

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

安装引擎
我用的Windows64位版本,安装期间,需要根据需要识别的内容,选择需要的语言包。默认只有英文。例如我选择简体中文。
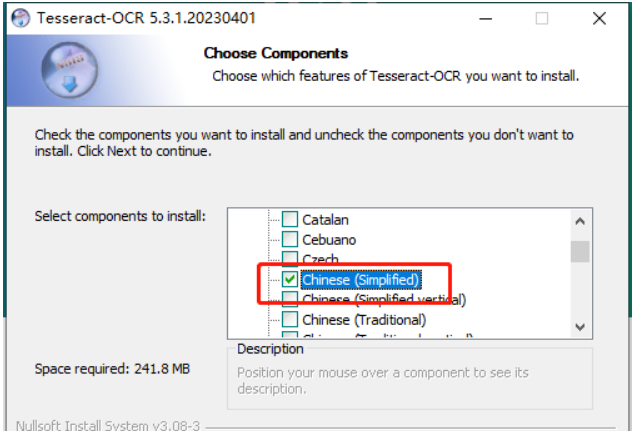


Tesseract ocr = new Tesseract(@"D:\Program Files\Tesseract-OCR\tessdata", "chi_sim", OcrEngineMode.Default);截图了个图片拿来测试。测试图片:

// 读取图像文件
using (Mat image = CvInvoke.Imread(@"D:\test.png", ImreadModes.Color))
{
if (image != null)
{
// 设置要识别的图像
ocr.SetImage(image);
// 堆代码 duidaima.com
// 执行OCR识别
var res = ocr.Recognize();
if(res == 0)
{
Tesseract.Character[] characters = ocr.GetCharacters();
// 输出识别结果
foreach (var character in characters)
{
Console.Write($"{character.Text}");
}
}
}
}
运行程序,查看效果:





