

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

userPin:{
storeId:{门店下加车的所有商品基本信息},
storeId:{门店下加车的所有商品基本信息},
......
}
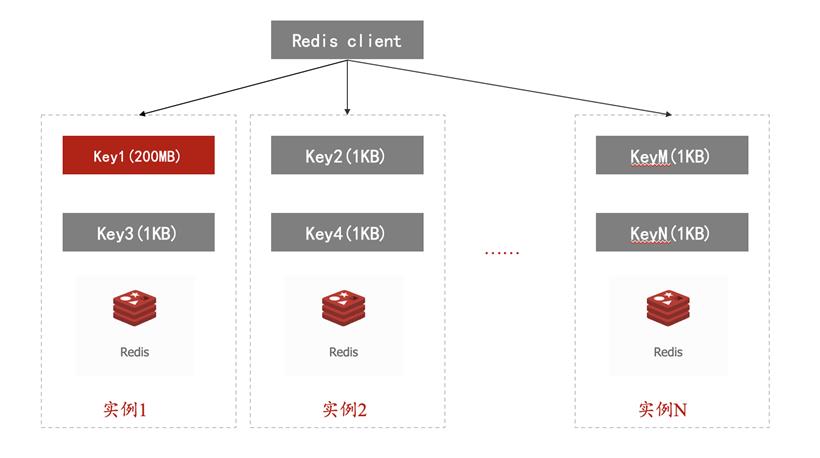
集群中Key的总数超过1亿
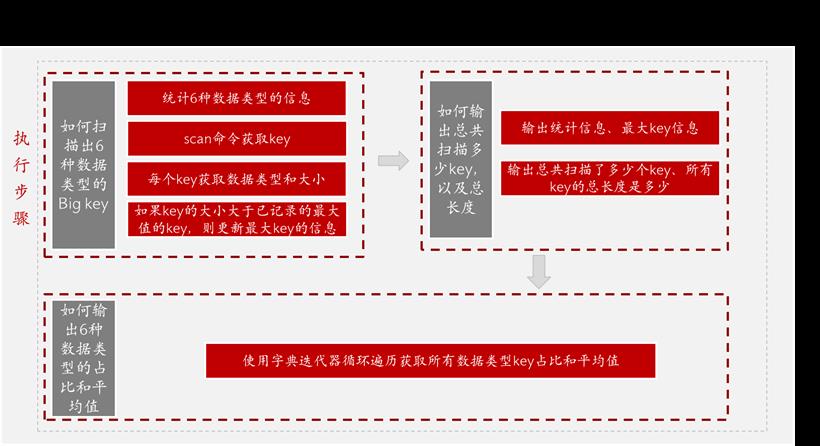
$ redis-cli --bigkeys # Scanning the entire keyspace to find biggest keys as well as # average sizes per key type. You can use -i 0.01 to sleep 0.01 sec # per SCAN command (not usually needed). -------- 第一部分start ------- [00.00%] Biggest string found so far 'key-419' with 3 bytes [05.14%] Biggest list found so far 'mylist' with 100004 items [35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes [73.91%] Biggest hash found so far 'myobject' with 3 fields -------- 第一部分end ------- -------- summary ------- -------- 第二部分start ------- Sampled 506 keys in the keyspace! Total key length in bytes is 3452 (avg len 6.82) Biggest string found 'counter:__rand_int__' has 6 bytes Biggest list found 'mylist' has 100004 items Biggest hash found 'myobject' has 3 fields -------- 第二部分end ------- -------- 堆代码 duidaima.com ----- -------- 第三部分start ------- 504 strings with 1403 bytes (99.60% of keys, avg size 2.78) 1 lists with 100004 items (00.20% of keys, avg size 100004.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 1 hashs with 3 fields (00.20% of keys, avg size 3.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00) -------- 第三部分end -------
typedef struct {
char *name;//数据类型,如string
char *sizecmd;//查询大小命令,如string会调用STRLEN
char *sizeunit;//单位,string类型为bytes,而hash为field
unsigned long long biggest;//最大key信息域,此数据类型最大key的大小,如string类型是多少bytes,hash为多少field
unsigned long long count;//统计信息域,此数据类型的key的总数
unsigned long long totalsize;//统计信息域,此数据类型的key的总大小,如string类型是全部string总共多少bytes,hash为全部hash总共多少field
sds biggest_key;//最大key信息域,此数据类型最大key的键名,之所以在数据结构末尾是考虑字节对齐
} typeinfo;
dict *types_dict = dictCreate(&typeinfoDictType);
typeinfo_add(types_dict, "string", &type_string);
typeinfo_add(types_dict, "list", &type_list);
typeinfo_add(types_dict, "set", &type_set);
typeinfo_add(types_dict, "hash", &type_hash);
typeinfo_add(types_dict, "zset", &type_zset);
typeinfo_add(types_dict, "stream", &type_stream);
2.调用scan命令迭代地获取一批key(注意只是key的名称,类型和大小scan命令不返回)/* scan循环扫描 */
do {
/* 计算完成的百分比情况 */
pct = 100 * (double)sampled/total_keys;//这里记录下扫描的进度
/* 获取一些键并指向键数组 */
reply = sendScan(&it);//这里发送SCAN命令,结果保存在reply中
keys = reply->element[1];//keys来保存这次scan获取的所有键名,注意只是键名,每个键的数据类型是不知道的。
......
} while(it != 0);
