先看效果
获取关键点
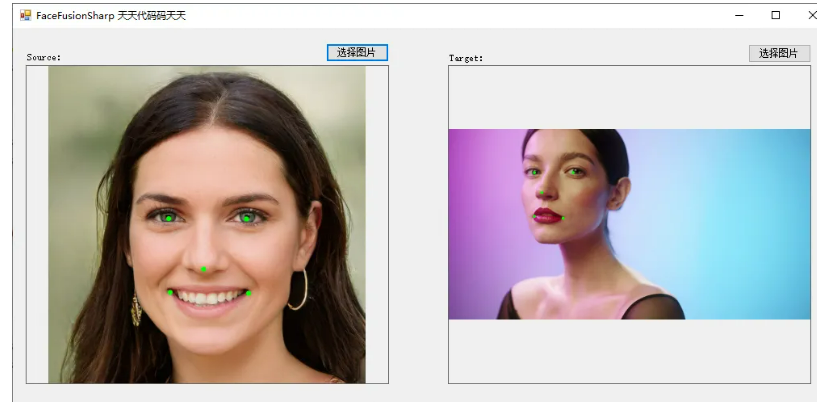 说明
说明
C#版Facefusion一共有如下5个步骤:
1、使用yoloface_8n.onnx进行人脸检测
2、使用2dfan4.onnx获取人脸关键点
3、使用arcface_w600k_r50.onnx获取人脸特征值
4、使用inswapper_128.onnx进行人脸交换
5、使用gfpgan_1.4.onnx进行人脸增强
本文分享使用2dfan4.onnx实现C#版Facefusion第二步:获取人脸关键点。顺便再看一下C++、Python代码的实现方式,可以对比学习。
模型信息
Inputs
-------------------------
name:input
tensor:Float[1, 3, 256, 256]
---------------------------------------------------------------
Outputs
-------------------------
name:landmarks_xyscore
tensor:Float[1, 68, 3]
name:heatmaps
tensor:Float[1, 68, 64, 64]
---------------------------------------------------------------
代码
调用代码
using Newtonsoft.Json;
using OpenCvSharp;
using OpenCvSharp.Extensions;
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Windows.Forms;
namespace FaceFusionSharp
{
public partial class Form2 : Form
{
public Form2()
{
InitializeComponent();
}
string fileFilter = "*.*|*.bmp;*.jpg;*.jpeg;*.tiff;*.tiff;*.png";
string source_path = "";
string target_path = "";
Face68Landmarks detect_68landmarks;
private void button2_Click(object sender, EventArgs e)
{
OpenFileDialog ofd = new OpenFileDialog();
ofd.Filter = fileFilter;
if (ofd.ShowDialog() != DialogResult.OK) return;
pictureBox1.Image = null;
source_path = ofd.FileName;
pictureBox1.Image = new Bitmap(source_path);
}
private void button3_Click(object sender, EventArgs e)
{
OpenFileDialog ofd = new OpenFileDialog();
ofd.Filter = fileFilter;
if (ofd.ShowDialog() != DialogResult.OK) return;
pictureBox2.Image = null;
target_path = ofd.FileName;
pictureBox2.Image = new Bitmap(target_path);
}
private void button1_Click(object sender, EventArgs e)
{
if (pictureBox1.Image == null || pictureBox2.Image == null)
{
return;
}
button1.Enabled = false;
Application.DoEvents();
Mat source_img = Cv2.ImRead(source_path);
List<Bbox> boxes= new List<Bbox>();
string boxesStr = "[{\"xmin\":261.8998,\"ymin\":192.045776,\"xmax\":821.1629,\"ymax\":936.720032}]";
boxes = JsonConvert.DeserializeObject<List<Bbox>>(boxesStr);
int position = 0; //一张图片里可能有多个人脸,这里只考虑1个人脸的情况
List<Point2f> face68landmarks = detect_68landmarks.detect(source_img, boxes[position]);
//绘图
foreach (Point2f item in face68landmarks)
{
Cv2.Circle(source_img, (int)item.X, (int)item.Y, 8, new Scalar(0, 255, 0), -1);
}
pictureBox1.Image = source_img.ToBitmap();
Mat target_img = Cv2.ImRead(target_path);
boxesStr = "[{\"xmin\":413.807,\"ymin\":1.377529,\"xmax\":894.659,\"ymax\":645.6737}]";
boxes = JsonConvert.DeserializeObject<List<Bbox>>(boxesStr);
position = 0; //一张图片里可能有多个人脸,这里只考虑1个人脸的情况
List<Point2f> target_landmark_5;
target_landmark_5 = detect_68landmarks.detect(target_img, boxes[position]);
//绘图
foreach (Point2f item in target_landmark_5)
{
Cv2.Circle(target_img, (int)item.X, (int)item.Y, 8, new Scalar(0, 255, 0), -1);
}
pictureBox2.Image = target_img.ToBitmap();
button1.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
detect_68landmarks = new Face68Landmarks("model/2dfan4.onnx");
// 堆代码 duidaima.com
target_path = "images/target.jpg";
source_path = "images/source.jpg";
pictureBox1.Image = new Bitmap(source_path);
