

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

x = 1; y = 3; x = 2;编译器可能会得出这样的结论:
x = 2; y = 3;这颠倒了语句的顺序,完全消除了一个语句。从单线程的角度来看,这是完全不可观察的:在执行了所有语句之后,处于完全相同的状态。但是如果我们的程序是多线程的,我们可能依赖于x实际上在y被赋值之前被赋值为1。我们希望编译器能够进行这些类型的优化,因为它们可以大大提高性能。另一方面,我们也希望我们的程序能够按照我们说的去做。
内存模型根据happens-before关系定义操作发生的顺序。Happens-before关系仅在少数特定情况下出现,例如在生成和连接线程、解锁和锁定互斥锁以及通过使用non-relaxed内存排序的原子操作时。
.当生成和连接线程时:当生成线程时,在线程创建操作和线程启动操作之间创建了happens-before关系。这确保了线程启动操作会看到线程创建操作所做的任何更改。
.解锁和锁定互斥锁时:当互斥锁被解锁时,在解锁操作和同一互斥锁上的下一个锁定操作之间创建了happens-before关系。这确保了下一个锁定互斥锁的线程将看到由解锁互斥锁的线程所做的所有更改。use std::sync::atomic::AtomicI32;
use std::sync::atomic::Ordering;
// 堆代码 duidaima.com
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn a() { // thread 1
X.store(10, Ordering::Relaxed); // 1
Y.store(20, Ordering::Relaxed); // 2
}
fn b() { // thread 2
let y = Y.load(Ordering::Relaxed); // 3
let x = X.load(Ordering::Relaxed); // 4
println!("{x} {y}");
}
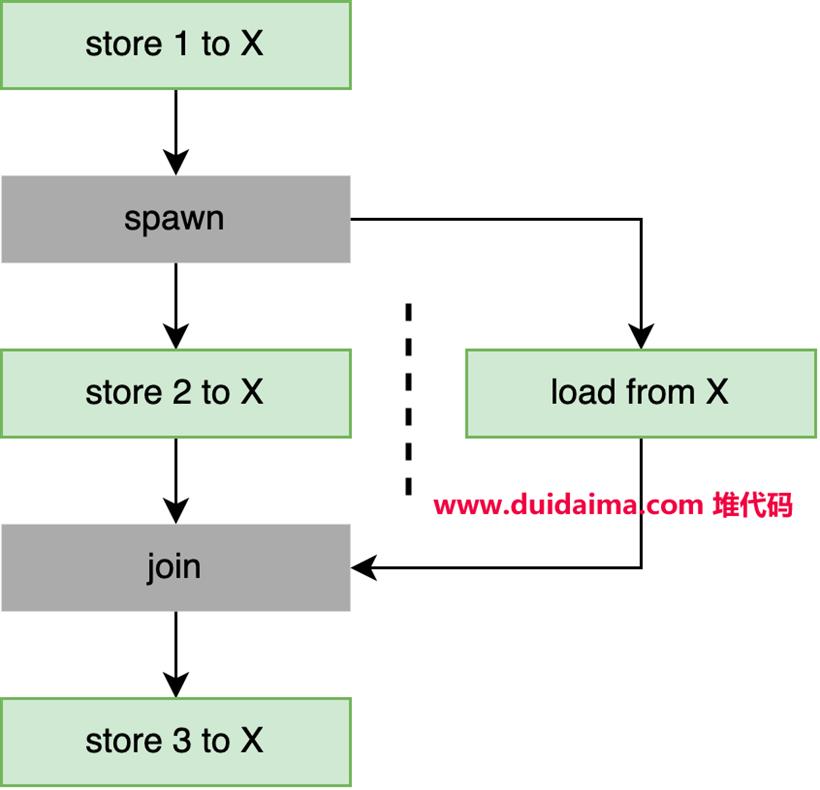
我们再看另一例子:use std::sync::atomic::AtomicI32;
use std::sync::atomic::Ordering;
static X: AtomicI32 = AtomicI32::new(0);
fn main() {
X.store(1, Ordering::Relaxed);
let t = std::thread::spawn(f);
X.store(2, Ordering::Relaxed);
t.join().unwrap();
X.store(3, Ordering::Relaxed);
}
fn f() {
let x = X.load(Ordering::Relaxed);
assert!(x == 1 || x == 2);
}
#[test]
fn test_concurrent_relaxed_memory_ordering() {
use loom::sync::atomic::AtomicU32;
use loom::sync::atomic::Ordering;
loom::model(|| {
loom::lazy_static! {
static ref X: AtomicU32 = AtomicU32::new(0);
}
let t1 = loom::thread::spawn(|| {
X.fetch_add(5, Ordering::Relaxed);
X.fetch_add(10, Ordering::Relaxed);
});
let t2 = loom::thread::spawn(|| {
let a = X.load(Ordering::Relaxed);
let b = X.load(Ordering::Relaxed);
let c = X.load(Ordering::Relaxed);
let d = X.load(Ordering::Relaxed);
assert!(a == 0 || a == 5 || a == 15, "a = {}", a);
assert!(b == 0 || b == 5 || b == 15, "b = {}", a);
assert!(c == 0 || c == 5 || c == 15, "c = {}", a);
assert!(d == 0 || d == 5 || d == 15, "d = {}", a);
// 堆代码 duidaima.com
assert!(d >= c || d >= b || d >= a, "d err");
assert!(c >= a || c >= b || d >= c, "d err");
assert!(b >= a || c >= b || d >= b, "b err");
assert!(b >= a || c >= a || d >= a, "a err");
// println!("{a} {b} {c} {d}");
// 0 0 0 15 或 0 0 10 15是不可能的
});
t1.join().unwrap();
t2.join().unwrap();
});
}
在这个例子中,只有一个线程t1修改变量X。这意味着只有一种可能的修改顺序 X:0→5→15。线程不能观察到X中与这个总修改顺序不一致的任何值。因此另一个线程t2中打印语句的输出可能是:0 0 0 0 0 0 5 15 0 15 15 15下列输出是不可能的:
0 5 0 15 0 0 10 15这是因为X的总修改顺序是0→5→15。任何不遵循此顺序的输出都是不可能的。
#[test]
