Llama 3 正式发布了,Meta 称其为有史以来最强大的开源大模型。本次发布的包括预训练及指令精细调优的语言模型,拥有 80 亿和 700 亿两种参数规模,能够支持更多的应用场景。新一代的 Llama 在多个行业基准测试中展现了其领先的性能,并带来了包括推理能力提升在内的新功能。Meta 坚信,这些是同类产品中最优秀的开源模型。
一.Llama 3 的宏大目标
通过 Llama 3,Meta 的目标是打造一系列开源模型,这些模型不仅能与市场上最优秀的专有模型匹敌,还在整体帮助性上根据开发者的反馈进行了提升。
Meta 致力于在负责任地使用和部署 LLM 方面继续发挥领导作用。Meta 坚持开源的原则,即 “尽早发布,频繁更新”,让社区在模型还在开发阶段就能够获取并使用这些模型。Meta 今天推出的文本模型是 Llama 3 系列中的初代产品。Meta 未来的目标是让 Llama 3 支持多语言和多模态交互,提供更长的对话上下文,并在推理和编程等核心能力上持续优化和提升性能。
二.性能最优
今天发布的新型 80 亿和 700 亿参数的 Llama 3 模型比 Llama 2 有大幅度进步,Llama 3 重新定义了 LLM 在这一规模上的最高标准。通过在预训练和后续训练过程中的持续改进,目前 Llama 3 已经成为市场上同样规模参数产品中的佼佼者。后训练流程的优化显著减少了误拒率,提高了模型的对齐性,并丰富了回应的多样性。在推理、代码生成和指令执行等能力上也有明显提升,使得 Llama 3 的更易使用。
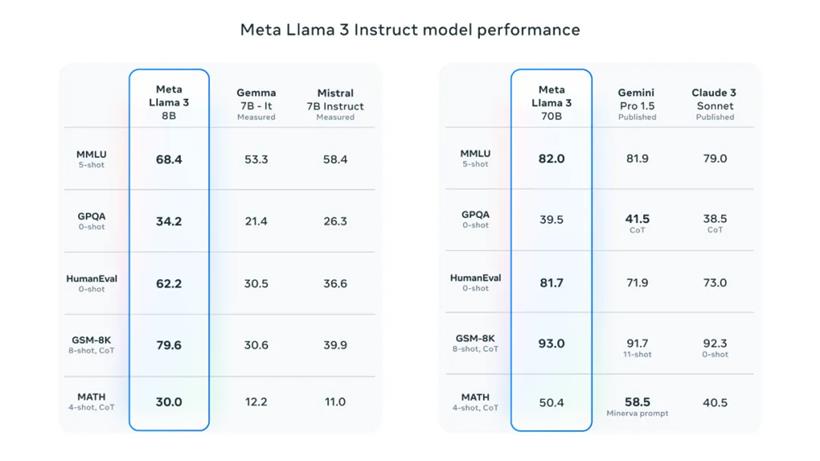
在开发 Llama 3 的过程中,Meta 不仅评估了模型在标准基准测试上的表现,还专注于优化其在真实世界场景中的表现。为此,他们特别设计了一个高质量的人工评估集,包括 1800 个针对 12 种关键应用场景的提示,如提供建议、创意构思、分类、闭环问答、编程、创意写作、信息提取、角色扮演、开放式问答、推理、文本重写及内容总结等。
为防止模型过度适应这一评估集,即使他们自己的模型开发团队也无法接触到这些数据。下方的图表展示了 Llama 3 在这些类别和场景中的综合人工评估结果,并与 Claude Sonnet、Mistral Medium 和 GPT-3.5 等竞争模型进行了比较。
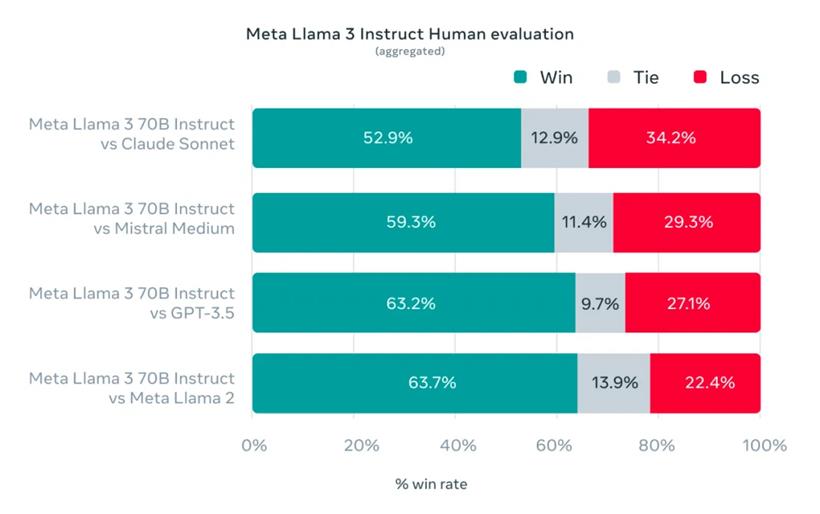
根据这一评估集的人工评分,Llama 3 700 亿参数模型在真实场景中的表现显著优于其他同等规模的竞争模型。
Llama 3 的预训练模型也在这些规模上树立了新的行业标杆。
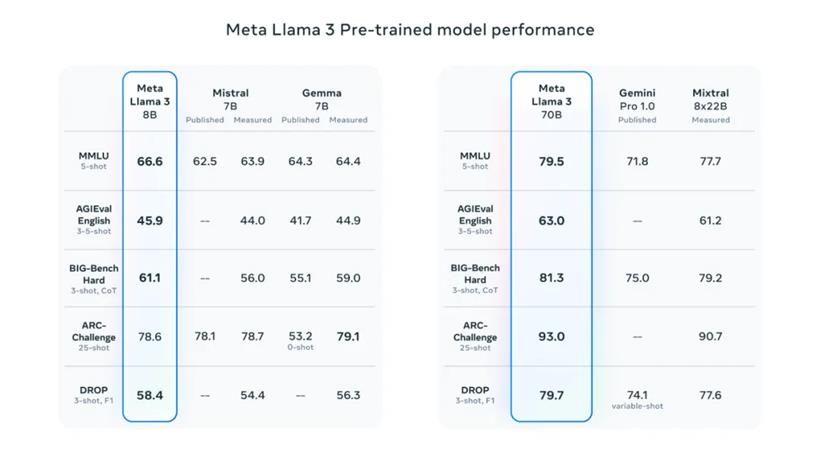
