前言
Redis 是一个高性能的 key-value 数据库,由于其易用、性能高、扩展性好等特点,已经成为后端内存数据库的业界标准。使用 Redis 进行日常开发时,最常使用的数据结构应当是 String,但 String 也不是"万金油",使用不当也会造成很多内存上的浪费。本文会解析 String 数据是如何保存的,并分析其占用内存的原因,以及说明如何减少内存的使用。
为什么 String 类型内存开销大
String 类型的内存空间消耗
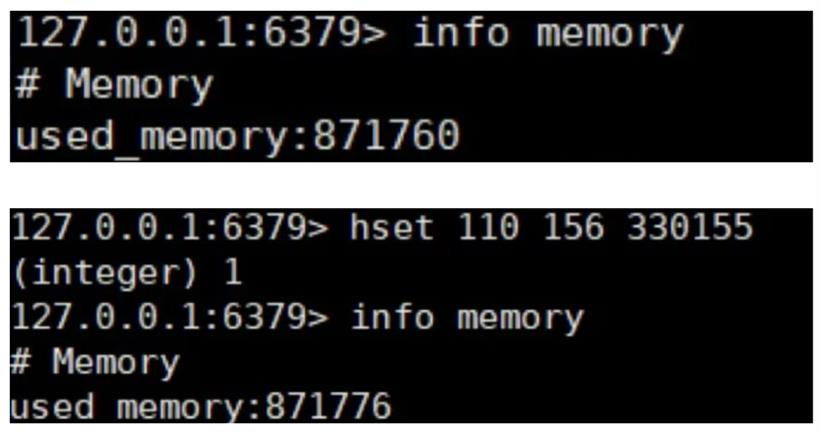
正常情况下,一个 int 类型的数据需要占用 4 个字节的内存空间,而保存一个 key-value 键值对数据则需要 8 个字节的内存空间,但在 redis 中保存键为:110156,值为:330155 的键值对时却用了 48 个字节的内存空间。如下图所示:
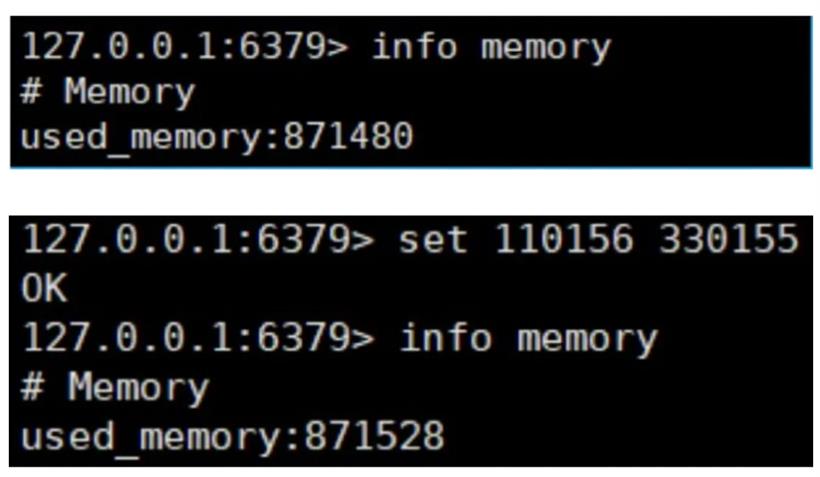
实际上,当 redis 保存一个 String 类型的数据的时候,除了数据本身外还需要额外的内存空间记录数据长度、空间等使用信息,这些信息也叫做元数据。当需要存储这类纯数字的 key-value 键值对的时候,元数据信息占用的空间就会比本身需要存储的数据更多,所以 String 类型并不适合存储空间较小的数据。那么 String 的底层结构又是怎么存储的呢?
