手动声明import React from 'react'
bundleless 是完全不进行打包吗?
🌟 答案是:NO
Vite 的开发服务器会将所有代码视为原生 ES 模块。因此,Vite 必须先将作为 CommonJS 或 UMD 格式的依赖项转换为 ESM。试想如果我们要使用import { debounce } from 'lodash-es',但是 debounce 函数又依赖了更多的其他模块,所以在 bundleless 场景下浏览器同时发出几百个 http 请求!尽管服务器在处理这些请求时没有问题,但大量的请求会在浏览器端造成网络拥塞,导致页面的加载速度相当慢。
所以对于较大的第三方依赖我们依然会进行打包(依赖预构建), 打包后我们使用debounce方法就只需要一个 http 请求了!
为什么不在生产环境使用?
尽管原生 ESM 现在得到了广泛支持,但由于嵌套导入会导致额外的网络往返,在生产环境中发布未打包的 ESM 仍然效率低下(即使使用 http2)。为了在生产环境中获得最佳的加载性能,最好还是将代码进行 tree-shaking、懒加载和 chunk 分割(以获得更好的缓存)—— vite 官网
其他问题:
用户的浏览器版本可能不支持 ESM / ECMAScript 新版本,使用 bundleless 导致缺失了一些 polyfill 的能力。
总结
为什么曾经需要打包:
1. http1.x 中浏览器的并行连接限制;
2. 浏览器原生不支持模块化(如 Commonjs 包不能直接在浏览器运行);
3. 项目依赖关系需要管理。
为什么打包后还需要分包:
1. 分包后浏览器可以缓存极少发生变化的第三方大依赖包,用户刷新页面时只请求频繁变动的业务代码包。
2.为什么我们现在可以使用 bundleless:
http2.0 支持多路复用;
各大浏览器对 ESM 的支持越来越完善,模块代码可以直接在浏览器中运行,也间接解决了依赖管理的问题。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





