

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号


public abstract class DataSyncHelper<T> {
protected abstract T fetchById(int Id);
protected abstract int update(T elem);
protected abstract int removeById(T ele);
protected abstract int getCount(SyncDataDto syncData);
protected abstract List<T> getList(SyncDataDto syncData);
protected abstract List<?> convertTo(List<T> dataList);
protected abstract int[] insertBatch(List<?> elems);
public void syncStart(SyncDataDto syncData, int pageSize) {
// 堆代码 duidaima.com
// 获取需要同步的数据总数
int count = getCount(syncData);
if (count <= 0) {
// 如果数据总数小于等于0,则没有需要同步的数据,记录日志并返回
log.info("sync data not args {}", syncData);
return;
}
//同步方式
//1.0 计算总页说
//2.0 将页进行拆分,获取页中的数据List
//3.0 将查询到的数据转换未目标对象
//4.0 进行数据的插入。
// 计算总页数
int totalPage = (count + pageSize - 1) / pageSize;
// 循环处理每一页的数据v
for (int i = 0; i < totalPage; i++) {
int pageIndex = i + 1;
syncData.setPageIndex(pageIndex);
syncData.setPageSize(pageSize);
try {
// 获取当前页的数据列表
List<T> dataList = getList(syncData);
if (CollectionUtils.isEmpty(dataList)) {
// 如果数据列表为空,则跳过当前页的处理
continue;
}
// 将数据列表转换为目标类型的列表
List<?> elems = convertTo(dataList);
// 批量插入数据
int[] ints = insertBatch(elems);
// 检查插入结果是否与待插入数据数量一致
if (ints.length != elems.size()) {
log.error("sync asymmetric args {}", JsonUtils.toJsonStr(syncData));
}
} catch (Exception e) {
log.error("sync data error: {}", e.getMessage());
}
}
}
3.2具体同步业务@Slf4j
@Service
public class SyncPayRecordService extends DataSyncHelper<PayRecordEntity> {
@Resource
private PayRecordDao payRecordDao;
@Resource
private PayResoureSyncDao payResoureSyncDao;
private final String LOCK_KEY = "payclass-task-sync-lock";
private final String DATA_KEY = "payclass-data-task-sync";
private boolean acquireLock(String lockKey) {
if (RedisLockDao.customLock(lockKey, 10)) {
return true;
}
log.info("正在同步中.........");
return false;
}
public void taskSync() {
if (!acquireLock(LOCK_KEY)) {
return;
}
try {
Optional<SyncDataDto> syncDataDtoOptional = Optional.ofNullable(JsonUtils.toObject(RedisDao.get(DATA_KEY)==null ? "{}": RedisDao.get(DATA_KEY), SyncDataDto.class));
SyncDataDto obj = syncDataDtoOptional.orElseGet(SyncDataDto::new);
long startId = obj.getStartId() + Constants.MAX_PAGE_SIZE;
obj.setStartId(startId);
obj.setEndId(startId + Constants.MAX_PAGE_SIZE);
RedisDao.set(DATA_KEY, JsonUtils.toJsonStr(obj));
sync(obj);
} catch (Exception ex) {
log.error(ex.getMessage(), ex);
} finally {
RedisLockDao.unlock(LOCK_KEY);
}
}
public void sync(SyncDataDto args) {
syncStart(args, Constants.MAX_PAGE_SIZE);
}
@Override
protected PayRecordEntity fetchById(int Id) {
return null;
}
@Override
protected int update(PayRecordEntity elem) {
return 0;
}
@Override
protected int removeById(PayRecordEntity ele) {
return 0;
}
@Override
