国内著名大模型平台智谱AI、清华大学联合开源了最新视觉大模型GLM-4.5V。根据测试数据显示,GLM-4.5V在图像理解、视觉智能体、长文档识别、代码等42项主流测试中创造了41项新记录。尤其是在视觉智能体提升巨大,全面超越了同类的Qwen2.5-VL、Kimi-VL-2506、Gemma-3等成为最佳视觉模型。
开源地址:
https://huggingface.co/zai-org/GLM-4.5V
API地址:
https://docs.z.ai/guides/vlm/glm-4.5v
GLM-4.5V架构简单介绍
GLM-4.5V是基于智谱之前发布的旗舰文本基座模型GLM-4.5-Air 之上开发而成,采用了一套独特且高效的架构体系,将视觉与语言处理紧密融合。主要由视觉编码器、MLP 适配器和语言解码器三大核心模块组成。视觉编码器是GLM-4.5V接触视觉信息的关键环节,承担着将图像、视频等视觉内容转化为模型能够理解的特征表示的重任。GLM-4.5V引入三维卷积技术以提升视频处理效率。
以往处理视频时,模型需要耗费大量时间和计算资源一帧一帧地分析,三维卷积能够让模型在处理视频时,同时考虑时间维度和空间维度的信息,这就像能一眼看穿视频在时间轴上的变化趋势以及每一帧内物体的空间关系,大大加快了处理速度。
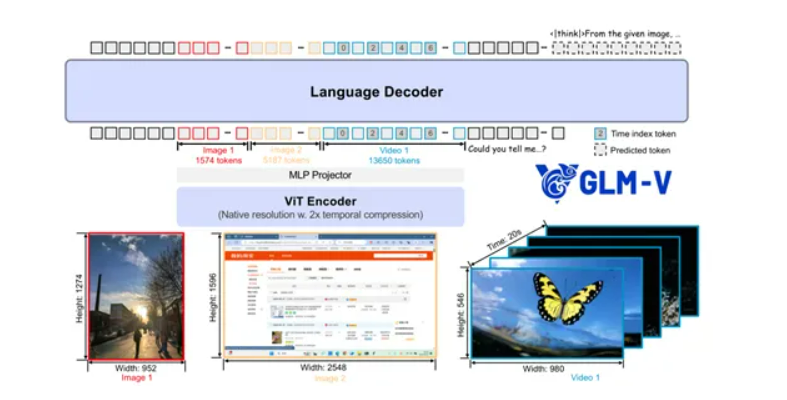
GLM-4.5V模型还支持64K tokens的多模态长上下文输入,可以处理长时间、复杂的视频序列或者超大幅面的图像。在面对高分辨率以及具有极端宽高比的图像时,它也展现出强大的处理能力和稳健性,不会因为图像的尺寸特殊或者细节过于丰富就容易出错。这得益于模型在设计上对图像特征提取和理解的深入考量,确保无论输入图像的形态如何,都能精准地捕捉到关键信息。
MLP适配器则像是视觉编码器与语言解码器之间的“翻译官”,起到桥梁的作用,将视觉编码器提取出的视觉特征,转换为能够与语言解码器顺畅对接的格式。通过巧妙的设计,MLP适配器能够有效地融合视觉和语言信息,让两者之间的沟通更加顺畅。能够理解视觉特征所代表的含义,并将其转化为语言解码器能够理解的语言,从而为后续的语言处理和推理工作做好铺垫。
语言解码器是GLM-4.5V进行信息处理和输出的关键模块,基于GLM-4.5-Air的强大语言处理能力,对经过MLP适配器转换后的信息进行深度分析和处理。在处理多模态信息时,为了更好地感知和推理三维空间关系,模型创新性地引入了三维旋转位置编码。
帮助GLM-4.5V在理解视觉信息中的空间位置、方向等要素时更加准确。例如,在描述一个物体在三维空间中的旋转、移动等动作时,模型能够借助三维旋转位置编码更清晰地把握其空间变化过程,进而更准确地进行语言表达和推理。在监督微调阶段,研究团队构建了一个高质量的长链推理数据集,涵盖多个领域,包括可验证任务和非可验证任务。这些数据集涵盖了广泛的领域知识,通过标准化的响应格式训练模型,使其能够以连贯、多步骤的方式解决问题。
在训练策略上,监督微调阶段采用全参数微调,序列长度为32,768,全局批量大小为32。训练数据包括多模态数据和高质量的长链推理文本数据,以保持模型的语言理解和推理能力。研究团队提出了强化学习与课程采样框架,通过动态调整训练样本的难度,确保每个更新步骤都能提供最大的信息量。还引入了动态采样扩展、更大的批量大小、丢弃KL损失等改进措施,以提高训练效率和稳定性。
测试数据
