一、什么是Big Key?
通俗易懂的讲,Big Key就是某个key对应的value很大,占用的redis空间很大,本质上是大value问题。key往往是程序可以自行设置的,value往往不受程序控制,因此可能导致value很大。redis中这些Big Key对应的value值很大,在序列化/反序列化过程中花费的时间很大,因此当我们操作Big Key时,通常比较耗时,这就可能导致redis发生阻塞,从而降低redis性能。
BigKey指以Key的大小和Key中成员的数量来综合判定,用几个实际的例子对大Key的特征进行描述:
1.Key本身的数据量过大:一个String类型的Key,它的值为5MB
2.Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10000个
3.Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1000个但这些成员的Value值总大小为100MB
在实际业务中,大Key的判定仍然需要根据Redis的实际使用场景、业务场景来进行综合判断。通常都会以数据大小与成员数量来判定。
二、Big Key产生的场景?
1、redis数据结构使用不恰当
将Redis用在并不适合其能力的场景,造成Key的value过大,如使用String类型的Key存放大体积二进制文件型数据。
2、未及时清理垃圾数据
没有对无效数据进行定期清理,造成如HASH类型Key中的成员持续不断的增加。即一直往value塞数据,却没有删除机制,value只会越来越大。
3、对业务预估不准确
业务上线前规划设计考虑不足没有对Key中的成员进行合理的拆分,造成个别Key中的成员数量过多。
4、明星、网红的粉丝列表、某条热点新闻的评论列表
假设我们使用List数据结构保存某个明星/网红的粉丝,或者保存热点新闻的评论列表,因为粉丝数量巨大,热点新闻因为点击率、评论数会很多,这样List集合中存放的元素就会很多,可能导致value过大,进而产生Big Key问题。
三、Big Key的危害?
1、阻塞请求
Big Key对应的value较大,我们对其进行读写的时候,需要耗费较长的时间,这样就可能阻塞后续的请求处理。Redis的核心线程是单线程,单线程中请求任务的处理是串行的,前面的任务完不成,后面的任务就处理不了。
2、内存增大
读取Big Key耗费的内存比正常Key会有所增大,如果不断变大,可能会引发OOM(内存溢出),或达到redis的最大内存maxmemory设置值引发写阻塞或重要Key被逐出。
3、阻塞网络
读取单value较大时会占用服务器网卡较多带宽,自身变慢的同时可能会影响该服务器上的其他Redis实例或者应用。
4、影响主从同步、主从切换
删除一个大Key造成主库较长时间的阻塞并引发同步中断或主从切换。
四、如何识别Big Key?
方法1、使用redis-cli 命令加上--bigkeys参数 识别
可以使用Redis官方客户端redis-cli加上--bigkeys参数,可以找到某个实例5种数据类型(String、hash、list、set、zset)的最大key。
优点:
可以在线扫描,不阻塞服务;
缺点
是信息较少,内容不够精确。
方法2、scan 扫描+ 长度命令
redis 老的版本,在没有scan之前,使用 key 进行扫描,新的redis版本,有了性能更好的 scan命令,利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断kev的长度,推荐scan 扫描,并且,我强烈建议大家,一定实操一下。
方法3、使用debug object key命令
根据传入的对象(Key的名称)来对Key进行分析并返回大量数据,其中serializedlength的值为该Key的序列化长度,需要注意的是,Key的序列化长度并不等同于它在内存空间中的真实长度,此外,debug object属于调试命令,运行代价较大,此命令是阻塞式的,在其运行时,进入Redis的其余请求将会被阻塞直到其执行完毕。
并且每次只能查找单个key的信息,官方不推荐使用。
方法4、redis-rdb-tools开源工具
这种方式是在redis实例上执行bgsave,bgsave会触发redis的快照备份,生成rdb持久化文件,然后对dump出来的rdb文件进行分析,找到其中的大key。
GitHub地址:
https://github.com/sripathikrishnan/redis-rdb-tools
优点
1.获取的key信息详细、可选参数多、支持定制化需求
2.结果信息可选择json或csv格式,后续处理方便,
缺点
1.是需要离线操作,获取结果时间较长。
五:实操一下,使用 keys 命令进行 扫描
redis 老的版本,在没有scan之前,使用 key 进行扫描,新的redis版本,有了性能更好的 scan命令,利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断kev的长度,虽然推荐scan 扫描,并且,我强烈建议大家,一定实操一下。但是 知己知彼,一定要把过时的技术,体验一下。
客户端连接 redis
docker exec -it redis-standalone redis-cli
auth 123456
Keys 命令的使用实操
KEYS命令使用很简单, redis KEYS 命令基本语法如下:
KEYS PATTERN
eg ,查找以 store: 为开头的 key:
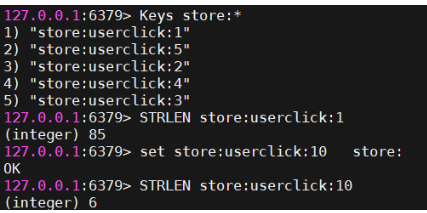 key命令的性能问题
key命令的性能问题
keys * 这个命令千万别在生产环境乱用。特别是数据庞大的情况下。因为Keys会引发Redis锁,并且增加Redis的CPU占用。很多公司的运维都是禁止了这个命令的当需要扫描key,匹配出自己需要的key时,可以使用 scan 命令。
Redis字符串命令
|
命令
|
说明
|
|
SET key value
|
用于设定指定键的值。
|
|
GET key
|
用于检索指定键的值。
|
|
GETRANGE key start end
|
返回 key 中字符串值的子字符。
|
|
GETSET key value
|
将给定 key 的值设置为 value,并返回 key 的旧值。
|
|
GETBIT key offset
|
对 key 所存储的字符串值,获取其指定偏移量上的位(bit)。
|
|
MGET key1 [key2..]