pictureBox2.Image = new Bitmap(target_path);
}
}
}
Face68Landmarks.cs
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
using OpenCvSharp;
using System;
using System.Collections.Generic;
using System.Linq;
namespace FaceFusionSharp
{
internal class Face68Landmarks
{
float[] input_image;
int input_height;
int input_width;
Mat inv_affine_matrix = new Mat();
SessionOptions options;
InferenceSession onnx_session;
public Face68Landmarks(string modelpath)
{
input_height = 256;
input_width = 256;
options = new SessionOptions();
options.LogSeverityLevel = OrtLoggingLevel.ORT_LOGGING_LEVEL_INFO;
options.AppendExecutionProvider_CPU(0);// 设置为CPU上运行
// 创建推理模型类,读取本地模型文件
onnx_session = new InferenceSession(modelpath, options);
}
void preprocess(Mat srcimg, Bbox bounding_box)
{
float sub_max = Math.Max(bounding_box.xmax - bounding_box.xmin, bounding_box.ymax - bounding_box.ymin);
float scale = 195.0f / sub_max;
float[] translation = new float[] { (256.0f - (bounding_box.xmax + bounding_box.xmin) * scale) * 0.5f, (256.0f - (bounding_box.ymax + bounding_box.ymin) * scale) * 0.5f };
//python程序里的warp_face_by_translation函数////
Mat affine_matrix = new Mat(2, 3, MatType.CV_32FC1, new float[] { scale, 0.0f, translation[0], 0.0f, scale, translation[1] });
Mat crop_img = new Mat();
Cv2.WarpAffine(srcimg, crop_img, affine_matrix, new Size(256, 256));
//python程序里的warp_face_by_translation函数////
Cv2.InvertAffineTransform(affine_matrix, inv_affine_matrix);
Mat[] bgrChannels = Cv2.Split(crop_img);
for (int c = 0; c < 3; c++)
{
bgrChannels[c].ConvertTo(bgrChannels[c], MatType.CV_32FC1, 1 / 255.0);
}
Cv2.Merge(bgrChannels, crop_img);
foreach (Mat channel in bgrChannels)
{
channel.Dispose();
}
input_image = Common.ExtractMat(crop_img);
crop_img.Dispose();
}
internal List<Point2f> detect(Mat srcimg, Bbox bounding_box)
{
preprocess(srcimg, bounding_box);
Tensor<float> input_tensor = new DenseTensor<float>(input_image, new[] { 1, 3, input_height, input_width });
List<NamedOnnxValue> input_container = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor("input", input_tensor)
};
var ort_outputs = onnx_session.Run(input_container).ToArray();
float[] pdata = ort_outputs[0].AsTensor<float>().ToArray(); //形状是(1, 68, 3), 每一行的长度是3,表示一个关键点坐标x,y和置信度
int num_points = 68;
List<Point2f> face_landmark_68 = new List<Point2f>();
for (int i = 0; i < num_points; i++)
{
face_landmark_68.Add(new Point2f((float)(pdata[i * 3] / 64.0 * 256.0), (float)(pdata[i * 3 + 1] / 64.0 * 256.0)));
}
var face_landmark_68_Points = new Mat(face_landmark_68.Count, 1, MatType.CV_32FC2, face_landmark_68.ToArray());
Mat face68landmarks_Points = new Mat();
Cv2.Transform(face_landmark_68_Points, face68landmarks_Points, inv_affine_matrix);
Point2f[] face68landmarks;
face68landmarks_Points.GetArray<Point2f>(out face68landmarks);
//python程序里的convert_face_landmark_68_to_5函数////
Point2f[] face_landmark_5of68 = new Point2f[5];
float x = 0, y = 0;
for (int i = 36; i < 42; i++) // left_eye
{
x += face68landmarks[i].X;
y += face68landmarks[i].Y;
}
x /= 6;
y /= 6;