为了打造出色的语言模型,Meta 坚信创新、规模扩张及简化优化至关重要。在 Llama 3 项目设计中,始终围绕模型架构、预训练数据、预训练的扩展及指令精细调优这四大核心要素。
三.模型架构解析
在遵循 Meta 的设计理念的基础上,他们为 Llama 3 选择了一种相对标准的仅解码器 Transformer 架构。相比之下,Llama 3 在几个关键方面进行了改进。它使用了一个拥有 128K Token 的分词器,这大大提高了语言编码的效率,进而大幅提升了模型的整体性能。为了提升 Llama 3 的推理效率,在 80 亿和 700 亿参数的模型上实施了分组查询注意力机制。这些模型在 8192 Token 的序列上进行训练,通过使用掩码来确保处理过程中不会跨越文档边界。
四.高质量的训练数据
要培养出顶尖的语言模型,精心构建一个大型且高质量的训练数据集是至关重要的。Llama 3 的预训练涵盖了超过 15 万亿 Token,全部来源于公开可获取的数据。这个数据集是 Llama 2 使用的数据集的七倍之大,包含的编程数据是四倍之多。考虑到即将支持的多语言场景,超过 5% 的预训练数据包括了 30 多种语言的高质量非英语数据,虽然这些语言的表现可能不及英语。
为了保证 Llama 3 训练数据的高质量,Meta 开发了一系列数据过滤流程,包括启发式过滤、NSFW 过滤、语义去重及利用文本分类器预测数据质量。并且利用 Llama 2 来生成高质量的训练数据,为 Llama 3 提供了强大的支持。
Meta 还进行了很多实验,以评估在最终预训练数据集中混合不同来源数据的最佳方式。这些实验使 Meta 能够选择一个确保 Llama 3 在包括琐事问题、STEM、编程、历史知识等用例中表现良好的数据混合。
五.扩展预训练的探索
Meta 在扩大 Llama 3 预训练的过程中投入了大量的精力。制定了一系列详尽的扩展规则来评估模型在各种下游任务中的表现。这些规则帮助 Llama 3 选择最优的数据组合,并在使用训练计算资源时做出明智的决策。例如,尽管 80 亿参数模型理想的训练计算量是约 2000 亿 Token,但他们发现即使数据量增加了百倍,模型性能仍在持续提升。模型在经过 15 万亿 Token 的训练后,性能还在按对数线性递增。
为了训练规模最大的 Llama 3 模型,Meta 采用了数据并行、模型并行和流水线并行三种并行技术。在使用 16000 GPU 同时训练时,实现了每 GPU400 TFLOPS 以上的计算利用率。还在两个专门构建的 24000 GPU 集群上进行了训练,通过开发先进的训练系统,自动化了错误检测、处理和维护过程,大幅提升了硬件的可靠性和故障检测能力,发展了新的可扩展存储系统以减少数据检查点和回滚的开销。这些改进使得有效训练时间超过了 95%,从而使 Llama 3 的训练效率相比 Llama 2 提高了约三倍。
