

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

异步流对你来说还是个谜吗?如果你自己动手写一个,完全可以掌握它。通过引入 async/await 编程范式,异步编程已经变得对大多数软件开发者来说更加易于上手。代码看起来几乎就像是经典的阻塞式流程,这得益于编译器在幕后构建了一个复杂的状态机。
再深入一层,Rust 使用轮询(polling)、唤醒器(waker)和固定(pinning)。这些组件虽然不使用 async/await 语法,但仍然提供了完整的非阻塞并发能力。代价是没有自动生成的状态机,这可能需要你自己来实现。作为回报,你可以获得性能提升并对工作代码有完全的控制权。一个你需要并且应该处于轮询级别的例子就是异步流。它们完美地融入了 async/await 的世界,同时在后台实现了真正的非阻塞机制,没有显著的开销。
fn main() {
let numbers = vec![1, 2, 3, 4, 5];
// 堆代码 duidaima.com
for number in numbers.iter() {
println!("Number: {}", number);
}
}
代码使用 for 循环来惯用遍历集合。这实际上等同于下面的语法。请注意,这里临时创建的迭代器是一个可变变量。fn main() {
let numbers = vec![1, 2, 3, 4, 5];
let mut iter = numbers.iter();
while let Some(number) = iter.next() {
println!("Number: {}", number);
}
}
因为我们是在遍历一个向量,我们知道这是非常快的。next 函数并没有执行任何 I/O 操作。但如果我们的迭代器提供了一系列数字或网络连接呢?我们只需修改几行代码就可以从 async/await 中获益。#[tokio::main]
async fn main() {
let mut numbers = fetch_numbers();
while let Some(number) = numbers.next().await {
println!("{}", number);
}
}
你可以看到它几乎就像一个常规的迭代器,但实际上它是一个异步流。这不是很美妙吗?让我们来看看那些尚未实现的特性是如何展现的。pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
pub trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
你可能会注意到一些相似之处。两者都定义了一个返回的项类型,正好是你在 while 循环中匹配的那种类型。它们都需要实现一个 next 函数来提供下一个要产生的项。你可能会问,到底什么是 TAR 格式,以及它与 Rust 中的异步流有什么关系。TAR 文件格式本质上是一种将一组文件和目录打包成单个文件的方法。这种格式与磁带驱动器的历史紧密相关,磁带驱动器是早期计算机时代的一种数据存储形式。它专门针对磁带存储设计,因此得名“Tape ARchive”。00000000: 4361 7267 6f2e 746f 6d6c 0000 0000 0000 Cargo.toml...... 00000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000050: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000060: 0000 0000 3030 3030 3634 3400 3030 3031 ....0000644.0001 00000070: 3735 3000 3030 3031 3735 3000 3030 3030 750.0001750.0000 00000080: 3030 3030 3037 3000 3134 3537 3136 3533 0000070.14571653 00000090: 3534 3000 3031 3233 3435 0020 3000 0000 540.012345. 0... 000000a0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000000b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000000c0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000000d0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000000e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000000f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000100: 0075 7374 6172 2020 0076 7363 6f64 6500 .ustar .vscode. 00000110: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000120: 0000 0000 0000 0000 0076 7363 6f64 6500 .........vscode. 00000130: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000140: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000150: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000160: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000170: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000180: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00000190: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001a0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001b0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001c0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001d0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001e0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 000001f0: 0000 0000 0000 0000 0000 0000 0000 0000 ................有了文档在手,我们可以试着解码其中编码的信息:
头部校验和:012345,以八进制字符串编码
enum TarEntry {
File(String),
}
struct TarArchive {
entries: Vec<TarEntry>,
}
impl TarArchive {
fn new() -> Self {
Self { entries: Vec::new() }
}
fn append_file(&mut self, file: String) {
self.entries.push(TarEntry::File(file));
}
}
你看到的是,归档只包含了要被归档的条目。现在,我们可以增加将其转换为流的可能性。这将会消耗掉归档内容。impl TarArchive {
...