face_landmark_5of68[0] = new Point2f(x, y); // left_eye
x = 0;
y = 0;
for (int i = 42; i < 48; i++) // right_eye
{
x += face68landmarks[i].X;
y += face68landmarks[i].Y;
}
x /= 6;
y /= 6;
face_landmark_5of68[1] = new Point2f(x, y); // right_eye
face_landmark_5of68[2] = face68landmarks[30]; // nose
face_landmark_5of68[3] = face68landmarks[48]; // left_mouth_end
face_landmark_5of68[4] = face68landmarks[54]; // right_mouth_end
//python程序里的convert_face_landmark_68_to_5函数////
return face_landmark_5of68.ToList();
}
}
}
C++代码
我们顺便看一下C++代码face68landmarks的实现,方便对比学习。
face68landmarks.h
# ifndef DETECT_FACE68LANDMARKS
# define DETECT_FACE68LANDMARKS
#include <fstream>
#include <sstream>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
//#include <cuda_provider_factory.h> ///如果使用cuda加速,需要取消注释
#include <onnxruntime_cxx_api.h>
#include"utils.h"
class Face68Landmarks
{
public:
Face68Landmarks(std::string modelpath);
std::vector<cv::Point2f> detect(cv::Mat srcimg, const Bbox bounding_box, std::vector<cv::Point2f> &face_landmark_5of68);
private:
void preprocess(cv::Mat img, const Bbox bounding_box);
std::vector<float> input_image;
int input_height;
int input_width;
cv::Mat inv_affine_matrix;
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "68FaceLandMarks Detect");
Ort::Session *ort_session = nullptr;
Ort::SessionOptions sessionOptions = Ort::SessionOptions();
std::vector<char*> input_names;
std::vector<char*> output_names;
std::vector<std::vector<int64_t>> input_node_dims; // >=1 outputs
std::vector<std::vector<int64_t>> output_node_dims; // >=1 outputs
Ort::MemoryInfo memory_info_handler = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
};
#endif
face68landmarks.cpp
#include "face68landmarks.h"
using namespace cv;
using namespace std;
using namespace Ort;
Face68Landmarks::Face68Landmarks(string model_path)
{
/// OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); ///如果使用cuda加速,需要取消注释
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
/// std::wstring widestr = std::wstring(model_path.begin(), model_path.end()); ////windows写法
/// ort_session = new Session(env, widestr.c_str(), sessionOptions); ////windows写法
ort_session = new Session(env, model_path.c_str(), sessionOptions); ////linux写法
size_t numInputNodes = ort_session->GetInputCount();
size_t numOutputNodes = ort_session->GetOutputCount();
AllocatorWithDefaultOptions allocator;
for (int i = 0; i < numInputNodes; i++)
{
input_names.push_back(ort_session->GetInputName(i, allocator)); /// 低版本onnxruntime的接口函数
////AllocatedStringPtr input_name_Ptr = ort_session->GetInputNameAllocated(i, allocator); /// 高版本onnxruntime的接口函数
////input_names.push_back(input_name_Ptr.get()); /// 高版本onnxruntime的接口函数
Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_node_dims.push_back(input_dims);
}
for (int i = 0; i < numOutputNodes; i++)
{
output_names.push_back(ort_session->GetOutputName(i, allocator)); /// 低版本onnxruntime的接口函数
////AllocatedStringPtr output_name_Ptr= ort_session->GetInputNameAllocated(i, allocator);
////output_names.push_back(output_name_Ptr.get()); /// 高版本onnxruntime的接口函数
Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_node_dims.push_back(output_dims);
}
this->input_height = input_node_dims[0][2];
this->input_width = input_node_dims[0][3];
}
void Face68Landmarks::preprocess(Mat srcimg, const Bbox bounding_box)
{
float sub_max = max(bounding_box.xmax - bounding_box.xmin, bounding_box.ymax - bounding_box.ymin);
const float scale = 195.f / sub_max;
const float translation[2] = {(256.f - (bounding_box.xmax + bounding_box.xmin) * scale) * 0.5f, (256.f - (bounding_box.ymax + bounding_box.ymin) * scale) * 0.5f};
////python程序里的warp_face_by_translation函数////
Mat affine_matrix = (Mat_<float>(2, 3) << scale, 0.f, translation[0], 0.f, scale, translation[1]);
Mat crop_img;
warpAffine(srcimg, crop_img, affine_matrix, Size(256, 256));
////python程序里的warp_face_by_translation函数////
cv::invertAffineTransform(affine_matrix, this->inv_affine_matrix);
vector<cv::Mat> bgrChannels(3);
split(crop_img, bgrChannels);
for (int c = 0; c < 3; c++)
{
bgrChannels[c].convertTo(bgrChannels[c], CV_32FC1, 1 / 255.0);
}
const int image_area = this->input_height * this->input_width;
this->input_image.resize(3 * image_area);
size_t single_chn_size = image_area * sizeof(float);
memcpy(this->input_image.data(), (float *)bgrChannels[0].data, single_chn_size);
memcpy(this->input_image.data() + image_area, (float *)bgrChannels[1].data, single_chn_size);
memcpy(this->input_image.data() + image_area * 2, (float *)bgrChannels[2].data, single_chn_size);
}
vector<Point2f> Face68Landmarks::detect(Mat srcimg, const Bbox bounding_box, vector<Point2f> &face_landmark_5of68)
{
this->preprocess(srcimg, bounding_box);
std::vector<int64_t> input_img_shape = {1, 3, this->input_height, this->input_width};
Value input_tensor_ = Value::CreateTensor<float>(memory_info_handler, this->input_image.data(), this->input_image.size(), input_img_shape.data(), input_img_shape.size());
Ort::RunOptions runOptions;
vector<Value> ort_outputs = this->ort_session->Run(runOptions, this->input_names.data(), &input_tensor_, 1, this->output_names.data(), output_names.size());
float *pdata = ort_outputs[0].GetTensorMutableData<float>(); /// 形状是(1, 68, 3), 每一行的长度是3,表示一个关键点坐标x,y和置信度
const int num_points = ort_outputs[0].GetTensorTypeAndShapeInfo().GetShape()[1];
vector<Point2f> face_landmark_68(num_points);
for (int i = 0; i < num_points; i++)
{
float x = pdata[i * 3] / 64.0 * 256.0;
float y = pdata[i * 3 + 1] / 64.0 * 256.0;
face_landmark_68[i] = Point2f(x, y);
}
vector<Point2f> face68landmarks;
cv::transform(face_landmark_68, face68landmarks, this->inv_affine_matrix);
////python程序里的convert_face_landmark_68_to_5函数////
face_landmark_5of68.resize(5);
float x = 0, y = 0;
for (int i = 36; i < 42; i++) /// left_eye
{
x += face68landmarks[i].x;
y += face68landmarks[i].y;
}
x /= 6;
y /= 6;
face_landmark_5of68[0] = Point2f(x, y); /// left_eye
x = 0, y = 0;
for (int i = 42; i < 48; i++) /// right_eye
{
x += face68landmarks[i].x;
y += face68landmarks[i].y;
}
x /= 6;
y /= 6;
face_landmark_5of68[1] = Point2f(x, y); /// right_eye
face_landmark_5of68[2] = face68landmarks[30]; /// nose