六.精细指令调优
为了最大限度地挖掘预训练模型在聊天应用中的潜力,Meta 也创新了指令调优的方法。后期的训练方法结合了监督式微调、拒绝采样、近邻策略优化和直接策略优化。这些训练阶段中使用的高质量提示和偏好排序对模型的表现产生了极大的影响。通过精心策划这些数据并对人工注释进行多轮质量检查,我们在模型质量上取得了显著进步。
通过偏好排序的学习也极大提高了 Llama 3 在推理和编码任务上的表现。实践中发现,当模型在处理复杂推理问题时遇到难题,它有时会展示出正确的推理过程:模型知道如何得出正确答案,却不知道如何作出选择。偏好排序的训练帮助模型学会了如何做出正确的选择。
七.构建 Llama 3
Meta 的愿景是让开发者能够根据具体需求定制 Llama 3,使其更容易采用,通过最佳实践促进开放生态系统的发展。此次的发布,提供了包括 Llama Guard 2 和 Cybersec Eval 2 在内的信任与安全工具,并推出了 Code Shield—— 一个在推理时期过滤不安全代码的保护机制。
Meta 还与 torchune 合作开发了 Llama 3,这是一个全新的 PyTorch 原生库,使得编写、微调及试验 LLM 变得简单。torchune 提供了一套完全基于 PyTorch 的高效且可定制的训练方案。该库已与 Hugging Face、Weights & Biases 和 EleutherAI 等流行平台集成,并支持在各种移动及边缘设备上高效执行推理的 Executorch。从提示工程到在 LangChain 中使用 Llama 3,官方也提供了一套全面的入门指南:https://llama.meta.com/get-started/
八.系统级的责任感
在设计 Llama 3 模型时,Meta 的目标是在确保行业领先的负责任部署方式的同时,最大化其实用性。为此,他们采纳了一种系统级的开发及部署策略。他们视 Llama 模型为更广泛系统的一部分,使开发者能够根据自己独特的目标进行设计。
在确保模型安全方面,指令微调也起着关键作用。Llama 3 模型已经通过了内部和外部的红队测试,以确保安全。他们的红队测试利用人类专家和自动化方法挑战模型,以识别和解决潜在的安全问题。例如,对化学、生物和网络安全等领域的潜在误用风险进行了全面评估。所有这些工作都是迭代进行的,并为模型的安全微调提供了数据支持。
Llama Guard 旨在为提示和响应的安全性提供基础,并可以根据应用需求轻松地进行微调以创建新的分类体系。例如,新推出的 Llama Guard 2 采用了最新公布的 MLCommons 分类法,旨在推动这一重要领域的行业标准化。此外,CyberSecEval 2 在原有基础上增加了新的安全措施,用于评估 LLM 在代码解释器滥用、网络攻击能力和抵抗提示注入攻击方面的表现。最后,引入了 Code Shield,增强了对 LLM 生成不安全代码的过滤能力,从而降低了相关安全风险。
