
-
2.3.2 练习题2 串的模式匹配(KMP)
-
问题描述
设有主串S和子串T,子串T的定位就是要在主串S中找到一个与子串T相等的子串。
算法简述
在练习题1中的算法是最简单的模式匹配算法,但是该种算法每当匹配失败时,对主串已经匹配过的字符又需要重新匹配一次,时间复杂度为O(n2)。因此这里引入了KMP算法。KMP算法与第2章第3节练习题1 串的模式匹配(Basic) 中算法最大的不同便是重新创建了一张跳转表,而且使得主串仅可以访问一次,子串可以一次跨过多个元素进行比较。为了从总体上来说明该算法,这里举个例子:
主串S:babcbabcabcaabcabcabcacabc
子串T:abcabcacab
在有些书中将子串T也称为模式串,但这都不重要,本讲解称其为子串。首先给出经过优化后的跳转表(next),从整体上简单的梳理下执行过程。
跳转表(next)

跳转表最大的特色就是决定了子串一次性可以跳过多少个元素与主串进行比较,跳转表的作用是前*next[j]-1个元素组成的字符串和第j号元素之前(不包括第j号元素)的next[j]-1*个字符串相等,这么听起来比较抽象,举个简单的例子说明下,比如以 j=8为例。
当j=8时,查得next[8]=5,则可以推出前4个元素和第8号(不包括第8号元素)元素前面的4个元素相等。
即:T[1]T[2]T[3]T[4]组成的字符串“abca”与T[4]T[5]T[6]T[7]组成的字符串“abcd”相等。
这里简写为T1,2,3,4=T4,5,6,7
不失一般性,进行一次推广,得到广义的公式。这里令k=next[j],即
T1,2,...,k−1==Tj−(k−1),j−(k−2),...,j−1
执行过程

这里应该特别注意的是主串和子串的下标标号方式不同,主串下标从0开始,子串下标从1开始。
第一轮比较中,T[1]!=S[0],查找跳转表得next[1]=0此时便可以得出子串的第一个元素与此时主串的元素不匹配,对主串的下一个元素进行比较;
进入第二轮比较,当比较到T[4]时,发现T[4]!=S[4],查找跳转表得next[4]=0,原因同上,对主串的下一个元素进行比较;
进入第三轮比较,当比较到T[8]时,发现T[8]!=S[12],查找跳转表得next[8]=5,进入下一轮比较;
进入第四轮比较,由上轮比较中得到next[8]=5,比较T[5]与S[12],结果发现T[5]!=S[12],查找跳转表得next[5]=1,进入下轮比较;
进入第五轮比较,由上轮比较中得到next[5]=1,比较T[1]与S[12],然后发现T[1]=S[12],开始挨个比较,比较到T[8]时,发现T[8]!=S[19],查找跳转表得next[8]=5,进入下轮比较;
进入第六轮比较,由上轮比较中查找过程得到next[8]=5,比较T[5]与S[19],结果发现T[5]=S[19],开始逐个比较;
最后子串T与主串S全部比较完成,返回结果。
这里便可以推出KMP算法的核心执行步骤为:
如果j==0,则表明子串的第一个元素不满足,则将主串的下一个元素与子串的第一个元素相比;
如果S[i]==T[j]则开始比较下一个元素,即S[i+1]与T[j+1];
如果不相等,则比较S[i]与T[next[j]];
算法详解
在算法简述中,简单的梳理了下执行流程,也推出了KMP算法的核心步骤,与第2章第3节练习题1 串的模式匹配(Basic) 并无太大差异,只是如果不相等的时候,并不需要对主串S的下标重置,而是对子串T进行移位便可。而真正的难点便是建立跳转表(next),因为满足跳转表(next)的元素有一个非常重要的特性便是:
T1,2,...,k−1==Tj−(k−1),j−(k−2),...,j−1
而且由上面的特性很容易发现,当第j号元素与主串相应的元素“失配”时,才需要在子串中重新置位与主串再次相比,这里便引出跳转表(next)的定义:
next[j] =
⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪0,max{k|1<k<j},1,j=1 T1,2,...,k−1==Tj−(k−1),j−(k−2),...,j−1Other
思想1
那么根据上述定义,对子串T,进行分析,很容易发现定义中涉及到了子串自身的比较,即子串在求解跳转表时既作主串又作子串,而且比较的正是T1,2,...,k−1?=Tj−(k−1),j−(k−2),...,j−1。既然这样继续以本文前面列出的子串T为例。

