

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

今年真是,各大中小厂都在如火如荼的降本增效的进行中,我司也不是例外,服务器成本的控制,数量的减少,不得不让我们对数据的存储方式进行优化,在面对大数据的应用下更是如此,笔者将分享下我们接近亿级用户相关Redis存储的优化过程。
目前我们用户标签与风控系统会给每个用户打标签以及计算每个用户在不同业务方风控场景下的风险分数和风险等级,即每个用户会对应多个标签,以及多个场景的风险分数和风险等级。我们每晚的全量服务是要跑9000多万个用户的信息,而这些用户的标签和场景下的风险分数和风险等级我们都需要存储到Redis中,当随着Redis内存占用的越来越多,为了能够存储更多的数据,我们就需要对它进行瘦身了,接下来一起看看标签的压缩存储吧。

我们就按平均10个标签来计算,也就是说一个用户标签占用为:3 + 6 * 10= 63byte,所用用户占的总内存为:63 * 90000000 / 1000 / 1024 / 1024=5.4G
由于我们标签code的设计是连续的,而且结构都是Tag+code,所以我们只需要记下用户有哪些code就可以了。因此我们想到了使用BitMap的结构来存储,把用户拥有的标签code对应的BitMap的索引位置为1即可,比如用户有Tag001,Tag005这两个标签,那么在Redis的存储就是:01000100,占用一个字节。
public static byte[] convertBitArrayToByteArray(BitSet bitArray) {
int numOfBytes = bitArray.length() / 8;
if (bitArray.length() % 8 != 0) {
numOfBytes++;
}
// 堆代码 duidaima.com
byte[] byteArray = new byte[numOfBytes];
int byteIndex = 0;
int bitIndex = 0;
for (int i = 0; i < bitArray.length(); i++) {
if (bitArray.get(i)) {
byteArray[byteIndex] |= (byte) (1 << (7 - bitIndex));
}
bitIndex++;
if (bitIndex == 8) {
byteIndex++;
bitIndex = 0;
}
}
return byteArray;
}
解码public static BitSet convertByteArrayToBitArray(byte[] byteArray) {
BitSet bitSet = new BitSet(byteArray.length * 8);
for (int byteIndex = 0; byteIndex < byteArray.length; byteIndex++) {
byte currentByte = byteArray[byteIndex];
for (int bitIndex = 0; bitIndex < 8; bitIndex++) {
boolean bit = ((currentByte >> (7 - bitIndex)) & 1) == 1;
bitSet.set(byteIndex * 8 + bitIndex, bit);
}
}
return bitSet;
}
压缩的成效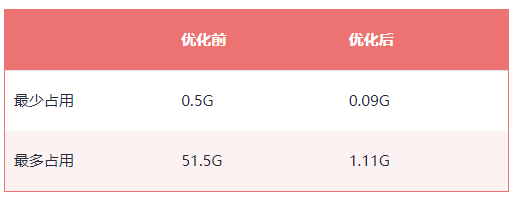
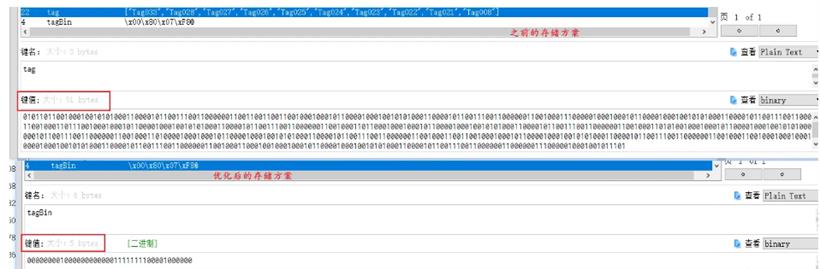
上面的优化还是存在着不足的,不知道你想到了没有:那就是当随着标签量的增多,如果当用户拥有的标签是很稀疏的,比如在一个很大的是Tag160,这样就会即使用户只有一个标签也会使用20byte来存储,而不压缩存储只需要6byte,会有很多空间的浪费,对于这种的不足,我们又有什么样的解决方案呢?游程编码(Run-Length Encoding)是一种常用的解决方案,其中做的较好的是RoaringBitMap兼容了逻辑操作和存储的多方面高性能,关于稀疏位图这一问题的解决我们后续再细细道来。