随着生成式 AI 领域的快速发展,Meta 认为采用开放方式是促进生态系统整合并减少潜在风险的重要策略。作为这一策略的一部分,Meta 正在更新他们的负责任使用指南(RUG),为 LLM 的负责任开发提供全面指导。正如指南中所述,Meta 建议根据应用的内容指南检查并过滤所有输入和输出。此外,许多云服务提供商提供内容审核 API 及其他工具以支持负责任的部署,Meta 鼓励开发者考虑使用这些工具。
九.Llama 3 的大规模部署
Llama 3 很快将在包括云服务、模型 API 提供商在内的所有主要平台上推出。Llama 3 将无处不在。Meta 的基准测试表明,Llama 3 的分词器效率有明显提高,相比 Llama 2,Token 的使用减少了 15%。此外,他们也将分组查询注意力机制引入了 80 亿参数的 Llama 3 中。结果显示,尽管 Llama 3 比 Llama 2 的 70 亿参数版本多了 10 亿参数,但得益于更高效的分词器和分组查询注意力机制,它在推理效率上仍与 Llama 2 的 70 亿参数版本持平。
十.Llama 3 的未来展望
80 亿和 700 亿参数的 Llama 3 模型只是为 Llama 3 系列计划发布的众多模型中的开始,之后还将带来更多创新。
Meta 的大型模型参数超过了 4000 亿,虽然这些模型还在训练中,但团队对其发展趋势感到十分兴奋。在未来几个月,将推出具备多模态、多语言对话能力、更长上下文窗口和更强大功能的新模型。
为了提前展示这些模型的当前状态,他们分享了一些最大 LLM 模型的发展快照。请注意,这些数据来自 Llama 3 训练过程中的一个早期检查点,今天发布的模型尚不支持这些功能。
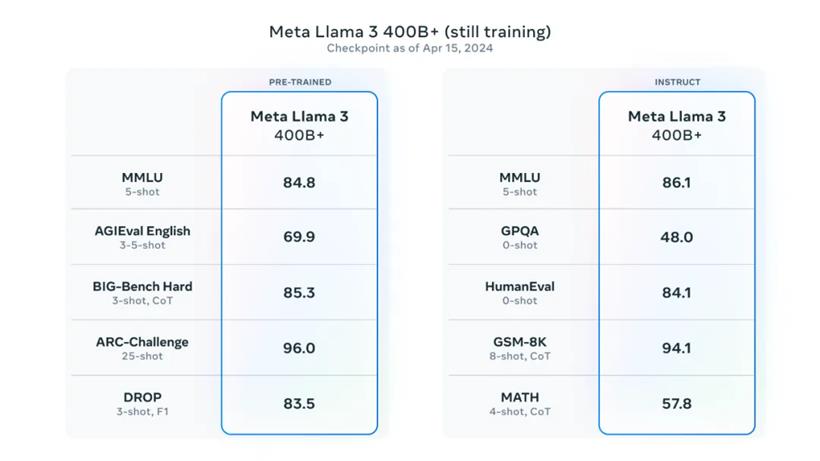
Meta 致力于持续推动一个开放的 AI 生态系统的成长和发展,并负责任地发布模型。他们坚信,开放可以带来更优秀、更安全的产品,并加速创新,有益于市场的整体健康。这不仅有利于 Meta,也有利于整个社会。
就在前几天的 Create 2024 百度 AI 开发者大会上李彦宏说,“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。所以,开源模型会越来越落后。”Llama 3 优秀的性能迅速打脸了李彦宏。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