|
批量获取一个或多个 key 所存储的值,减少网络耗时开销。
|
|
SETBIT key offset value
|
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
|
|
SETEX key seconds value
|
将值 value 存储到 key中 ,并将 key 的过期时间设为 seconds (以秒为单位)。
|
|
SETNX key value
|
当 key 不存在时设置 key 的值。
|
|
SETRANGE key offset value
|
从偏移量 offset 开始,使用指定的 value 覆盖的 key 所存储的部分字符串值。
|
|
STRLEN key
|
返回 key 所储存的字符串值的长度。
|
|
MSET key value [key value ...]
|
该命令允许同时设置多个键值对。
|
|
MSETNX key value [key value ...]
|
当指定的 key 都不存在时,用于设置多个键值对。
|
|
PSETEX key milliseconds value
|
此命令用于设置 key 的值和有过期时间(以毫秒为单位)。
|
|
INCR key
|
将 key 所存储的整数值加 1。
|
|
INCRBY key increment
|
将 key 所储存的值加上给定的递增值(increment)。
|
|
INCRBYFLOAT key increment
|
将 key 所储存的值加上指定的浮点递增值(increment)。
|
|
DECR key
|
将 key 所存储的整数值减 1。
|
|
DECRBY key decrement
|
将 key 所储存的值减去给定的递减值(decrement)。
|
|
APPEND key value
|
该命令将 value 追加到 key 所存储值的末尾。
|
Redis string 的命令只能一次设置/查询一个键值对,这样虽然简单,但是效率不高。为了提高命令的执行效率,Redis 提供了可以批量操作多个字符串的读写命令 MSET/MGET(“M”代表“Many”),它们允许你一次性设置或查询多个键值对,这样就有效地减少了网络耗时。
嘚瑟一下底层知识:Redis字符串的内部大小
Redis 使用标准 C 语言编写,但在存储字符时,Redis 并未使用 C 语言的字符类型,为了存储字符串,Redis 自定义了一个属于特殊结构 SDS(Simple Dynamic String)即简单动态字符串),SDS 是一个可以修改的内部结构,非常类似于 Java 的 ArrayList。
1. SDS动态字符串
SDS 的结构定义如下:
struct sdshdr{
//堆代码 duidaima.com
//记录buf数组中已使用字符的数量,等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用的字符数量
int free;
//字符数组,用于保存字符串
char buf[];
从上述结构体可以看出,Redis string 将字符串存储到字符类型的buf[] 、len、free
2. 分配冗余空间
string 采用了预先分配冗余空间的方式来减少内存的频繁分配,如下图所示:
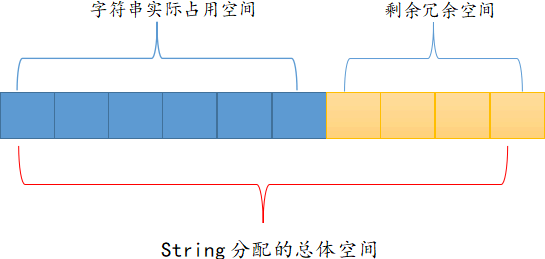