face_landmark_5of68[3] = face68landmarks[48]; /// left_mouth_end
face_landmark_5of68[4] = face68landmarks[54]; /// right_mouth_end
////python程序里的convert_face_landmark_68_to_5函数////
return face68landmarks;
}
Python代码
face_68landmarks.py
import cv2
import numpy as np
import onnxruntime
from utils import warp_face_by_translation, convert_face_landmark_68_to_5
class face_68_landmarks:
def __init__(self, modelpath):
# Initialize model
session_option = onnxruntime.SessionOptions()
session_option.log_severity_level = 3
# self.session = onnxruntime.InferenceSession(modelpath, providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
self.session = onnxruntime.InferenceSession(modelpath, sess_options=session_option) ###opencv-dnn读取onnx失败
model_inputs = self.session.get_inputs()
self.input_names = [model_inputs[i].name for i in range(len(model_inputs))]
self.input_shape = model_inputs[0].shape
self.input_height = int(self.input_shape[2])
self.input_width = int(self.input_shape[3])
def preprocess(self, srcimg, bounding_box):
'''
bounding_box里的数据格式是[xmin. ymin, xmax, ymax]
'''
scale = 195 / np.subtract(bounding_box[2:], bounding_box[:2]).max()
translation = (256 - np.add(bounding_box[2:], bounding_box[:2]) * scale) * 0.5
crop_img, affine_matrix = warp_face_by_translation(srcimg, translation, scale, (256, 256))
# crop_img = cv2.cvtColor(crop_img, cv2.COLOR_RGB2Lab) ###可有可无
# if np.mean(crop_img[:, :, 0]) < 30:
# crop_img[:, :, 0] = cv2.createCLAHE(clipLimit = 2).apply(crop_img[:, :, 0])
# crop_img = cv2.cvtColor(crop_img, cv2.COLOR_Lab2RGB) ###可有可无
crop_img = crop_img.transpose(2, 0, 1).astype(np.float32) / 255.0
crop_img = crop_img[np.newaxis, :, :, :]
return crop_img, affine_matrix
def detect(self, srcimg, bounding_box):
'''
如果直接crop+resize,最后返回的人脸关键点有偏差
'''
input_tensor, affine_matrix = self.preprocess(srcimg, bounding_box)
# Perform inference on the image
face_landmark_68 = self.session.run(None, {self.input_names[0]: input_tensor})[0]
face_landmark_68 = face_landmark_68[:, :, :2][0] / 64
face_landmark_68 = face_landmark_68.reshape(1, -1, 2) * 256
face_landmark_68 = cv2.transform(face_landmark_68, cv2.invertAffineTransform(affine_matrix))
face_landmark_68 = face_landmark_68.reshape(-1, 2)
face_landmark_5of68 = convert_face_landmark_68_to_5(face_landmark_68)
return face_landmark_68, face_landmark_5of68
if __name__ == '__main__':
imgpath = '5.jpg'
srcimg = cv2.imread('5.jpg')
bounding_box = np.array([487, 236, 784, 624])
# Initialize face_68landmarks detector
mynet = face_68_landmarks("weights/2dfan4.onnx")
face_landmark_68, face_landmark_5of68 = mynet.detect(srcimg, bounding_box)
# print(face_landmark_5of68)
# Draw detections
for i in range(face_landmark_68.shape[0]):
cv2.circle(srcimg, (int(face_landmark_68[i,0]), int(face_landmark_68[i,1])), 3, (0, 255, 0), thickness=-1)
cv2.imwrite('detect_face_68lanmarks.jpg', srcimg)
winName = 'Deep learning face_68landmarks detection in ONNXRuntime'
cv2.namedWindow(winName, 0)
cv2.imshow(winName, srcimg)
cv2.waitKey(0)
cv2.destroyAllWindows()



 闽公网安备 35020302035485号
闽公网安备 35020302035485号





