阿联酋阿布扎比技术创新研究所(Technology Innovation Institute,简称TII)在官网发布了,目前性能最强的开源大语言模型之一Falcon 180B。TII表示,Falcon 180B拥有1800亿参数,使用4096个GPU在3.5万亿token 数据集上进行训练,这也是目前开源模型里规模最大的预训练数据集之一。Falcon 180B有基础和聊天两个模型,允许商业化。
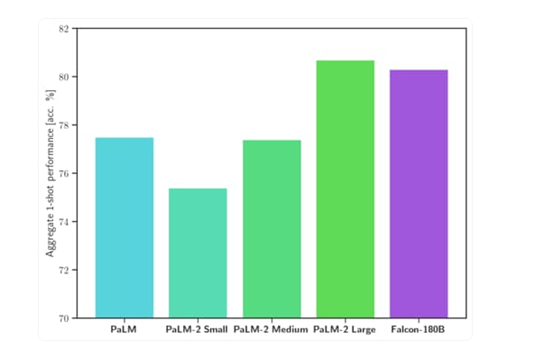
Falcon 180B在多个权威测试平台中,在推理、编程、知识测试等方面,超过了Meta最新发布的 Llama 2 70B 和 OpenAI 的 GPT-3.5,可媲美谷歌的PaLM 2-Large仅次于GPT-4。
基础开源地址:https://huggingface.co/tiiuae/falcon-180B
聊天开源地址:https://huggingface.co/tiiuae/falcon-180B-chat
在线测试地址:https://huggingface.co/spaces/tiiuae/falcon-180b-demo
今年5月,我们曾介绍过TII发布的一款类ChatGPT开源大语言模型Falcon-40B。该产品刚推出便成为Huggingface的开源大语言模型排行第一名,击败了LLaMa 65b、GPT4-X-Alpasta-30b、LLaMa 30b等众多著名开源项目成为一匹黑马。Falcon 180B便是在Falcon-40B基础之上研发而成,并将模型参数扩大了4.5倍,训练集从1万亿提升至3.5万亿token,并在算法、推理、硬件部署方面进行了大幅度优化。
其中,最大的亮点就是Falcon 180B- chat版本支持中文,并进行了数据微调。
Falcon 180B简单介绍
预训练方面,Falcon 180通过使用 Amazon SageMaker 在多达4096个GPU上同时对3.5万亿个token数据集进行训练,总共花费了约 7,000,000个小时。TII表示,Falcon 180B的规模是Llama 2的2.5 倍,而训练所需的算力资源是Llama 2的4倍。
Falcon 180B的训练数据集主要来自RefinedWeb的网络数据(大约占85%)。还在对话、技术论文和一小部分代码 (约占 3%) 等,经过整理的混合数据的基础上进行了训练。
Falcon 180B-chat模型在聊天和指令数据集上进行了微调,并混合了多个大规模对话数据集,使其能够更好地理解用户的文本提示意图,生成丝滑、流畅、拟人化的各种文本内容。
Falcon 180B性能评测
Falcon 180B在MMLU上的测试结果,优于Llama 2 70B 和 OpenAI 的 GPT-3.5;在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC等测试中,可媲美谷歌的PaLM 2-Large。
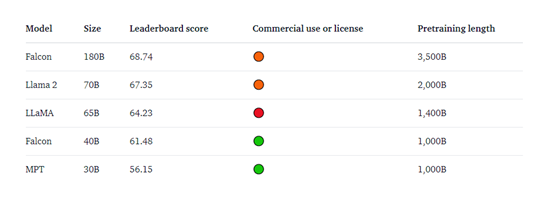
目前,Falcon 180B在Hugging Face排行榜上得分为68.74,是得分最高的公开发布的预训练大语言模型,超越了Meta的 LLaMA 2、LLaMA等。
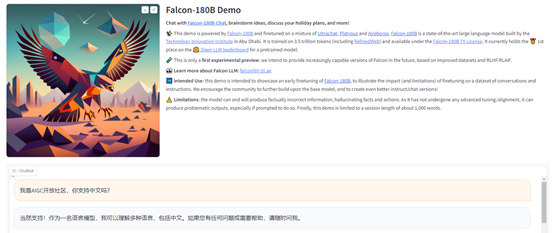
 Falcon 180B- chat使用体验
Falcon 180B- chat使用体验
我们通过在线demo体验了一下Falcon 180B- chat,使用方法和ChatGPT一样,中文生成的内容基本达到了GPT-3.5的效果,支持单话题,多轮深度询问。
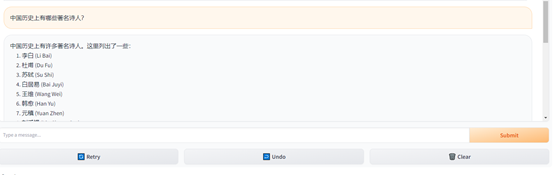
例如,询问,中国历史上有哪些著名诗人?Falcon 180B- chat可以按照罗列的方式,列出最知名的诗人。
让其详细介绍一下李白。

再介绍一下李白对现代人的影响。Falcon 180B- chat的整体回复内容非常丝滑、流畅。
 关于TII
关于TII
TII 成立于2020年,是阿布扎比高等教育和科技部 (ADEK) 旗下的研究机构。TII 的目标是推动科学研究、开发前沿技术并将其商业化,以促进阿布扎比和阿联酋的经济发展。
目前,TII拥有来自 74个国家的800多名研究专家,发表了 700 多篇论文和 25 多项专利,是世界领先的科学研究机构之一。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