fn into_stream(self, buffer_size: usize) -> TarStream {
TarStream::new(self.entries, buffer_size)
}
}
struct TarStream {
buffer_size: usize,
entries: VecDeque<TarEntry>,
}
impl TarStream {
fn new(entries: Vec<TarEntry>, buffer_size: usize) -> Self {
Self {
buffer_size: buffer_size / 512 * 512,
entries: entries.into(),
}
}
}
我们几乎创建了一个流。唯一缺少的部分是 Stream 特性的实际代码实现。enum TarChunk {
Header(String, Box<[u8; 512]>),
Data(Vec<u8>),
Padding(usize),
}
enum TarError {}
type TarResult<T> = Result<T, TarError>;
impl Stream for TarStream {
type Item = TarResult<TarChunk>;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
todo!()
}
特质实现要求定义流中的项是什么。在我们的情况下,我们想要返回一个块,确切地说是三种类型的块。头部将包含文件名和 512 字节的有效载荷。数据变体是已读文件的一个切片,但它也可能包含填充,正如文档所规定的。最后,填充变体——每个 tarball 的末尾总是发送两个空块。有了这样一个草稿,我们就可以编写一个消费者。将发生的事情输出到控制台可能就足够好了。以下代码将为三个文件生成一个 tarball。它不会真正写出 tarball,而只会显示交互式的进度。#[tokio::main]
async fn main() {
let mut archive = TarArchive::new();
archive.append_file("enwiki-20230801-pages-meta-history27.xml-p74198591p74500204".to_owned());
archive.append_file("lubuntu-22.04.3-desktop-amd64.iso".to_owned());
archive.append_file("qemu-8.2.1.tar.xz".to_owned());
let mut stream = archive.into_stream(10 * 1024 * 1024);
while let Some(chunk) = stream.next().await {
match chunk {
Ok(TarChunk::Header(path, _)) => println!("\nheader {path}"),
Ok(TarChunk::Data(_)) => print!("."),
Ok(TarChunk::Padding(0)) => println!("\npadding 0"),
Ok(TarChunk::Padding(index)) => println!("padding {index}"),
Err(error) => println!("error: {:?}", error),
}
std::io::stdout().flush().unwrap();
}
}
在我的机器上,它产生了以下输出:header enwiki-20230801-pages-meta-history27.xml-p74198591p74500204 ......................................................................... ......................................................................... ......................................................................... ......................................................................... ......................................................................... ......................................................................... ............................................................. header lubuntu-22.04.3-desktop-amd64.iso ......................................................................... ......................................................................... ......................................................................... ............................................................ header qemu-8.2.1.tar.xz ............. padding 0 padding 1点的数量代表每个 10MB 的数据块。应用程序仅运行了几秒钟。为了让我们的实现达到这样的效果,我们可以添加一个状态字段到流中,以便知道我们在状态机中的位置。
struct TarStream {
state: TarState,
...
}
impl TarStream {
pub fn new(entries: Vec<TarEntry>, buffer_size: usize) -> Self {
Self {
state: TarState::init(),
...
}
}
}
impl Stream for TarStream {
...
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> {
let self_mut = self.get_mut();
loop {
let mut state = TarState::completed();
mem::swap(&mut state, &mut self_mut.state);
let result = match state {
TarState::Init(state) => state.poll(cx),
TarState::Open(state) => state.poll(cx),
TarState::Header(state) => state.poll(cx),
TarState::Read(state) => state.poll(cx),
TarState::Padding(state) => state.poll(cx),
TarState::Completed(state) => state.poll(cx),
};
let (state, poll) = match result {
TarPollResult::ContinueLooping(state) => (state, None),
TarPollResult::ReturnPolling(state, poll) => (state, Some(poll)),
TarPollResult::NextEntry() => match self_mut.entries.pop_front() {
None => (TarState::padding(), None),
Some(entry) => (TarState::open(self_mut.buffer_size, entry), None),
},
};
self_mut.state = state;
if let Some(poll) = poll {
return poll;
