- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号


SELECT brand_id , sum(amount) AS total_amount FROM ea_order WHERE `status` = 1 AND create_time > '2023-12-06' //当天 GROUP BY brand_id ORDER BY total_amount DESC;
但有一点,这种大电商平台一旦搞促销的话,家电品类的单日订单量达到几百万是很轻松的。这种情况下,不但SQL执行时间很长,并且对数据库资源的消耗也很大。另外就是,如果产品经理加了新需求,还要要统计当月订单量的排行榜,那就直接GG了。因此,我们需要寻求新的解决方案,该方案需要同时满足高实时性、高性能、海量数据三个要求,缺一不可。这时候,就混到Redis ZSet粉墨登场了。
//好友关注场景 redis> SADD Tony Mary //Mary关注了Tony (integer) 1 redis> SADD Tony Lynn //Lynn关注了Tony (integer) 1 redis> SMEMBERS Tony //Tony的粉丝列表 1) "Mary" 2) "Lynn" redis> SADD Tom Mary //Mary关注了Tom (integer) 1 redis> SADD Tom Eric //Eric关注了Tom (integer) 1 redis> SMEMBERS Tom //Tom的粉丝列表 1) "Mary" 2) "Eric" redis> SINTER Tony Tom //Tony和Tom的共同粉丝 1) "Mary" redis> SUNION Tony Tom //Tony和Tom两个人的所有粉丝 1) "Mary" 2) "Lynn" 3) "Eric" redis> SDIFF Tony Tom //关注了Tony,但没有关注Tom的人 1) "Lynn" redis> SDIFF Tom Tony //关注了Tom,但没有关注Tony的人 1) "Eric"说下Set和List数据结构的区别:

//销量排行榜场景 redis> ZADD 家电全品类 5.5 海尔 //添加了海尔电器和5.5亿销售额 (integer) 1 redis> ZADD 家电全品类 4.5 美的 //添加了美的电器和4.5亿销售额 (integer) 1 redis> ZADD 家电全品类 3.2 小米 //添加了小米电器和3.2亿销售额 (integer) 1 redis> ZADD 家电全品类 2.7 格力 //添加了格力电器和2.7亿销售额 (integer) 1 redis> ZCARD 家电全品类 //家电全品类的数量 (integer) 4 redis> ZSCORE 家电全品类 格力 //获取格力的销售额 "2.7" redis> ZREVRANGE 家电全品类 0 -1 WITHSCORES //家电全品类的倒序输出 1) "海尔" 2) "5.5" 3) "美的" 4) "4.5" 5) "小米" 6) "3.2" 7) "格力" 8) "2.7" redis> ZRANGE 家电全品类 0 -1 WITHSCORES //家电全品类的正序输出 1) "格力" 2) "2.7" 3) "小米" 4) "3.2" 5) "美的" 6) "4.5" 7) "海尔" 8) "5.5" redis> ZINCRBY 家电全品类 2.2 格力 //为格力增加2.2亿销售额 "4.9" redis> ZREVRANGE 家电全品类 0 -1 WITHSCORES //增加销售额后的排行榜变化 1) "海尔" 2) "5.5" 3) "格力" 4) "4.9" 5) "美的" 6) "4.5" 7) "小米" 8) "3.2"
ZSet具备非常好的性能和并发度,以下为Redis性能白皮书上的指标:
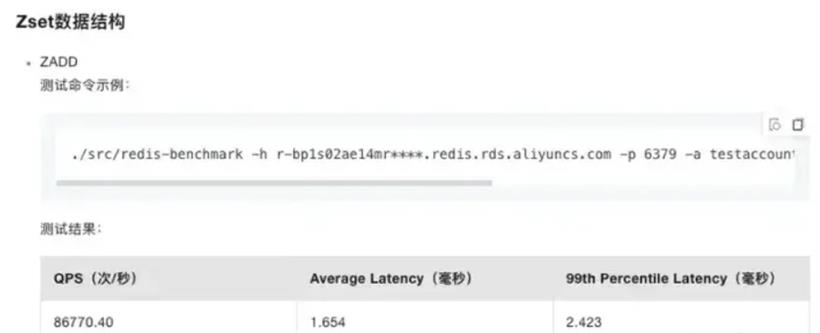
下面我们就来分别介绍一下。
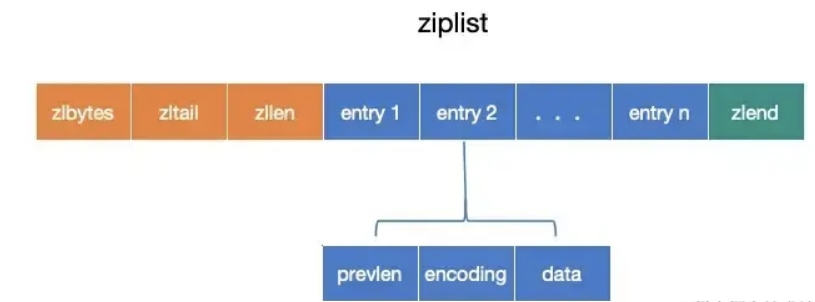
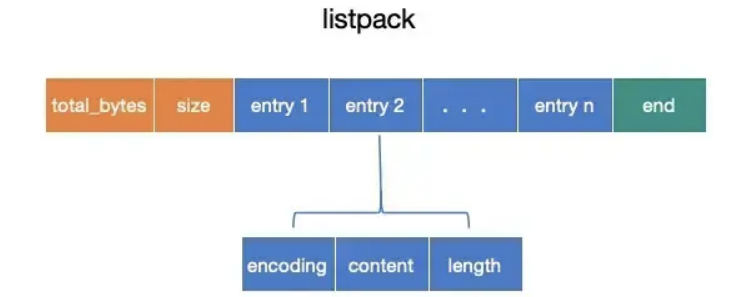
而entry中,多了length字段,来记录encoding + content的总长度,重点是少了prevlen字段,从而避免了ziplist中的级联更新问题。