根据定义对子串T进行展开,可以得到下表:
j k = or ≠ next[j]
若 j=1 k=0 next[1]=0
若 j=2 k=1 next[2]=1
若 j=3 k=2 a≠b next[3]=1
若 j=4 k=2 a≠c
k=3 ab≠bc next[4]=1
若 j=5 k=2 a=a next[5]=2
k=3 ab≠ca
k=4 abc≠bca
若 j=6 k=2 a≠b
k=3 ab=ab next[6]=3
k=4 abc≠cab
k=5 abca≠bcab
若 j=7 k=2 a≠c
k=3 ab≠bc
k=4 abc=abc next[7]=4
k=5 abca≠cabc
k=6 abcab≠bcabc
若 j=8 k=2 a=a
k=3 ab≠ca
k=4 abc≠bca
k=5 abca=abca next[7]=5
k=6 abcab≠cabca
k=7 abcabc≠bcabca
若 j=9 k=2 a≠c next[9]=1
k=3 ab≠ac
k=4 abc≠cac
k=5 abca≠bcac
k=6 abcab≠abcac
k=7 abcabc≠cabcac
k=8 abcabca≠bcabcac
若 j=10 k=2 a=a next[10]=2
k=3 ab≠ca
k=4 abc≠aca
k=5 abca≠caca
k=6 abcab≠bcaca
k=7 abcabc≠abcaca
k=8 abcabca≠cabcaca
k=9 abcabcac≠bcabcaca
整理下可得跳转表(next)

根据定义和上述求解过程,很容易想到用暴力方法强解此题。算法描述如下:
void BuildNext(String* T, int next[]) { int temp[MaxSize]={0}; int k,i,max; for(int j=1;j<=T->length;j++){ for(k=1;k<j;k++){ i=0; while(T->data[i]==T->data[j-k+i]&&i<k-1){ ++i; } if(i==k-1){ temp[k]=k; }else{ temp[k]=1; } } max=temp[1]; for(int cnt=1;cnt<k;cnt++){ if(max<temp[cnt]){ max=temp[cnt]; } } next[j]=max; } }这种解法的缺点也非常明显,时间复杂度达到了惊人的O(n2),这样的算法计算跳转表的效率明显比较低下。
思想2
跳转表的存在的意义就是运用字符串本身的特点对下标进行置位,而满足跳转表条件的若干(k-1)个连续字符T1,2,...,k−1必然等于Tj−(k−1),j−(k−2),...,j−1,这样实际上就变成了将串T既看做主串又看做子串T然后进行一次比较的过程,过程描述如下:
主串T[2]与子串T[1]相比较,结果不相等,将next[3]置为1;
主串T[3]与子串T[1]相比较,结果不相等,将next[4]置为1;
主串T[4]与子串T[1]相比较,结果相等,将next[5]置为2;
以此类推,得到next[8]=5,此时T[8]与子串T[5],此时不相等,则不能得到next[9];
然后取出next[8],使子串T[next[8]]与主串T[8]相比,结果依旧不相等;然后再取出next[5],让子串T[next[5]]与主串T[8]相比,结果依旧不相等;接着取出next[2],让子串T[next[2]](即子串T[1])与主串T[8]相比,结果依旧不相等;此时将next[9]置1;
最后主串T[9]与子串T[1]相比,结果相等,则将next[10]置为2。
为了更为形象的说明上面的描述,再次具体化以上过程 ,如下所示:
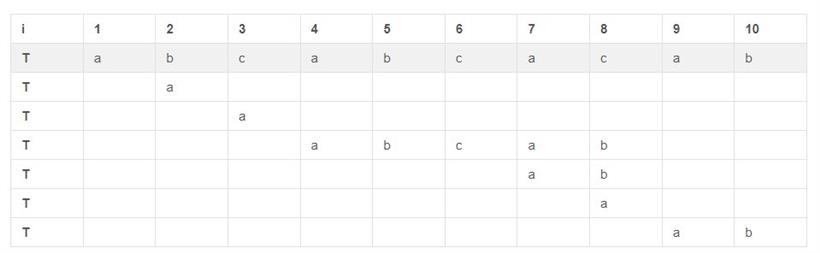
扼要的总结下思想:
令k=next[j]
若T[k]==T[j],则有T1,2,...,k==Tj−(k−1),j−(k−2),...,j;也就是说next[j+1]=next[j]+1
若T[k]!=T[j]时,便是一个回溯的过程,是求跳转表的难点,可以参考上面的过程理解。
这样 便通过将串T既看做子串又看做主串的方式进行比较,从而得到了跳转表,如下所示:

根据上面的过程,轻而易举的可以写出该算法的扼要过程,如下所示:
void BuildNext(String* T, int next[]) { int i, j; i=1; j=0; next[1]=0; while(i<T->length){ if(T->data[i]==T->data[j]||j==0){ ++i; ++j; next[i]=j; }else{ j=next[j]; } } }最后再将主串S和子串T从头比较一次,熟悉下整个流程,过程如下:
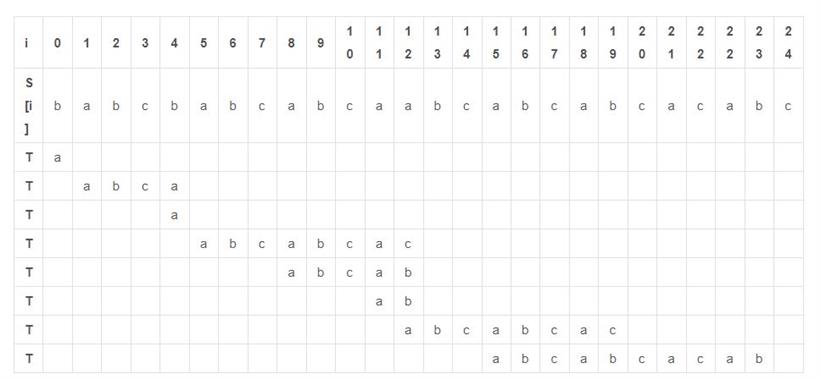
思想3
上面虽然已经完成了建立跳转表,使用KMP算法完成了子串的查找,但是通过分析就可以发现,建立跳转表完全可以再优化一次,即一步到位。
主串S[4]与子串T[4]完全可以不需要,因为T[4]==T[1],已经判断出T[4]!=S[4],也就无需在额外的判断T[1]!=S[4]了;
主串S[12]与子串T[2]亦完全可以不要 ,原因同上,已知T[5]==T[2] ,也就无需判断T[2] !=S[12]了;
先对跳转表完成优化,如下所示:

对上述过程进行总结,完成对算法的优化,描述如下:
void BuildNext(String* T, int next[]) { int i, j; i=1; j=0; next[1]=0; while(i<T->length){ if(T->data[i]==T->data[j]||j==0){ ++i; ++j; if(T->data[i]!=T->data[j]){ next[i]=j; }else{ next[i]=next[j]; } }else{ j=next[j]; } } }至此,KMP算法的讲解算是完成了,具体代码:
#include<stdio.h> #include<stdlib.h> #define MaxSize 100 typedef char ElemType; typedef struct{ ElemType data[MaxSize]; int length; }String; void StrCreatS(String*); void StrCreatT(String*); void Print(String*); void BuildNext(String*,int*); int KMP(String*,String*,int*); int main(int argc,char* argv[]) { String *s; s=(String*)malloc(sizeof(String)); StrCreatS(s); String *t; t=(String*)malloc(sizeof(String)); StrCreatT(t); int next[MaxSize]={0}; BuildNext(t,next); int flag=KMP(s,t,next); if(flag!=-1){ printf("Position is %d.\n",flag+1); }else{ printf("Illege Find!\n"); } return 0; } //创建主串 void StrCreatS(String* S){ char x; S->length=0; printf("Input String_S(End of '#'!):\n"); scanf("%c",&x); while(x!='#'){ S->data[S->length++]=x; scanf("%c",&x); } getchar(); } //创建子串 void StrCreatT(String* S){ char x; S->length=0; printf("Input String_T(End of '#'!):\n"); scanf("%c",&x); while(x!='#'){ S->data[++S->length]=x; scanf("%c",&x); } getchar(); } //打印字符串 void Print(String *S) { for(int i=0;i<S->length;i++){ printf("%c",S->data[i]); } printf("\n"); } //建立跳转表 void BuildNext(String* T, int next[]) { int i, j; i=1; j=0; next[1]=0; while(i<T->length){ if(T->data[i]==T->data[j]||j==0){ ++i; ++j; if(T->data[i]!=T->data[j]){ next[i]=j; }else{ next[i]=next[j]; } }else{ j=next[j]; } } } //KMP算法的核心 int KMP(String* S, String* T,int next[]) { int i=0, j=1; while(i<S->length&&j<T->length){ if(S->data[i]==T->data[j]||j==0){ ++i; ++j; }else{ j = next[j]; } } if(j==T->length){ return i+1-T->length; }else{ return -1; } }参考文献
Knuth D E, Morris J H, Pratt V R. Fast Pattern Matching in Strings.[J]. Siam Journal on Computing, 1977, 6(2):323-350.
- 留下你的读书笔记
- 你还没登录,点击这里
-
用户笔记留言