}
}
}
}
你看到的是,每个状态变体都会接收到一个轮询。它返回一个轮询结果,基于这个结果,会决定是继续迭代、返回找到的轮询结果,还是直接跳转到下一个条目。每次轮询后,当前状态都会更新。但是轮询究竟是什么呢?我们会经常用到它。从一个角度来看,当我们实现一个异步流时,我们正在被轮询。从另一个角度看,我们会将轮询委托给其他可轮询的实体。每个轮询函数都有一个共同的特点:它接收一个 Context 并返回一个 Poll 枚举值。enum TarState {
Init(TarStateInit),
Open(TarStateOpen),
Header(TarStateHeader),
Read(TarStateRead),
Padding(TarStatePadding),
Completed(TarStateCompleted),
}
这些状态各自具有特殊的意义: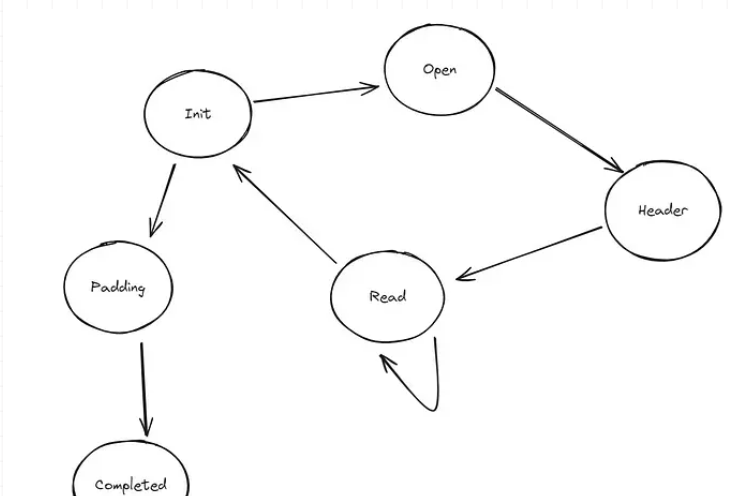
impl TarStateHandler for TarStateInit {
fn poll(self, _cx: &mut Context<'_>) -> TarPollResult {
TarPollResult::NextEntry()
}
}
你看到的是,初始状态几乎什么都不做。它的主要功能是指示流继续到下一个条目。记住,解析从任何状态返回的结果的过程是由流本身处理的:let (state, poll) = match result {
TarPollResult::ContinueLooping(state) => (state, None),
TarPollResult::ReturnPolling(state, poll) => (state, Some(poll)),
TarPollResult::NextEntry() => match self_mut.entries.pop_front() {
None => (TarState::padding(), None),
Some(entry) => (TarState::open(self_mut.buffer_size, entry), None),
},
};
在这种情况下,“下一个条目”意味着从向量中挑选下一个条目。如果没有找到任何条目,我们就开始填充;否则,我们带着新选择的条目过渡到“打开”状态。pub async fn open(path: impl AsRef<Path>) -> io::Result<File> {
let path = path.as_ref().to_owned();
let std = asyncify(|| StdFile::open(path)).await?;
Ok(File::from_std(std))
}
这对我们的意义是什么?这意味着存在一些挑战,因为我们需要轮询一个 Future。轮询一个 Future 需要将其存储为一个固定的、装箱的动态对象。struct TarStateOpen {
buffer_size: usize,
task: Pin<Box<dyn Future<Output = Result<(String, File), std::io::Error>> + Send>>,
}
impl TarStateOpen {
fn new(buffer_size: usize, entry: TarEntry) -> Self {
let task = async move {
match entry {
TarEntry::File(path) => match File::open(&path).await {
Ok(file) => Ok((path, file)),
Err(error) => Err(error),
},
}
};
Self {
buffer_size: buffer_size,
task: Box::pin(task),
}
}
}
impl TarStateHandler for TarStateOpen {
fn poll(mut self, cx: &mut Context<'_>) -> TarPollResult {
let (path, file) = match self.task.as_mut().poll(cx) {
Poll::Pending => return TarState::Open(self).pending(),
Poll::Ready(Err(error)) => return TarState::failed(TarError::IOFailed(error)),
Poll::Ready(Ok((path, file))) => (path, file),
};
TarStateHeader::new(self.buffer_size, path, file).poll(cx)
}
}
你看到的是,在构造函数中,我们存储了一个指向从异步块返回的 Future 的固定引用。我们不能直接等待它,但我们可以在 poll 函数中稍后轮询它。如果我们得到 Pending,我们就简单地返回相同的 Init 状态,并附带一个 Pending 的流结果。如果我们成功地收到了一个元组,我们就把它传递给下一个状态。这不是很直接吗?pub async fn metadata(&self) -> io::Result<Metadata> {
let std = self.std.clone();
asyncify(move || std.metadata()).await
}
这意味着我们需要存储这个 Future 以及我们在前一个状态中收到的文件。struct TarStateHeader {
buffer_size: usize,
path: String,
task: Pin<Box<dyn Future<Output = Result<(File, Metadata), std::io::Error>> + Send>>,
}
impl TarStateHeader {
fn new<'a>(buffer_size: usize, path: String, file: File) -> TarStateHeader {
let task = async move {
match file.metadata().await {
Ok(metadata) => Ok((file, metadata)),
Err(error) => Err(error),
}
};
Self {
path: path,
task: Box::pin(task),
buffer_size: buffer_size,
}
}
}
impl TarStateHandler for TarStateHeader {
fn poll(mut self, cx: &mut Context<'_>) -> TarPollResult {
let (file, metadata) = match self.task.as_mut().poll(cx) {
Poll::Pending => return TarState::Header(self).pending(),
Poll::Ready(Err(error)) => return TarState::failed(TarError::IOFailed(error)),
Poll::Ready(Ok(metadata)) => metadata,
};
let length: u64 = metadata.len();
let header: TarHeader = TarHeader::empty(self.path);
match header.write(&metadata) {
Ok(chunk) => TarState::read(self.buffer_size, file, length).ready(chunk),
Err(error) => TarState::failed(error),
}
}
}
元数据将用于填充 TAR 头部结构,而文件将被传递到下一阶段。如同之前描述的状态一样,Pending 的结果意味着我们需要将它连同状态(即 self)一起返回,以便后续恢复。你可能对 TAR 头部是如何构建并转换为块感兴趣的。我有意省略了一些代码,只是为了展示构建头部的基本步骤。struct TarHeader {
path: String,
data: Box<[u8; 512]>,
}
impl TarHeader {
...
