

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

5.如何处理 bigkey?
非字符串类型:哈希、列表、集合、有序集合,元素超过 5000 个。
备份和恢复困难:当 Redis 需要进行备份和恢复时,bigkey 也会成为一个问题,因为备份和恢复需要占用大量的磁盘空间和网络带宽,如果存在大量的 bigkey,备份和恢复的过程可能会非常耗时和困难。
$ redis-cli --bigkeys # Scanning the entire keyspace to find biggest keys as well as # average sizes per key type. You can use -i 0.01 to sleep 0.01 sec # per SCAN command (not usually needed). [00.00%] Biggest string found so far 'key-419' with 3 bytes [05.14%] Biggest list found so far 'mylist' with 100004 items [35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes [73.91%] Biggest hash found so far 'myobject' with 3 fields -------- summary ------- Sampled 506 keys in the keyspace! Total key length in bytes is 3452 (avg len 6.82) Biggest string found 'counter:__rand_int__' has 6 bytes Biggest list found 'mylist' has 100004 items Biggest hash found 'myobject' has 3 fields 504 strings with 1403 bytes (99.60% of keys, avg size 2.78) 1 lists with 100004 items (00.20% of keys, avg size 100004.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 1 hashs with 3 fields (00.20% of keys, avg size 3.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00)不过需要注意,执行 --bigkeys 时,是通过扫描数据库来查找 bigkey,所以会对 Redis 实例的性能产生影响。
# redis-cli 会没扫描 100 次暂停 0.1 秒 ./redis-cli --bigkeys -i 0.1使用 redis-cli --bigkey 不足:
2.对于集合类型来说,只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大。
#SCAN cursor [MATCH pattern] [COUNT count]
#cursor - 游标。
#pattern - 匹配的模式。
#count - 可选,用于指定每次迭代返回的 key 的数量,默认值为 10 。
redis 127.0.0.1:6379> scan 0 # 使用 0 作为游标,开始新的迭代
1) "17" # 第一次迭代时返回的游标
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17 # 使用的是第一次迭代时返回的游标 17 开始新的迭代
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
2.通过 TYPE 命令判断 key 的类型。redis> SET weather "sunny" OK redis> TYPE weather string3.根据 key 类型,统计 value 大小
> STRLEN 22de5ac4e8074ff4bf03d777850de62c 640b. 集合类型:如果已知元素大小,乘上元素个数就是占用内存大小。
# List redis 127.0.0.1:6379> LLEN list1 (integer) 2 # Hash redis 127.0.0.1:6379> HLEN myhash (integer) 2 # Set redis 127.0.0.1:6379> SCARD myset (integer) 2 # Sorted Set redis 127.0.0.1:6379> ZCARD myzset (integer) 2 c. 未知可以通过 memory usage memory usage 0188a87272cb4558905b0cfbe64a30d6 16242.分析 RDB 文件
set hello redis save找到 dump.rdb 文件,并执行下面命令
od -A x -t x1c -v dump.rdb
000000 52 45 44 49 53 30 30 30 39 fa 09 72 65 64 69 73
R E D I S 0 0 0 9 372 \t r e d i s
000010 2d 76 65 72 05 35 2e 30 2e 37 fa 0a 72 65 64 69
- v e r 005 5 . 0 . 7 372 \n r e d i
000020 73 2d 62 69 74 73 c0 40 fa 05 63 74 69 6d 65 c2
s - b i t s 300 @ 372 005 c t i m e 302
000030 12 ff 54 64 fa 08 75 73 65 64 2d 6d 65 6d c2 c8
022 377 T d 372 \b u s e d - m e m 302 310
000040 bb 0d 00 fa 0c 61 6f 66 2d 70 72 65 61 6d 62 6c
273 \r \0 372 \f a o f - p r e a m b l
000050 65 c0 00 fe 00 fb 01 00 00 05 68 65 6c 6c 6f 05
e 300 \0 376 \0 373 001 \0 \0 005 h e l l o 005
000060 72 65 64 69 73 ff db 4d 64 00 c2 0b 2d 8d
r e d i s 377 333 M d \0 302 \v - 215
00006e
一个 RDB 主要是有三部分组成:
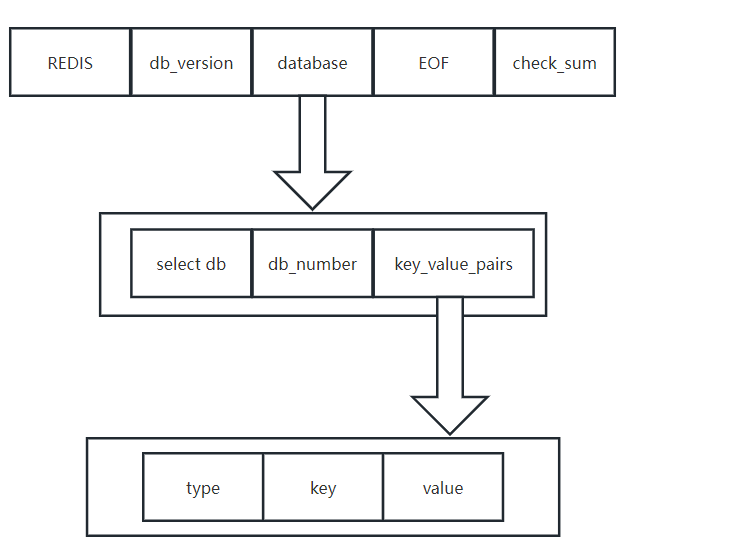
# 0 = "String Encoding" # 1 = "List Encoding" # 2 = "Set Encoding" # 3 = "Sorted Set Encoding" # 4 = "Hash Encoding" # 9 = "Zipmap Encoding" # 10 = "Ziplist Encoding" # 11 = "Intset Encoding" # 12 = "Sorted Set in Ziplist Encoding" # 13 = "Hashmap in Ziplist Encoding"这里 type 常量都代表了一种对象类型或底层编码,当服务器读入 RDB 文件中键值对数据,程序会根据 type 的来决定如何读入和解释 value。
rdb --command json dump.rdb
[{"hello":"redis"}]
有了 json 数据之后,我们就可以方法对 Redis 的数据进行统计和监控,也不会对 Redis Server 产生影响。



