传说中谷歌(Google)用来和 ChatGPT 竞争的大模型—— Gemini,终于生了!一上来就是三种版本、多模态……但是万众瞩目的 Gemini,如果你真的比 ChatGPT 要强,为什么要在测评报告里玩文字游戏呢?
不太省的省流版介绍
首先,让无敌来为大家省个流,简单介绍一下谷歌口中 Gemini 的特点。毕竟完整技术报告实在是太长了:
多模态:识别图像和视频的能力优秀是 Gemini 本次最突出的优点。谷歌说:Gemini 这孩子啊,从小到大就是几种模态一起联合训练的,长大后又用额外的多模态数据进行了微调;不像某些模型,只是将纯文本、纯视觉和纯音频模型拼接在一起。我们可以实现跨文本、图像、音频视频甚至代码的无缝理解。
三种版本:从大到小分别是:Gemini Ultra、Pro、Nano。
最强性能:Gemini Ultra 的性能优于如今所有的大模型,并且是第一个在 57 个学科上超越人类专家的 AI 模型。(注意,这个版本还没上线,实际今天只能通过 Bard 使用 Gemini Pro。)
新的芯片:谷歌还发布了新的用于训练大模型的芯片 Cloud TPU v5p,据说性能是上一代的 2.8 倍。
如下图,(谷歌展示出的)Gemini 对视频的实时交互表现的非常优秀。
 大模型的事,怎么能叫文字游戏呢
大模型的事,怎么能叫文字游戏呢
但实际上的 Gemini 真的有谷歌说的这么优秀吗?全方位吊打 ChatGPT?让我们来看一下:
首先,谷歌掏出三款 Gemini 排在桌案上说:“要一个最强 AI 的称号。”
网友们笑他:“谷歌!你测评报告又作假了!”
谷歌在将 Gemini 跟 GPT-4 对比的时候,悄悄的给自家产品带了位天才枪手:Gemini 用的是 CoT(思维链,可以显著提升推理能力),测试了 32 次选取最好的结果,而 GPT-4 只用 few-shot 测了 5 次。偏心的离谱。

所谓的“超越人类专家”配图也很离谱:比例尺歪的吓人,90.0%与人类基准 89.8%明明只差一点,y 轴上却拉开很远。有热心网友按照正常的比例尺还原了一下,大家可以对比看看。(上为谷歌原图,下为还原后。)

谷歌瞪大眼睛:“怎么这样污人清白……”网友又道:“什么清白?我亲眼看到你的视频是剪切的,实际用的是静态图片!”
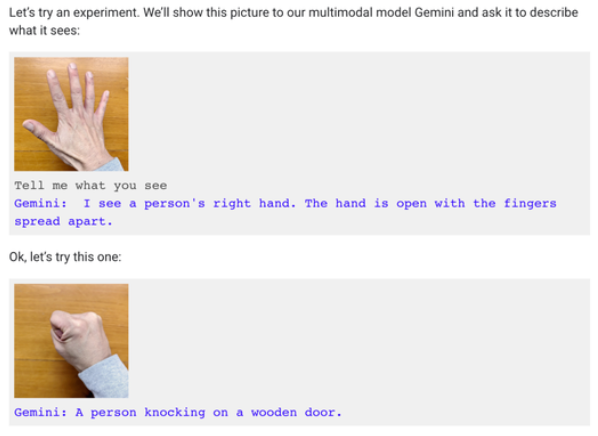
网友们在谷歌发布的一份文章中找到了真正的交互过程:可以说是在逐帧逐句的诱导,和视频中的表现相差甚远。
谷歌便涨红了脸,额上的青筋条条绽出,争辩道,“择优……择优的事情怎么能叫剪辑?”接连便是掏出了免责声明,什么“图片是一系列的”,引得众人都哄笑起来:互联网上充满了快活的空气。

上图为谷歌的免责声明:"我们一直在测试我们的新多模态 AI 模型 Gemini 的能力。我们一直在捕捉影片来对它进行广泛的挑战测试,展示一系列图片,并询问它对所看到的内容进行推理。"
虽败犹荣!虽败犹荣?
虽然谷歌的测试闹出了很多笑话,但毕竟作为 Ilya (OpenAI 首席科学家)的老东家、AI 领域曾经的巨头;好歹是在这次科技巨头们的 AI 竞赛中存活下来了,让大家看到了或许 OpenAI 和微软不会一家独大的希望。不知道 OpenAI 现在作何感想,但是无敌只希望各位大模型的价格能再打下来!Gemini 这场大戏你怎么看?还会给 ChatGPT-4 续费吗?


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





