

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号
|
名词 |
解释 |
|
静态表 |
固定字段的数据表 |
|
动态表 |
通过配置key-value对,行转列的数据表 |
|
元数据 |
元数据是关于数据的数据。它描述了数据的属性、结构、关系以及数据的背景和上下文信息 |
|
|
静态表方案 |
动态表方案 |
对比 |
|
易读性
|
静态表的字段是固定的,数据结构清晰明了
|
需要依靠相对复杂的查询 |
静态表方案 ★★★★ 动态表方案 ★★★ |
|
效率
|
由于字段固定,数据库可以对这些字段进行优化,如索引、预计算等,查询效率较高
|
由于字段不固定,数据库无法对这些字段进行优化,查询效率通常较低 |
静态表方案 ★★★★ 动态表方案 ★★★ |
|
数据一致性
|
固定字段可以确保数据的一致性和完整性,因为每个字段都有明确的定义和类型
|
动态表中的数据结构不固定,可能会导致数据一致性和完整性问题,需要额外的逻辑来保证 |
静态表方案 ★★★★ 动态表方案 ★★★ |
|
可维护性
|
结构简单,易于进行数据库维护和备份
|
动态表的结构复杂,维护和备份相对困难,需要更多的开发和运维工作 |
静态表方案 ★★★★ 动态表方案 ★★★ |
|
灵活性 |
当业务需求变化时,如果需要增加或删除字段,可能需要修改数据库结构,这可能会导致较大的改动和风险 |
动态表通过key-value对存储数据,可以根据业务需求动态添加或删除字段,灵活性非常高 |
静态表方案 ★★ 动态表方案 ★★★★ |
|
存储效率 |
如果某些字段的数据量很少,但仍然需要占用固定的存储空间,可能会导致存储效率低下 |
只有实际存在的数据才会占用存储空间,避免了静态表中可能存在的空字段浪费存储空间的问题 |
静态表方案 ★★ 动态表方案 ★★★★ |
|
扩展性 |
随着业务的发展,如果需要存储更多类型的数据,静态表可能无法灵活应对 |
动态表可以轻松应对业务需求的变化,无需修改数据库结构,扩展性非常好 |
静态表方案 ★★ 动态表方案 ★★★★★ |
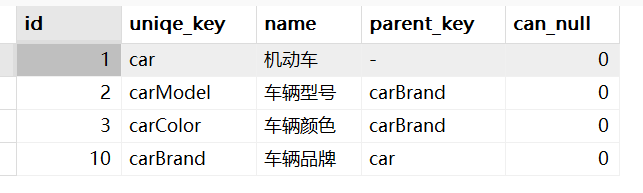
CREATE TABLE `metadata_prop_config` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键', `uniqe_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '唯一标识一个属性,允许遵循字段命名规范来定义,遵循驼峰命名法', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '属性名,页面上的表示名', `parent_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '-' COMMENT '关联本表父节点的uniqe_key', `can_null` int(11) NOT NULL DEFAULT 0 COMMENT '是否必填:0 必填 1非必填', PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `uniqe_key`(`uniqe_key`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '存放数据定义的配置表' ROW_FORMAT = Dynamic;比如
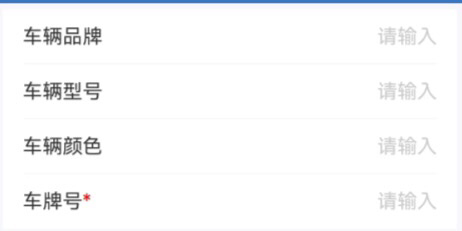
# 堆代码 duidaima.com select * from metadata_prop_config WHERE name='机动车' or parent_key in (SELECT uniqe_key from metadata_prop_config WHERE name='机动车' or parent_key in (SELECT uniqe_key from metadata_prop_config WHERE name='机动车'))
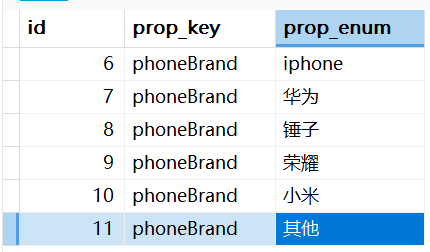