如图 所示,Redis 每次给 string 分配的空间都要大于字符串实际占用的空间,这样就在一定程度上提升了 Redis string 存储的效率,比如当字符串长度变大时,无需再重新申请内存空间。
当字符串所占空间小于 1MB 时,Redis 对字符串存储空间的扩容是以成倍的方式增加的;而当所占空间超过 1MB 时,每次扩容只增加 1MB。Redis 字符串允许的最大值字节数是 512 MB。
六:实操一下,使用SCAN命令进行 扫描
scan命令和keys命令的对比
在巨大的数据量的状况下,作查找符合某种规则的Key的信息,这里就有两种方式:java
1. keys命令:
简单粗暴,可是因为Redis是单线程,keys命令是以阻塞的方式执行的,keys是以遍历的方式实现的复杂度是 O(n),Redis库中的key越多,查找实现代价越大,产生的阻塞时间越长。
2. scan命令:
以非阻塞的方式实现key值的查找,绝大多数状况下是能够替代keys命令的,可选性更强
基于SCAN的这种安全性,建议大家在生产环境都使用SCAN命令来代替KEYS,不过注意,该命令是在2.8.0版本之后加入的,如果你的Redis低于这个版本,则需要升级Redis。
1. scan相关命令
都是用于增量迭代集合元素。正则表达式。
SCAN 命令用于迭代当前数据库中的数据库键。
SSCAN 命令用于迭代集合键中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
以后的例子会以sscan为例redis
2. 命令参数
SCAN 每次执行都只会返回少量元素,所以可以用于生产环境,而不会出现像 KEYS 或者 SMEMBERS 命令带来的可能会阻塞服务器的问题。
SCAN命令是一个基于游标的迭代器。redis Scan 命令基本语法如下:
SCAN cursor [MATCH pattern] [COUNT count]
cursor - 游标。
pattern - 匹配的模式。
count - 可选,用于指定每次迭代返回的 key 的数量,默认值为 10 。
pattern 参数进行样式的模糊匹配,是一个 glob 风格的模式参数,让命令只返回和给定模式相匹配的元素。比如
SCAN 0 match store:* count 2
每次被调用scan, 都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程;当SCAN命令的游标参数(即cursor)被设置为 0 时,redis将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
redis-cli 的使用SCAN演示:
现在有 7 个key,使用scan 扫描,每次 2个

扫描过程如下, 注意游标的 编号,不是有序的
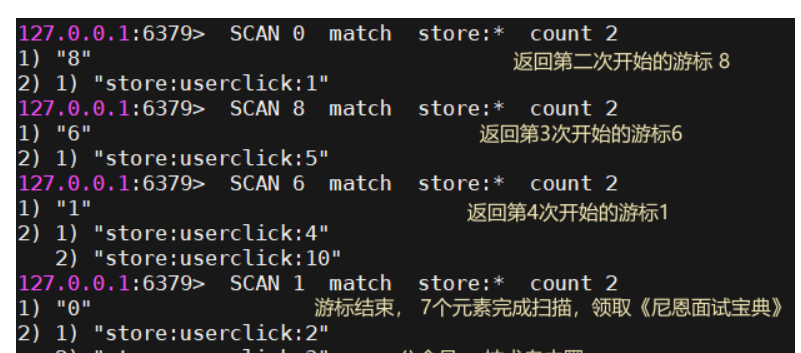
在上面这个例子中, 第一次迭代使用 0 作为游标, 表示开始一次新的迭代。
第二次迭代使用的是第一次迭代时返回的游标8,作为新的迭代参数 。显而易见,SCAN命令的返回值, 是一个包含两个元素的数组:第一个数组元素是用于进行下一次迭代的新游标,而第二个数组元素则又是一个数组, 这个数组中包含了所有被迭代的元素。
一次scan full iteration(完全迭代) 的过程如下:
以 0 作为游标开始一次新的迭代, 一直调用 SCAN 命令, 直到命令返回游标 0 , 我们称这个过程为一次完整遍历。
注意两点:
1.返回的游标不一定是递增的,可能后一次返回的游标比前一次的小。