3.对每个key获取它的数据类型(type)和key的大小(size)/* 检索类型,然后检索大小*/ getKeyTypes(types_dict, keys, types); getKeySizes(keys, types, sizes, memkeys, memkeys_samples);4.如果key的大小大于已记录的最大值的key,则更新最大key的信息
/* Now update our stats */
for(i=0;i<keys->elements;i++) {
......//前面已解析
//如果遍历到比记录值更大的key时
if(type->biggest<sizes[i]) {
/* Keep track of biggest key name for this type */
if (type->biggest_key)
sdsfree(type->biggest_key);
//更新最大key的键名
type->biggest_key = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len);
if(!type->biggest_key) {
fprintf(stderr, "Failed to allocate memory for key!\n");
exit(1);
}
//每当找到一个更大的key时则输出该key信息
printf(
"[%05.2f%%] Biggest %-6s found so far '%s' with %llu %s\n",
pct, type->name, type->biggest_key, sizes[i],
!memkeys? type->sizeunit: "bytes");
/* Keep track of the biggest size for this type */
//更新最大key的大小
type->biggest = sizes[i];
}
......//前面已解析
}
5.对每个key更新对应数据类型的统计信息/* 现在更新统计数据 */
for(i=0;i<keys->elements;i++) {
typeinfo *type = types[i];
/* 跳过在SCAN和TYPE之间消失的键 */
if(!type)
continue;
//对每个key更新每种数据类型的统计信息
type->totalsize += sizes[i];//某数据类型(如string)的总大小增加
type->count++;//某数据类型的key数量增加
totlen += keys->element[i]->len;//totlen不针对某个具体数据类型,将所有key的键名的长度进行统计,注意只统计键名长度。
sampled++;//已经遍历的key数量
......//后续解析
/* 更新整体进度 */
if(sampled % 1000000 == 0) {
printf("[%05.2f%%] Sampled %llu keys so far\n", pct, sampled);
}
}
/* We're done */
printf("\n-------- summary -------\n\n");
if (force_cancel_loop) printf("[%05.2f%%] ", pct);
printf("Sampled %llu keys in the keyspace!\n", sampled);
printf("Total key length in bytes is %llu (avg len %.2f)\n\n",
totlen, totlen ? (double)totlen/sampled : 0);
2.首先输出总共扫描了多少个key、所有key的总长度是多少。/* Output the biggest keys we found, for types we did find */
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
if(type->biggest_key) {
printf("Biggest %6s found '%s' has %llu %s\n", type->name, type->biggest_key,
type->biggest, !memkeys? type->sizeunit: "bytes");
}
}
dictReleaseIterator(di);
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
printf("%llu %ss with %llu %s (%05.2f%% of keys, avg size %.2f)\n",
type->count, type->name, type->totalsize, !memkeys? type->sizeunit: "bytes",
sampled ? 100 * (double)type->count/sampled : 0,
type->count ? (double)type->totalsize/type->count : 0);
}
dictReleaseIterator(di);
4.2、使用开源工具发现大Keyimport org.codehaus.jackson.annotate.JsonProperty;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
public class JsonTest {
@JsonProperty("u")
private String userName;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public static void main(String[] args) throws IOException {