fn write(mut self, metadata: &Metadata) -> TarResult<TarChunk> {
let data = &mut self.data;
Self::write_name(data, &self.path)?;
Self::write_mode(data, metadata)?;
Self::write_uid(data, 0)?;
Self::write_gid(data, 0)?;
Self::write_size(data, metadata)?;
Self::write_mtime(data, metadata)?;
Self::write_magic(data)?;
Self::write_type_flag(data)?;
Self::write_chksum(data)?;
Ok(self.into())
}
}
impl Into<TarChunk> for TarHeader {
fn into(self) -> TarChunk {
TarChunk::header(self.path, self.data)
}
}
最后是读取状态。它似乎是最重要的状态,因为 CPU 在这里将花费大部分时间。它也将是最常struct TarStateRead {
buffer_size: usize,
file: File,
left: usize,
completed: usize,
chunk: TarChunk,
offset: usize,
}
impl TarStateRead {
fn new(buffer_size: usize, file: File, length: u64) -> Self {
let left = length as usize / 512;
let available = buffer_size / 512;
let pages = std::cmp::min(available, left);
let pages = pages + if length as usize > 0 { 1 } else { 0 };
Self {
buffer_size: buffer_size,
file: file,
left: length as usize,
completed: 0,
chunk: TarChunk::data(pages),
offset: 0,
}
}
fn advance(self, bytes: usize) -> Self {
Self {
buffer_size: self.buffer_size,
file: self.file,
left: self.left - bytes,
completed: self.completed + bytes,
chunk: self.chunk,
offset: self.offset + bytes,
}
}
fn next(self) -> (TarChunk, Self) {
let left = self.left / 512;
let available = self.buffer_size / 512;
let pages = std::cmp::min(available, left);
let pages = pages + if self.left % 512 > 0 { 1 } else { 0 };
(
self.chunk,
Self {
buffer_size: self.buffer_size,
file: self.file,
left: self.left,
completed: self.completed,
chunk: TarChunk::data(pages),
offset: 0,
},
)
}
}
你看到的是,我们需要管理许多更多的字段。状态不仅包含要从中读取的文件,还包括文件长度以及一些表示当前位置、剩余字节数或在当前块中的偏移量的数字。你也可以注意到一个当前块,它可能还没有被完全填满,甚至可能是空的。我们定义了两个有用的函数:advance 和 next。第一个函数帮助我们在当前块中推进偏移量,而后者创建一个新的状态,返回之前填充的块。impl TarStateHandler for TarStateRead {
fn poll(mut self, cx: &mut Context<'_>) -> TarPollResult {
let pinned: Pin<&mut File> = Pin::new(&mut self.file);
let data = match self.chunk.offset(self.offset) {
Err(error) => return TarState::failed(error),
Ok(data) => data,
};
let mut buffer: ReadBuf<'_> = ReadBuf::new(data);
match pinned.poll_read(cx, &mut buffer) {
Poll::Pending => return TarState::Read(self).pending(),
Poll::Ready(Err(error)) => return TarState::failed(TarError::IOFailed(error)),
_ => (),
}
let read: usize = buffer.filled().len();
let advanced: TarStateRead = self.advance(read);
if advanced.left == 0 {
return TarState::init().ready(advanced.chunk);
}
if advanced.offset == advanced.chunk.len() {
let (chunk, state) = advanced.next();
return TarState::from(TarState::Read(state)).ready(chunk);
}
TarState::from(TarState::Read(advanced)).looping()
}
}
主要流程是类似的。当数据还未准备好时,我们返回待定状态。但当我们收到一些数据时,我们需要做出几个决策。当前块是否已被完全填满?我们是否已经完成了文件的读取?这些问题的答案会影响返回的状态,或者可能影响流,产生一个块。接下来是什么呢?是填充状态,对吧?它是最简单的状态之一。它包括一个用于表示其索引的字段。struct TarStatePadding {
index: usize,
}
impl TarStatePadding {
fn new() -> Self {
