

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

@Table(name = "cp_schedules")
@Entity
public class ScheduleRule implements Reassignable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "layers")
@DbJson
private ScheduleLayers layers = new ScheduleLayers();
...
}
步骤二,执行ddl命令生成DDL文件。命令如下:bazel run -- //tools/rules_ebean/src/main/java/internal:ebean_ddl -p=$PWD/repository-impl/src/main/sql -g="codes.showme.domain"注:这是执行一个Bazel的自定义的rule的命令。它的作用是执行Ebean ddl generator,生成DDL文件到$PWD/repository-impl/src/main/sql目录。类似Maven的一个生成DDL的插件。
try (PostgreSQLContainer postgreSQLContainer = new PostgreSQLContainer("postgres:12.8")
.withDatabaseName(TESTS_DB)
.withUsername("postgres")
.withPassword("postgres")
) {
DatabaseConfig config = new DatabaseConfig();
dbMigration.setMigrationPath(MIGRATION_PATH);
dbMigration.setPathToResources(sqlBasePath);
// 堆代码 duidaima.com
// 生成一个完整的ddl文件,方便测试
String generateInitMigration = dbMigration.generateInitMigration();
// 生成版本化的ddl文件
String reuslt = dbMigration.generateMigration();
...
// 执行sql,等于执行冒烟测试
MigrationRunner runner = new MigrationRunner(migrationConfig);
runner.run(datasource);
}
最终生成的文件和目录下如: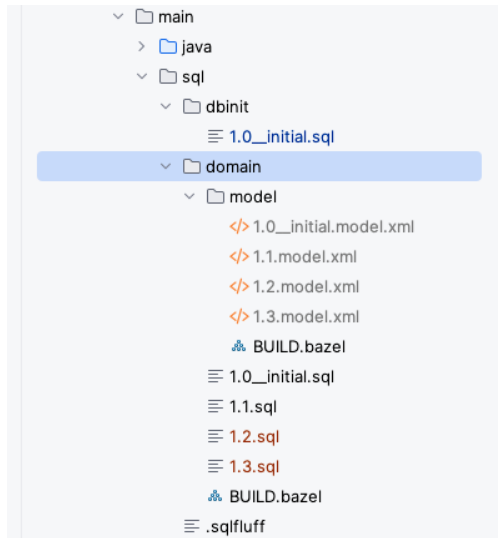
//通过testcontainers启动一个postgresql的数据库实例
@ClassRule
public static PostgreSQLContainer postgreSQLContainer = new PostgreSQLContainer("postgres:12.8")
.withDatabaseName(TESTS_DB)
.withUsername("sa")
.withPassword("sa");
// 配置ebean
MigrationConfig migrationConfig = new MigrationConfig();
migrationConfig.setDbSchema("xxx");
migrationConfig.setMetaTable("xxx");
migrationConfig.setMigrationPath("classpath:main/sql");
//执行sql,初始化数据库schema
MigrationRunner runner = new MigrationRunner(migrationConfig);
runner.run(datasource);
// 保存实体数据到数据库
ScheduleRule scheduleRule = new ScheduleRule();
scheduleRule.setName("sre");
scheduleRule.save();
// 验证结果
Assert.assertEquals(1l, scheduleRule.getId());
除了针对DB操作写集成测试,开发也可以针对Web服务进行集成测试。可以看出,以上步骤完全是在开发人员本地开发环境完成。不需要发布到测试环境验证,不需要运维人员协助。将来,运维或者DBA在准备部署生产环境时,只需要对比schema的版本的不同,就了解需要执行哪些SQL文件了。如果我们没有SQL管理平台,至少也要将这些SQL放到Git仓库中,并在发布平台上手工将变更记录与该Git仓库的commit关联起来。