JsonTest output = new JsonTest();
output.setUserName("京东到家");
System.out.println(new ObjectMapper().writeValueAsString(output));
String json = "{\"u\":\"京东到家\"}";
JsonTest r1 = new ObjectMapper().readValue(json, JsonTest.class);
System.out.println(r1.getUserName());
}
}
{"u":"京东到家"}
京东到家
.采用压缩算法,利用时间换空间,进行序列化与反序列化。同时也存在缓存数据识别性低的缺点;.在业务上进行干预,设置阈值。比如用户购物车的商品数量,或者领券的数量,不能无限的增大;
// 从数据库中删除给定的键,键的值,以及键的过期时间。
// 删除成功返回 1,因为键不存在而导致删除失败时,返回 0
int dbDelete(redisDb *db, robj *key) {
// 删除键的过期时间
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
// 删除键值对
if (dictDelete(db->dict,key->ptr) == DICT_OK) {
// 如果开启了集群模式,那么从槽中删除给定的键
if (server.cluster_enabled) slotToKeyDel(key);
return 1;
} else {
// 键不存在
return 0;
}
}
4.0 版本 < redis_version < 6.0 版本:引入lazy-free,手动开启lazy-free时,有4个选项可以控制,分别对应不同场景下,是否开启异步释放内存机制:public void scanRedis(String cursor,String endCursor) {
ReloadableJimClientFactory factory = new ReloadableJimClientFactory();
String jimUrl = "jim://xxx/546";
factory.setJimUrl(jimUrl);
Cluster client = factory.getClient();
ScanOptions.ScanOptionsBuilder scanOptions = ScanOptions.scanOptions();
scanOptions.count(100);
Boolean end = false;
int k = 0;
while (!end) {
KeyScanResult< String > result = client.scan(cursor, scanOptions.build());
for (String key :result.getResult()){
if (client.ttl(key) == -1){
logger.info("永久key为:{}" , key);
}
}
k++;
cursor = result.getCursor();
if (endCursor.equals(cursor)){
break;
}
}
}
5.2.3、UNLINKvoid delCommand(client *c) {
delGenericCommand(c,server.lazyfree_lazy_user_del);
}
void unlinkCommand(client *c) {
delGenericCommand(c,1);
}
.lazyfree-lazy-user-del支持yes或者no。默认是no;.如果设置为yes,那么del命令就等价于unlink,也是异步删除,这也同时解释了之前咱们的问题,为什么设置了lazyfree-lazy-user-del后,del命令就为异步删除。
void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
// 遍历所有输入键
for (j = 1; j < c->argc; j++) {
// 先删除过期的键
expireIfNeeded(c->db,c->argv[j],0);
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
// 尝试删除键
if (deleted) {
// 删除键成功,发送通知
signalModifiedKey(c,c->db,c->argv[j]);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",c->argv[j],c->db->id);
server.dirty++;
// 成功删除才增加 deleted 计数器的值
numdel++;
}
}
// 返回被删除键的数量
addReplyLongLong(c,numdel);
}
下面分析异步删除dbAsyncDelete()与同步删除dbSyncDelete(),底层同时也是调用dbGenericDelete()方法int dbSyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 0, DB_FLAG_KEY_DELETED);
}
int dbAsyncDelete(redisDb *db, robj *key) {
return dbGenericDelete(db, key, 1, DB_FLAG_KEY_DELETED);
}
int dbGenericDelete(redisDb *db, robj *key, int async, int flags) {
dictEntry **plink;
int table;