简单动态字符串
Redis 中没有直接使用 C语言的字符串,而是自己构建了一种名为简单动态字符串(Simple Dynamic String,SDS)的抽象类型。其好处有:
1.常数复杂度获取字符串长度:C语言中的字符串并未记录字符串长度需要遍历去获取。SDS 记录本身字符串的一个长度,所以可以直接获取。
2.杜绝缓冲区溢出:C语言字符串本身不记录长度,导致有可能修改字符串内容时,内存溢出到下一个字符串的内存空间。而 SDS 会进行自动扩容。
3.减少修改字符串时带来的内存重分配的次数: C语言字符串在修改字符串长度时需要频繁的变换。
整体结构如下图所示
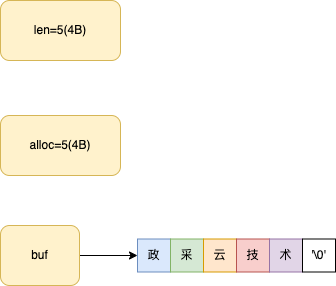 buf
buf :字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个"/0"。
len:表示 buf 的已用长度,占用 4 个字节。
alloc:表示 buf 的实际分配长度,占用 4 个字节。
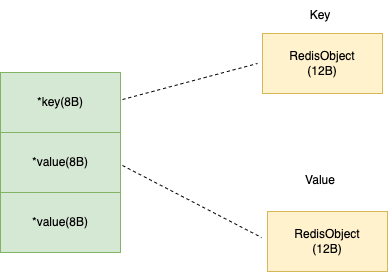
SDS 相比较原先的 C 语言字符串,更加易用,但是带来的代价就是占用了更多的内存空间。除了 SDS 结构的内存空间损耗外,Redis 对每个保存的数据都使用了一个叫做 RedisObject 的结构体来统一记录对应数据的元数据。元数据中记录了最后一次访问的时间、被引用的次数等。每个 RedisObject 指向实际的数据,结构如下图所示:
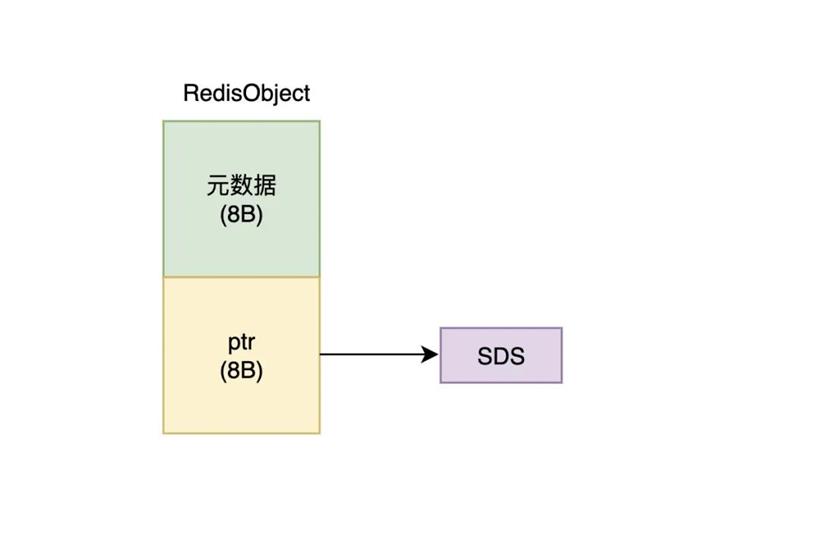
可以看到一个 RedisObject 包含了一个 8 字节的元数据和 8 个字节的指针。但为了进一步节省内存空间,Redis 还对整数类型的数据和 SDS 的内存布局做了专门的设计,对不同大小的数据使用了不同的编码模式。
字符串的三种编码方式
为了节省空间 Redis 还专门对不同类型的字符串数据做了不同的处理,并称之为三种不同的编码模式,即 int 编码、embstr 编码、raw 编码。如图所示:
int编码:当保存的是整数时,RedisObject 中的指针就直接赋值为整数了,节省了指针的开销。
embstr 编码:当要保存的字符串小于 44 字节时,RedisObject 和 SDS 是一块连续的区域,避免内存碎片。
raw 编码:当要保存的字符串大于 44 字节时,SDS 的数据量变多,会给 SDS 独立的分配内存空间,然后用指针指向 SDS。
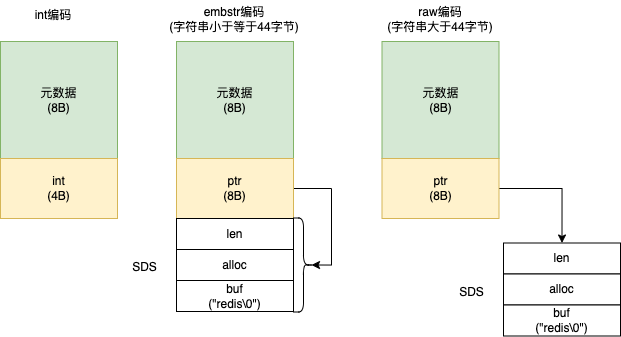
可以看到当我们保存一个整数的 key-value 键值对的时候,实际使用了 12 字节。但是我们看到的例子中使用了 48 个字节,剩下的 36 个字节被什么消耗了呢?
