中小规模的计数服务(万级)
本着 KISS(Keep It Simple and Stupid)原则,尽量将系统设计得简单易维护,所以可以采用缓存 + DB 的存储方案存储计数的数据,因为它是咱们最熟悉的,团队在运维上经验也会比较丰富。当计数变更时,先变更计数 DB,计数加 1,然后再变更计数缓存,修改计数存储的 Memcached 或 Redis。这种方案比较通用且成熟,但在高并发访问场景,支持不够友好。
大型互联网场景(百万级)
直接把计数全部存储在 Redis 中,通过 hash 分拆的方式,可以大幅提升计数服务在 Redis 集群的写性能,通过主从复制,在 master 后挂载多个从库,利用读写分离,可以大幅提升计数服务在 Redis 集群的读性能。而且 Redis 有持久化机制,不会丢数据。
但Redis方案有两个问题:
一方面 Redis 作为通用型存储来存储计数,内存存储效率低。以存储一个 key 为 long 型 id、value 为 4 字节的计数为例,Redis 至少需要 65 个字节左右,不同版本略有差异。但这个计数理论只需要占用 12 个字节即可。内存有效负荷只有 12/65=18.5%。如果再考虑一个 long 型 id 需要存 4 个不同类型的 4 字节计数,内存有效负荷只有 (8+16)/(65*4)= 9.2%。
另一方面,Redis 所有数据均存在内存,单存储历史千亿级记录,单份数据拷贝需要 10T 以上,要考虑核心业务上 1 主 3 从,需要 40T 以上的内存,再考虑多 IDC 部署,轻松占用上百 T 内存。就按单机 100G 内存来算,计数服务就要占用上千台大内存服务器。存储成本太高。
微博、微信、抖音
1.优化redis:定制数据结构,共享key 紧凑存储,提升计数有效负荷率。
2.超过阈值后数据保存到SSD硬盘,内存里存索引。
3.冷key从SSD硬盘中读取后,放入到LRU队列中。
4.自定义主从复制的方式,海量冷数据异步多线程并发复制。
微博实战
据称,微博系统中微博条目的数量早已经超过了千亿级别,仅仅计算微博的转发、评论、点赞、浏览等核心计数,其数据量级就已经在几千亿的级别。更何况微博条目的数量还在不断高速地增长,并且随着微博业务越来越复杂,微博维度的计数种类也可能会持续扩展(比如说增加了表态数),因此,仅仅是微博维度上的计数量级就已经过了万亿级别。除此之外,微博的用户量级已经超过了 10 亿,用户维度的计数量级相比微博维度来说虽然相差很大,但是也达到了百亿级别。
访问量大,对于性能的要求高。微博的日活用户超过 2 亿,月活用户接近 5 亿,核心服务(比如首页信息流)访问量级达到每秒几十万次,计数系统的访问量级也超过了每秒百万级别,而且在性能方面,它要求要毫秒级别返回结果。这就需要对原生 Redis 做一些改造,采用新的数据结构和数据类型来存储计数数据。在改造时,主要涉及两点:
一是原生的 Redis 在存储 Key 时是按照字符串类型来存储的,比如一个 8 字节的 Long 类型的数据,需要 8(sdshdr 数据结构长度)+ 19(8 字节数字的长度)+1(’\0’)=28 个字节,如果我们使用 Long 类型来存储就只需要 8 个字节,会节省 20 个字节的空间;
二是去除了原生 Redis 中多余的指针,如果要存储一个 KV 信息就只需要 8(weibo_id)+4(转发数)=12 个字节,相比之前有很大的改进。
在对原生的 Redis 做了改造之后,你还需要进一步考虑如何节省内存的使用。比如,微博的计数有转发数、评论数、浏览数、点赞数等等,如果每一个计数都需要存储 weibo_id,那么总共就需要 8(weibo_id)*4(4 个微博 ID)+4(转发数) + 4(评论数) + 4(点赞数) + 4(浏览数)= 48 字节。但是我们可以把相同微博 ID 的计数存储在一起,这样就只需要记录一个微博 ID,省掉了多余的三个微博 ID 的存储开销,存储空间就进一步减少了。
不过,即使经过上面的优化,由于计数的量级实在是太过巨大,并且还在以极快的速度增长,所以如果我们以全内存的方式来存储计数信息,就需要使用非常多的机器来支撑。
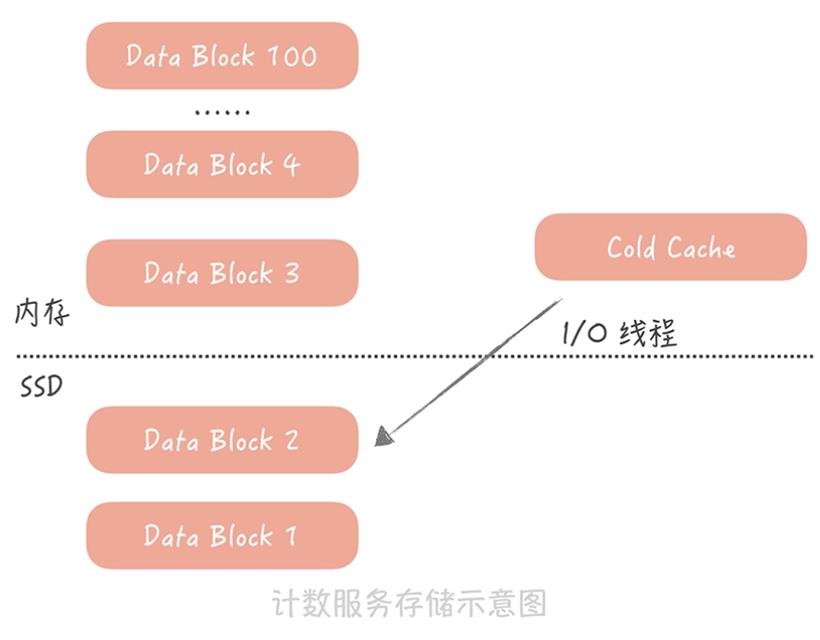
然而微博计数的数据具有明显的热点属性:越是最近的微博越是会被访问到,时间上久远的微博被访问的几率很小。所以为了尽量减少服务器的使用,我们考虑给计数服务增加 SSD 磁盘,然后将时间上比较久远的数据 dump 到磁盘上,内存中只保留最近的数据。当我们要读取冷数据的时候,使用单独的 I/O 线程异步地将冷数据从 SSD 磁盘中加载到一块儿单独的 Cold Cache 中。
 其他设计要点
其他设计要点
先做一个小小声明:本文部分内容来源于网络,由于不能确定真正源头没有标出处。
计数外置法是应对海量计数的常用手段。计数是一个通用的需求,有没有可能,这个计数的需求实现在一个通用的系统里,而不是由关注服务、粉丝服务、微博服务来分别来提供相应的功能呢?当然可能,各个业务系统具备的通用痛点,应该下沉统一解决。这种解决方案就叫计数外置法。
冷数据归档来做冷热分离可以提高热数据的性能。对数据库数据归档常用的存储系统是hbase。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