fn fetch_add_atomic() {
use loom::sync::Arc;
use loom::sync::atomic::AtomicUsize;
use loom::sync::atomic::Ordering;
loom::model(|| {
let a1 = Arc::new(AtomicUsize::new(0));
let a2 = a1.clone();
let th = loom::thread::spawn(move || a2.fetch_add(1, Ordering::Relaxed));
let v1 = a1.fetch_add(1, Ordering::Relaxed);
let v2 = th.join().unwrap();
assert_ne!(v1, v2);
});
}
Non-Relaxed:释放和获取(Release-Acquire)内存排序#[test]
fn test_concurrent_release_and_acquire_memory_ordering() {
use loom::sync::atomic::AtomicU64;
use loom::sync::atomic::AtomicBool;
use loom::sync::atomic::Ordering;
loom::model(|| {
loom::lazy_static! {
static ref DATA: AtomicU64 = AtomicU64::new(0);
static ref READY: AtomicBool = AtomicBool::new(false);
}
loom::thread::spawn(|| {
DATA.store(123, Ordering::Relaxed);
READY.store(true, Ordering::Release);
});
while !READY.load(Ordering::Acquire) {
loom::thread::yield_now();
}
assert_eq!(123, DATA.load(Ordering::Relaxed));
println!("{}", DATA.load(Ordering::Relaxed));
});
}
注意,代码没有使用任何显式的同步机制,比如互斥锁。相反,它依赖于内存排序来确保两个线程看到相同的共享变量的值。这种方法可能比使用显式同步机制更有效,但也可能更难以推理。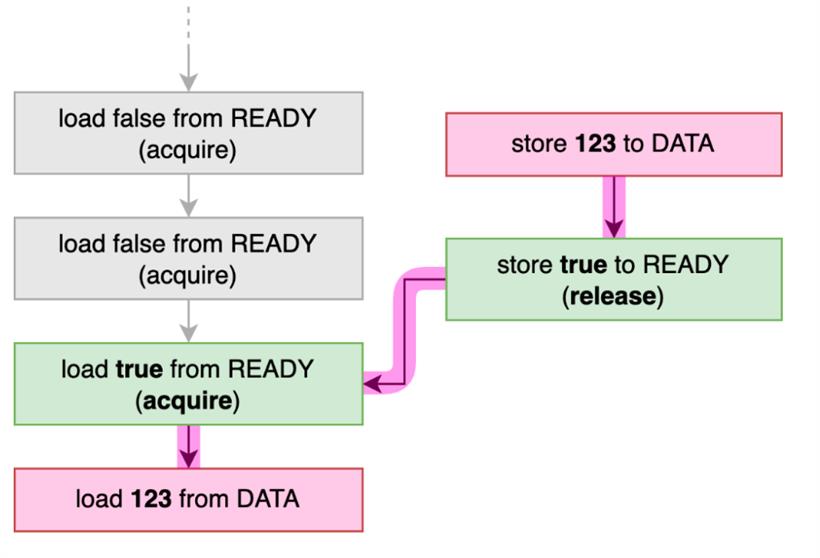
#[test]
fn test_concurrent_relaxed_memory_ordering_2() {
use loom::sync::atomic::AtomicU64;
use loom::sync::atomic::AtomicBool;
use loom::sync::atomic::Ordering;
loom::model(|| {
loom::lazy_static! {
static ref DATA: AtomicU64 = AtomicU64::new(0);
static ref READY: AtomicBool = AtomicBool::new(false);
}
loom::thread::spawn(|| {
DATA.store(123, Ordering::Relaxed);
READY.store(true, Ordering::Relaxed);
});
while !READY.load(Ordering::Relaxed) {
loom::thread::yield_now();
}
let d = DATA.load(Ordering::Relaxed);
assert!(d == 0 || d == 123 );
});
}
在上面的代码中,DATA.store和READY.store在线程中是可以重新排序的,再次记住,Relaxed的内存排序不提供任何happens-before关系。在我们正确的示例中,来自READY标志的happens-before关系保证DATA的存储和加载操作不能并发发生,这意味着实际上不需要对DATA的操作是原子的。因此,修改示例如下:#[test]
fn test_concurrent_release_and_acquire_memory_ordering_3() {
use loom::sync::atomic::AtomicBool;
use loom::sync::atomic::Ordering;
loom::model(|| {
static mut DATA: u64 = 0;
loom::lazy_static! {
// static ref DATA: AtomicU64 = AtomicU64::new(0);
static ref READY: AtomicBool = AtomicBool::new(false);
}
loom::thread::spawn(|| {
// DATA.store(123, Relaxed);
unsafe { DATA = 123 };
READY.store(true, Ordering::Release); // Everything from before this store ..
});
while !READY.load(Ordering::Acquire) { // .. is visible after this loads `true`.
loom::thread::yield_now();
}
assert_eq!(123, unsafe { DATA });
// println!("{}", DATA.load(Relaxed));
});
}
总结