全局哈希表
实际上,Redis 会使用一个全局的哈希表保存所有的键值对,使用全局哈希表最大的好处就是可以用O(1)的时间复杂度来快速查找到键值对。全局的哈希表构造如下:
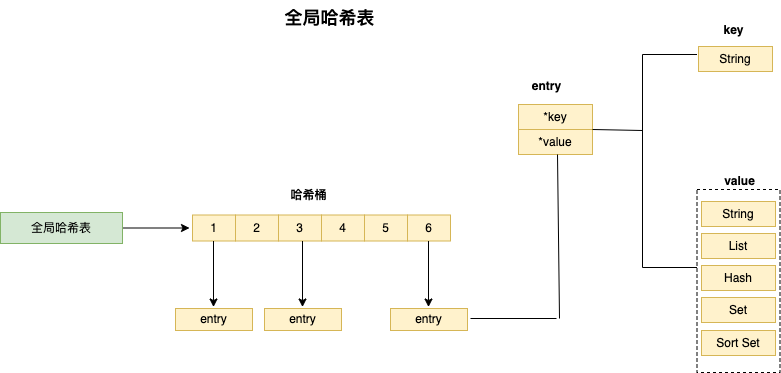
Redis 会使用一个全局的哈希表保存所有的键值对,哈希表的每一项是一个 Entry ,一个 Enrty 中有三个指针,分别用于指向 key、value 和下一个 Entry,每个对象分别占用 8 个指针,总共占用 24 个字节。如图所示:
而用了 32 个字节的原因在于 Redis 使用的内存分配库 jemalloc,jemalloc 在分配内存时,会根据申请的字节数 N,找一个比 N 大,但是最接近 N² 的幂次数作为空间。所以申请了 24 字节,则最终会分配 32 个字节。
由此可见,有效的信息只占用 12 个字节,但是却需要 48 个字节。那么如果有一亿个这样的数据的话,就需要 4.8 个 GB 的空间,额外空间的损耗是 3.2 个GB。内存占用过大,需要有一种更加节省内存空间的存储方式
更加节省内存的数据结构
在 redis 中有一种数据结构叫做压缩列表( ziplist ),这种数据结构可以更加的节省内存。压缩列表的表头部分由 zlbytes、zltail 和 zllen 组成,分别标识列表长度、列表尾的偏移量。表的中间部分是 entry ,表示保存实际的数据。表结尾是 zlend,表示列表的结束。结构如下图所示:

entry 是连续的,不用额外的指针进行连接,这样节省了指针所占用的空间。每个 entry 的数据包含:
len:表示自身长度,4字节。
content:保存实际数据。
每个 entry 保存一个图片存储对象 ID 在 int 范围内( 4 字节),记录自身长度 len 需要 4 个字节,所以 key 加上value 占用的字节应该是(4+4)*2 = 16 字节。可以看到相比于使用 String 一次占用 48 个字节,使用压缩列表的方式只用了 16 个字节,节省了 32 个字节,这大数据量的情况下能节省不少内存空间。
Redis 基于压缩列表实现了 Hash、List、 Sortd Set 等集合类型。那么如何利用压缩列表来保存非集合类型的数据?
用集合类型保存单值的键值对
如果是单值的键值对,可以采用基于 Hash 类型的二级编码方法。比如把一个单值的数据拆成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value。
例如对于要存储 key:110156,value:330155 的数据,可以将 110 作为 Hash 的键将 "156" 和 "330155" 分别作为 Hash 类型值中的 key 和 value ,实际只使用了 16 字节,如下图所示:
但实际上 Hash 底层数据在超过某个阈值的时候,就由压缩列表转换为了哈希表,所以说其中存储的数字长度也十分有讲究。控制这个阈值的由下面两个 Redis 配置参数来控制:
hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
使用压缩列表的时候,如果像例子中的保存的数值是三位数的数字,那么也就保证了 Hash 集合的元素的个数不会超过 1000,所以我们设置 hash-max-ziplist-entries 值为 1000,这样一来就可以使用压缩列表来节省内存空间了。
小结
本次主要介绍了 redis 在内存中使用的是简单动态字符串( SDS ),以及它的三种编码方式,还有它耗费内存的原因在于 RedisObject 和本身 SDS 的结构。我们可以使用压缩列表来节省内存,剖析了其节省内存的原因。并使用 Hash的数据结构给出了实际的节省内存的案例,大家可以根据实际的业务,合理的设计缓存的存储结构,达到节省内存的目的。这里可以推荐一个网址可以用来大致计算 Redis 的内存损耗redis内存损耗计算


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