dictEntry *de = dictTwoPhaseUnlinkFind(db->dict,key->ptr,&plink,&table);
if (de) {
robj *val = dictGetVal(de);
/* RM_StringDMA may call dbUnshareStringValue which may free val, so we need to incr to retain val */
incrRefCount(val);
/* Tells the module that the key has been unlinked from the database. */
moduleNotifyKeyUnlink(key,val,db->id,flags);
/* We want to try to unblock any module clients or clients using a blocking XREADGROUP */
signalDeletedKeyAsReady(db,key,val->type);
// 在调用用freeObjAsync之前,我们应该先调用decrRefCount。否则,引用计数可能大于1,导致freeObjAsync无法正常工作。
decrRefCount(val);
// 如果是异步删除,则会调用 freeObjAsync 异步释放 value 占用的内存。同时,将 key 对应的 value 设置为 NULL。
if (async) {
/* Because of dbUnshareStringValue, the val in de may change. */
freeObjAsync(key, dictGetVal(de), db->id);
dictSetVal(db->dict, de, NULL);
}
// 如果是集群模式,还会更新对应 slot 的相关信息
if (server.cluster_enabled) slotToKeyDelEntry(de, db);
/* Deleting an entry from the expires dict will not free the sds of the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
// 释放内存
dictTwoPhaseUnlinkFree(db->dict,de,plink,table);
return 1;
} else {
return 0;
}
}
如果为异步删除,调用freeObjAsync()方法,根据以下代码分析:#define LAZYFREE_THRESHOLD 64
/* Free an object, if the object is huge enough, free it in async way. */
void freeObjAsync(robj *key, robj *obj, int dbid) {
size_t free_effort = lazyfreeGetFreeEffort(key,obj,dbid);
if (free_effort > LAZYFREE_THRESHOLD && obj->refcount == 1) {
atomicIncr(lazyfree_objects,1);
bioCreateLazyFreeJob(lazyfreeFreeObject,1,obj);
} else {
decrRefCount(obj);
}
}
size_t lazyfreeGetFreeEffort(robj *key, robj *obj, int dbid) {
if (obj->type == OBJ_LIST && obj->encoding == OBJ_ENCODING_QUICKLIST) {
quicklist *ql = obj->ptr;
return ql->len;
} else if (obj->type == OBJ_SET && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else if (obj->type == OBJ_ZSET && obj->encoding == OBJ_ENCODING_SKIPLIST){
zset *zs = obj->ptr;
return zs->zsl->length;
} else if (obj->type == OBJ_HASH && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else if (obj->type == OBJ_STREAM) {
...
return effort;
} else if (obj->type == OBJ_MODULE) {
size_t effort = moduleGetFreeEffort(key, obj, dbid);
/* If the module's free_effort returns 0, we will use asynchronous free
* memory by default. */
return effort == 0 ? ULONG_MAX : effort;
} else {
return 1; /* Everything else is a single allocation. */
}
}
分析后咱们可以得出如下结论: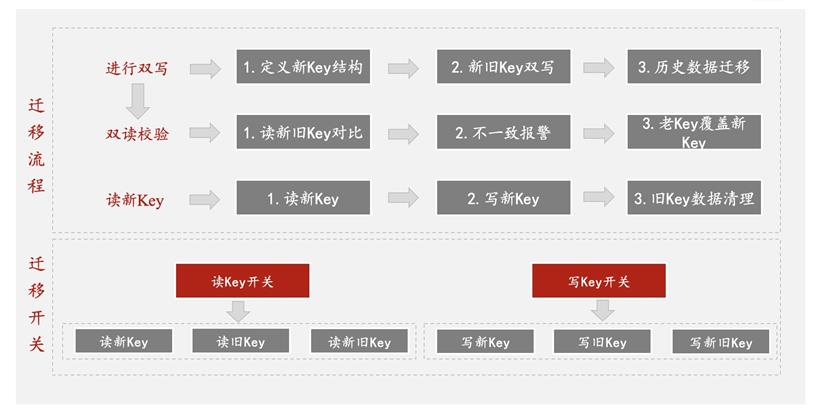
第一种:
userPin:storeId的集合
第二种:
userPin_storeId1:{门店下加车的所有商品基本信息};
userPin_storeId2:{门店下加车的所有商品基本信息}