protected int getCount(SyncDataDto syncData) {
return payRecordDao.counts(syncData);
}
@Override
protected List<PayRecordEntity> getList(SyncDataDto syncData) {
return payRecordDao.getList(syncData);
}
@Override
protected List<?> convertTo(List<PayRecordEntity> dataList) {
return dataList;
}
//最后直接插入
@Override
protected int[] insertBatch(List<?> elems) {
return payResoureSyncDao.batchAdd((List<PayRecordEntity>) elems);
}
}
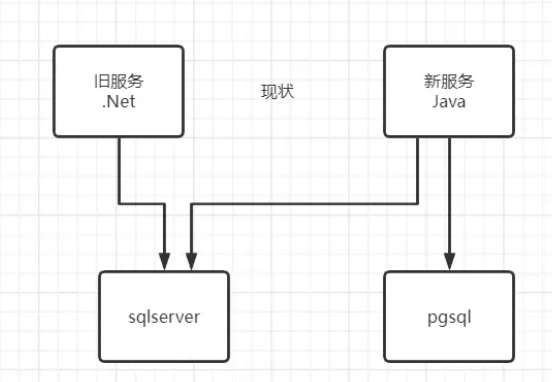
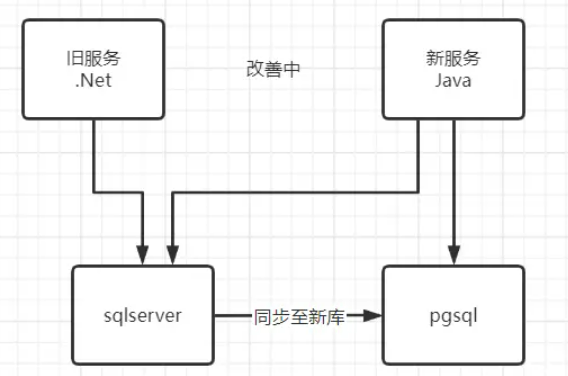
四. 将老的业务编写成为支持pgsql数据库sql server 迁移的过程中,为了不影响正常的业务 ,进行热迁移。数据写入新的数据库的同时,由于业务会产生新的数据,手写的迁移代码并不能感知到有新的数据加入进来,这个时候就要想办法,把新产生的数据继续写入到新库。
第一种解决方案 CDC (直接上实操)## 查看数据库的 CDC 状态 is_cdc_enabled = 1 开启CDC SELECT [name], is_cdc_enabled FROM sys.databases;查看表的 CDC 状态
SELECT [name], is_tracked_by_cdc FROM sys.tables;查看 CDC 作业的状态
EXEC msdb.dbo.sp_help_job;数据库开启 CDC
USE YourDatabase; -- 数据库名称 GO EXEC sys.sp_cdc_enable_db; GO -- MyTable 如下中代表的是表名称表关闭 CDC
EXECUTE sys.sp_cdc_disable_table
@source_schema = N'dbo',
@source_name = N'MyTable',
@capture_instance = N'dbo_MyTable'
表开启CDCEXECUTE sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'MyTable',
@role_name = NULL,
@supports_net_changes = 0
查看某个表某个时间段的CDCDECLARE @from_lsn binary(10), @to_lsn binary(10)
-- 获取开始和结束时间对应的 LSN
SELECT @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than', '2023-09-21T00:00:00')
SELECT @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2023-09-22T00:00:00')
-- 查询变化
SELECT * FROM cdc.fn_cdc_get_all_changes_dbo_MyTable(@from_lsn, @to_lsn, 'all')
某个表最新的CDCSELECT MAX(__$start_lsn) AS latest_lsn FROM cdc.dbo_MyTable_CT最新的CDC返回的时间
DECLARE @latest_lsn binary(10); SET @latest_lsn = (SELECT MAX(__$start_lsn) FROM cdc.dbo_MyTable_CT); SELECT sys.fn_cdc_map_lsn_to_time(@latest_lsn) AS latest_change_time;查看CDC当前设置的时长
SELECT job_id, retention FROM msdb.dbo.cdc_jobs WHERE job_type = 'cleanup'设置CDC保留的时长/ 如下是3天
EXECUTE sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention = 4320; -- 3 days in minutes
CREATE TRIGGER YourTrigger ON YourTable
FOR INSERT, UPDATE, DELETE
AS
BEGIN
DECLARE @message NVARCHAR(MAX);
SET @message = N'New changes in YourTable';
BEGIN DIALOG CONVERSATION @handle
FROM SERVICE YourService
TO SERVICE 'YourService', 'CURRENT DATABASE'
ON CONTRACT [http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification]
WITH ENCRYPTION = OFF;
SEND ON CONVERSATION @handle MESSAGE TYPE [http://schemas.microsoft.com/SQL/Notifications/PostQueryNotification] (@message);
END;
应用层监听Service Broker public List<String> receiveMessages() {
return jdbcTemplate.query(
"RECEIVE message_body FROM YourQueue;",
new RowMapper<String>() {
@Override
public String mapRow(ResultSet rs, int rowNum) throws SQLException {
return new String(rs.getBytes(1), StandardCharsets.UTF_8);
}
}
);
}
第二种解决方案



