- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

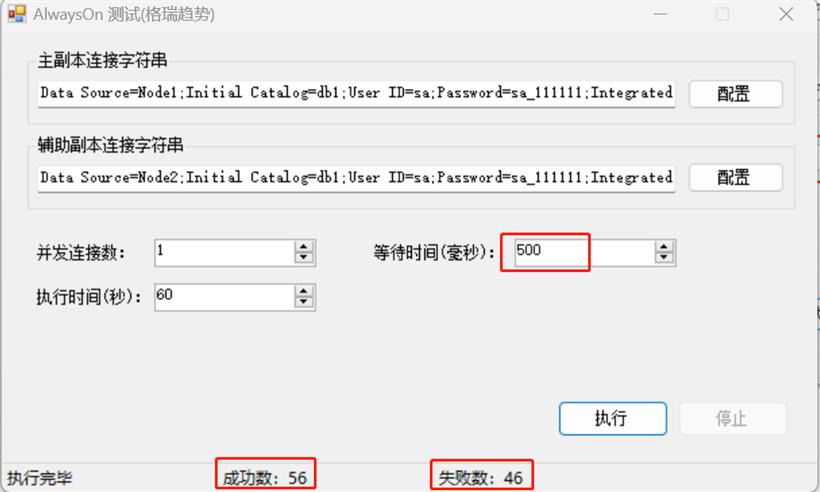
很多人认为AlwaysOn在同步提交模式下数据是实时同步的,也就是说在主副本写入数据后可以在辅助副本立即查询到。因此期望实现一个彻底的读写分离策略,即所有的写语句在主副本上,所有的只读语句分离到辅助副本上。这是一个认知误区,本文通过原理和测试进行解释。

# 堆代码 duidaima.com SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[tbl_always_on_test]( [id] [int] IDENTITY(1,1) NOT NULL, [a] [nvarchar](50) NOT NULL, CONSTRAINT [PK_tbl_always_on_test] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO写一个测试工具,首先建立到主副本数据库的连接,插入一行数据并获取新插入行的自增列的值,然后根据配置的等待时间进行线程等待,最后建立到辅助副本数据库的连接,查找新插入的这条数据是否已经存在,如存在成功数加1,不存在失败数加1。