Self { index: 0 }
}
fn next(self) -> Self {
Self { index: self.index + 1 }
}
}
我们知道我们需要在结尾处发送正好两个这样的填充块。这使得状态处理器相对简单明了。impl TarStateHandler for TarStatePadding {
fn poll(self, _cx: &mut Context<'_>) -> TarPollResult {
match self.index {
0 => TarState::Padding(self.next()).ready(TarChunk::padding(0)),
index => TarState::completed().ready(TarChunk::padding(index)),
}
}
}
一旦我们知道已经发送了两个填充块,我们就需要过渡到完成状态。这很复杂吗?一点也不。它仅仅涉及返回 None 来表示流的结束。impl TarStateHandler for TarStateCompleted {
fn poll(self, _cx: &mut Context<'_>) -> TarPollResult {
TarPollResult::ReturnPolling(TarState::completed(), Poll::Ready(None))
}
}
当我们覆盖了所有状态之后,你可能会感到有些不知所措。所有这些代码实际上可以通过使用 async/await 由编译器自动生成。它会稍微更简洁一些,因为可维护性并不是编译器的首要关注点。我在开头提到过,我们还将尝试使用这个异步流将几个文件上传到创建的 Docker 容器中。在我的上一个故事中,我通过 Unix 套接字构建了一个轻量级的 HTTP 客户端来与 Docker Runtime API 通信。我们将扩展它的功能。pub struct TarBody {
inner: TarStream,
}
impl TarBody {
pub fn from(stream: TarStream) -> Self {
Self { inner: stream }
}
}
impl Body for TarBody {
type Data = Bytes;
type Error = DockerError;
fn poll_frame(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Result<Frame<Self::Data>, Self::Error>>> {
let self_mut: &mut TarBody = self.get_mut();
let pointer: &mut TarStream = &mut self_mut.inner;
let inner: Pin<&mut TarStream> = Pin::new(pointer);
match inner.poll_next(cx) {
Poll::Pending => Poll::Pending,
Poll::Ready(chunk) => match chunk {
None => Poll::Ready(None),
Some(Err(error)) => Poll::Ready(Some(DockerError::raise_outgoing_archive_failed(error))),
Some(Ok(chunk)) => {
let data: Vec<u8> = chunk.into();
let frame: Frame<Bytes> = Frame::data(Bytes::from(data));
Poll::Ready(Some(Ok(frame)))
}
},
}
}
}
在 33 行代码中,我们神奇地将一个 tar 块转换成了 hyper 所期望的字节帧,并在这个过程中处理了所有可能出现的错误。这个过程如何整合进 HTTP 客户端中呢?请考虑以下代码:async fn container_upload(&self, id: &str, path: &str, archive: TarArchive) -> DockerResult<ContainerUpload> {
let url: String = format!("/v1.42/containers/{id}/archive?path={path}");
let connection: DockerConnection<TarBody> = DockerConnection::open(&self.socket).await?;
let stream: TarStream = archive.into_stream(256 * 1024);
let data: TarBody = TarBody::from(stream);
match connection.put(&url, data).await {
Ok(response) => match response.into_bytes().await {
Ok(_) => Ok(ContainerUpload::Succeeded),
Err(error) => Err(error),
},
Err(error) => match error {
DockerError::StatusFailed(url, status, response) => match status.as_u16() {
400 => Ok(ContainerUpload::BadParameter(response.into_error().await?)),
403 => Ok(ContainerUpload::PermissionDenied(response.into_error().await?)),
404 => Ok(ContainerUpload::NoSuchContainer(response.into_error().await?)),
500 => Ok(ContainerUpload::ServerError(response.into_error().await?)),
_ => Err(DockerError::StatusFailed(url, status, response)),
},
error => Err(error),
},
}
}
上传函数接收我们的 tarball 流,将其转换为 tar body 流,并传递给 put 函数。我认为这是一种完美的集成。我们如何知道它按预期工作呢?让我们创建一个容器,上传几个文件,并计算它们的哈希值。然后我们可以将这些哈希值与本地文件的哈希值进行比较,以确认一切按预期工作。



