

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

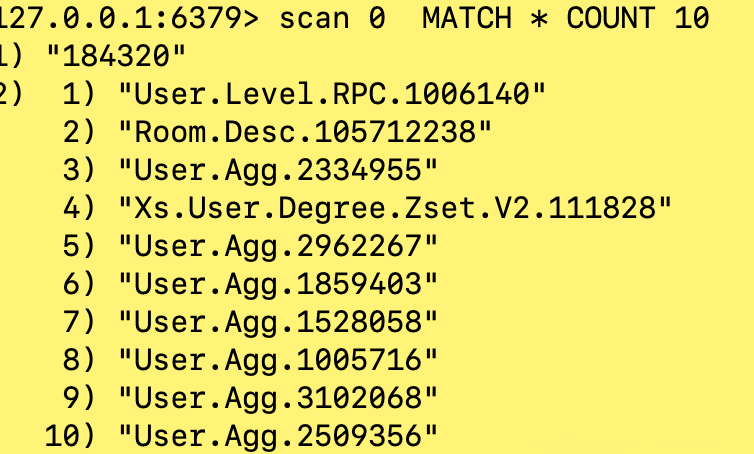
Redis的SCAN命令被用来逐步迭代数据库中的键(keys),而不是一次性地返回所有键,从而避免长时间阻塞Redis服务器。它尤其适合于大型数据集的操作。
SCAN cursor [MATCH pattern] [COUNT count]cursor: 迭代开始的游标位置
package main
import (
"context"
"fmt"
"github.com/go-redis/redis/v8"
)
var ctx = context.Background()
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // Redis密码,没有则留空
DB: 0, // 默认数据库,默认是0
})
var cursor uint64
var count int64
var keys []string
var err error
count = 10 // 每次迭代期望返回值数量
for {
keys, cursor, err = rdb.Scan(ctx, cursor, "*", count).Result()
if err != nil {
panic(err)
}
// 处理keys...
for _, key := range keys {
fmt.Println(key)
}
// 堆代码 duidaima.com
// 当游标回到0时结束循环
if cursor == 0 {
break
}
}
}
上述代码会连接到本地运行的Redis服务,并开始以每次10个元素的方式遍历数据库中所有的键。注意,你可能想要将"*"替换为你自己的匹配模式。在每次迭代过程中提取出的键被打印出来,直到最终游标值为0,表示迭代结束。在实际应用中,你可能需要细化如何处理迭代到的键。比如,你可以将它们加入到某个列表中进行批量操作,或者逐一进行分析和处理。COUNT参数误解:COUNT只是建议在一次迭代中期望的返回值数量,并不是一个严格的限制。实际返回的结果数量可能多于或少于这个数值。开发人员不应依赖COUNT来猜测迭代次数或结果数量。