General VQA通用视觉问答领域是多模态大模型的基础任务之一,要求模型能够理解和回答与图像内容相关的问题。GLM-4.5V在多个通用视觉问答基准测试中表现出色,例如,MMBench-V1.1、MMStar、BLINK、MUIRBENCH、HallusionBench和ZeroBench。在MMBench-V1.1测试中,GLM-4.5V达到了88.2%的准确率,超越了其他开源模型,如Step-3-321B和Qwen2.5-VL-72B。
在科学、技术、工程和数学任务方面,GLM-4.5V 的表现非常出色。例如,在MMMU Pro 基准测试中,GLM-4.5V得分高达 65.2,而Step-3-321B 和 Qwen2.5-VL-72B 等强基线模型得分仅为 51.1;
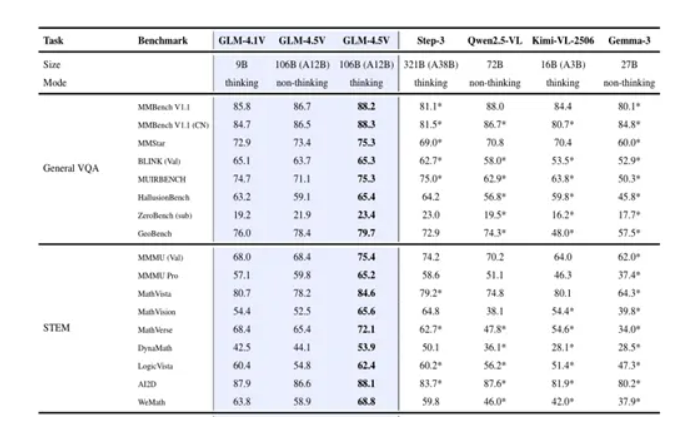
在MathVerse测试中,GLM-4.5V获得了72.1的分数,大幅超越了 Qwen2.5-VL-72B的 47.8;在WeMath基准测试中,GLM-4.5V以68.8的成绩领先于Qwen2.5-VL-72B的46.0 。这充分说明,在处理复杂的数学计算、物理化学原理应用等问题时,GLM-4.5V能够凭借其强大的推理能力和对多模态信息的综合处理能力,准确地找到问题的答案
在图表理解方面,GLM-4.5V同样表现出色。在ChartQAPro基准测试中,其得分达到了64.0,远远超过了Qwen2.5-VL-72B的46.7;在ChartMuseum测试里,GLM-4.5V获得了55.3的分数,而Qwen2.5-VL-72B仅为39.6。这表明GLM-4.5V能够精准地读取图表中的数据信息,理解图表所传达的含义,无论是柱状图、折线图还是饼图等各类常见图表,都能准确分析并回答相关问题。
长文档处理也是GLM-4.5V的优势领域之一。在MMLongBench-Doc基准测试中,GLM-4.5V取得了44.7的成绩,高于Qwen2.5-VL-72B的35.2。当面对长篇幅的文档内容,并且需要结合其中的图片等多模态信息进行理解和回答问题时,GLM-4.5V能够高效地梳理文档结构,提取关键信息,给出准确的答案,展现出了良好的长文本处理和多模态融合能力。
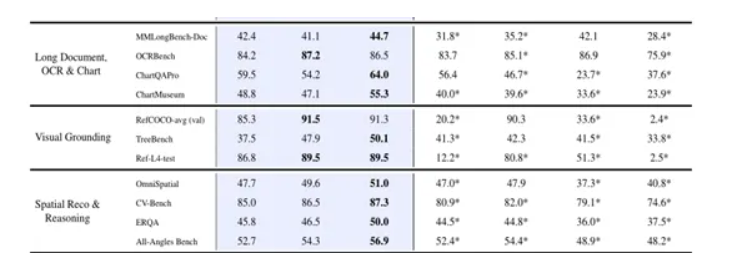
在空间推理方面,GLM-4.5V在ERQA基准测试中,以50.0的成绩领先于Qwen2.5-VL-72B的44.8,显示出其在理解图像中物体的空间位置、方向以及物体间的空间关系等方面具有更出色的推理能力。
在GUI智能体任务中,GLM-4.5V更是展现出了巨大的优势。在OSWorld基准测试里,它的得分是35.8,远远高于Qwen2.5-VL-72B的8.8;在WebVoyager测试中,GLM-4.5V获得了84.4的高分,而Qwen2.5-VL-72B仅为40.4。
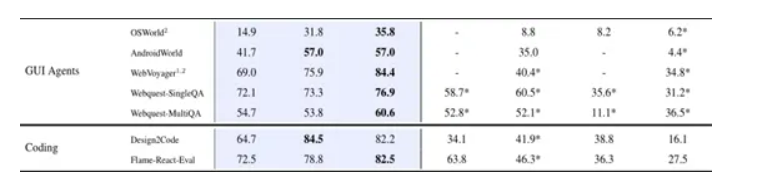
在编码相关任务中,GLM-4.5V在Design2Code基准测试里取得了84.5的成绩,大幅领先Qwen2.5-VL-72B的41.9;
在Flame-React-Eval测试中,GLM-4.5V的得分是82.5,高于Qwen2.5-VL-72B的46.3。这说明GLM-4.5V在理解设计意图并将其转化为代码实现等方面,有着更强大的能力。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