CREATE TABLE `metadata_prop_enum` ( `id` int(11) NOT NULL COMMENT '自增主键', `prop_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '关联metadata_prop_config表的uniqe_key属性', `prop_enum` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '属性值的枚举', PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `uniq_all_field`(`prop_key`, `prop_enum`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '存放数据项的取值范围约束' ROW_FORMAT = Dynamic;比如咱们需要录入居民 使用的手机,手机品牌是可以枚举的,不能选择市场上没有的。比如市场上买不到光头强用的【山寨手机】这个品牌。字段定义如下:
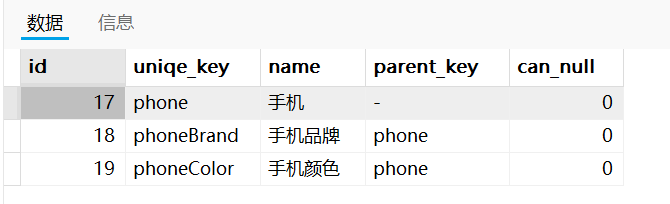
select * from metadata_prop_enum WHERE prop_key='phoneBrand'
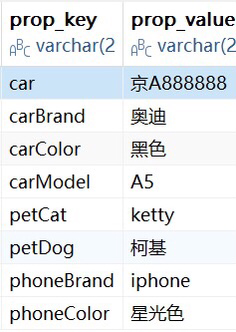
CREATE TABLE `resident_prop_relation` ( `id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '主键ID', `prop_key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '属性键', `prop_value` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '属性值', PRIMARY KEY (`id`) USING BTREE, INDEX `key_all_field`(`resident_id`, `domain_id`, `prop_key`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '存放居民的属性信息' ROW_FORMAT = DYNAMIC;一个居民可能会有以下属性:
@Data
public class ResidentInfo {
private String 居住类型;
private String 性别;
private List<Vehicle> 车辆;
@Data
public static class Vehicle {
private String 车牌号;
private String 车牌颜色;//针对电动车这个字段值都为空
private String 车辆类型;
private String 车辆品牌;
private String 电瓶类型;//针对机动车这个字段值都为空
}
}
此方案有个缺点,针对上面注释的【针对电动车这个字段值都为空】、【针对机动车这个字段值都为空】的情况,字段冗余较多,可维护性差@Data
public class ResidentInfo {
private String 居住类型;
private String 性别;
private List<Vehicle> 车辆;
@Data
public static class Vehicle {
private static Map<String, String> propMap;
// 车辆1:机动车
// propMap.put("车牌号","京A888888");
// propMap.put("车辆类型","SUV");
// propMap.put("车辆品牌","奔驰");
// propMap.put("车辆颜色","黑色");
// 车辆2:电动车
// propMap.put("车牌号","京N111111");
// propMap.put("车辆类型","Q豆锂电版");
// propMap.put("车辆品牌","爱玛");
// propMap.put("电瓶类型","12V");
}
}
此方案弥补了既有方案的缺点,增加了灵活性,但产生了新的问题:propMap到底能传哪些没有具体限定,可能会造成滥用,需要前后端充分沟通。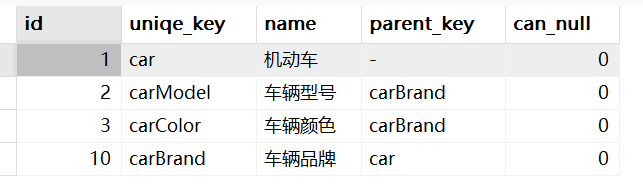
SELECT * FROM resident_prop_relation WHERE prop_key='car' AND prop_value='京A888888' AND id inMVP版本实现 3.3 交互设计 中案例条件,执行耗时800ms内。