2.SCAN增量式迭代命令并不保证每次执行都返回某个给定数量的元素,甚至可能会返回零个元素, 但只要命令返回的游标不是 0 , 应用程序就不应该将迭代视作结束。
在最后一次调用 SCAN 命令时, 命令返回了游标 0 , 这表示迭代已经结束, 整个数据集已经被完整遍历过了。
七、SpringBoot BigKey的scan扫描实操
SpringBoot 应用中,可是经过用scan,咱们就能够指定有共性的key,并指定一次性查询条件。
演示的代码如下:
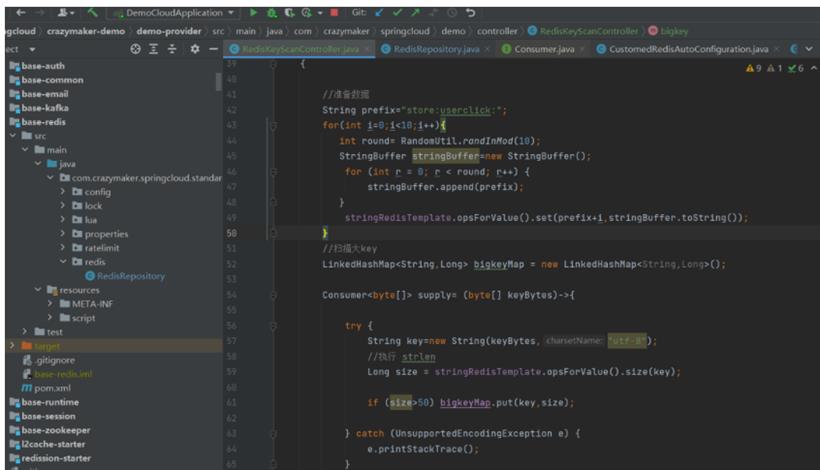
这里例子中,是 以 大于 50个字节,就计算为 bigkey.这个阈值,仅仅是为了演示方便,生产场景,可以设置一个大的阈值,比如,一个String类型的Key,它的阈值为5MB
执行的结果
启动应用,可以得到执行的结果
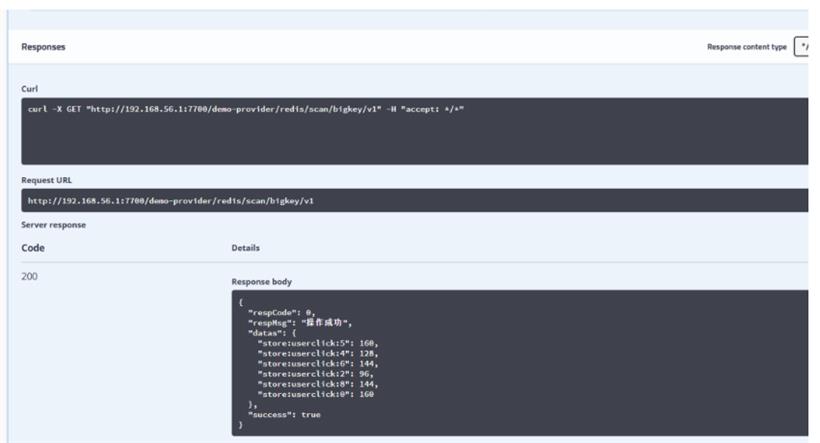
实验完美成功
生产场景的bigkey 扫描
结合scan + 定时任务的方式, 在 吞吐量的低峰期,进行扫描。发现了bigkey, 可以及时的进行 运维 告警, 发送 邮件通知或者 钉钉企业信息。
类似场景,对大量key进行扫描的集群
在线上有时候,须要对大量key进行扫描(如删除)操做,有几个风险点:
1.一次性查询所指定的key
如果是使用keys,数量较大可能形成redis服务卡顿,Redis是单线程程序,顺序执行全部指令,其它指令必须等到当前的 keys 指令执行完了才能够继续。
2.从海量的 key 中找出知足特定前缀的 key
上面的场景中,都可以用scan,咱们就能够指定有共性的key,并指定一次性查询条件。
要点是:使用SCAN命令扫描key替代KEYS避免redis服务器阻塞,无坑!
八、如何解决Big Key问题?
要解决Big Key问题,无非就是减小key对应的value值的大小,也就是对于String数据结构的话,减少存储的字符串的长度;对于List、Hash、Set、ZSet数据结构则是减少集合中元素的个数。
1、对大Key进行拆分
将一个Big Key拆分为多个key-value这样的小Key,并确保每个key的成员数量或者大小在合理范围内,然后再进行存储,通过get不同的key或者使用mget批量获取。
2、对大Key进行清理
对Redis中的大Key进行清理,从Redis中删除此类数据。
Redis自4.0起提供了UNLINK命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的Key,
通过UNLINK,你可以安全的删除大Key甚至特大Key。
3、监控Redis的内存、网络带宽、超时等指标
通过监控系统并设置合理的Redis内存报警阈值来提醒我们此时可能有大Key正在产生,如:Redis内存使用率超过70%,Redis内存1小时内增长率超过20%等。
4、定期清理失效数据
如果某个Key有业务不断以增量方式写入大量的数据,并且忽略了其时效性,这样会导致大量的失效数据堆积。
可以通过定时任务的方式,对失效数据进行清理。
5、压缩value
使用序列化、压缩算法将key的大小控制在合理范围内,但是需要注意序列化、反序列化都会带来一定的消耗。
如果压缩后,value还是很大,那么可以进一步对key进行拆分。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






