12月15日,OpenAI在官网公布了最新研究论文和开源项目——如何用小模型监督大模型,实现更好的新型对齐方法。目前,大模型的主流对齐方法是RLHF(人类反馈强化学习)。但随着大模型朝着多模态、AGI发展,神经元变得庞大、复杂且难控制,RLHF便有点力不从心。
做个不太恰当的比喻,就像是工厂的保安一样:一个20人的小工厂,3个保安就能应付;如果发展到5000人的大工厂呢?仅靠人工就不太行,需要摄像头、智能门禁、温/湿传感器等设备,实现更高效的安全监控。
同理,OpenAI为了提升大模型的安全性,提出了“弱监督”的技术概念。并使用小参数的GPT-2去监督、微调GPT-4,同时使用辅助置信损失、无监督微调等增强方法,可以恢复GPT-4近80%的性能,达到GPT-3 和GPT-3.5之间的能力。
这表明,“弱监督”对齐方法是可行的。虽然目前还无法像RLHF那样拟人化、灵活,但这指明了一条全新对齐方向,用AI监督、微调AI,是未来提升大模型安全、性能的重要渠道之一。
开源地址:
https://github.com/openai/weak-to-strong
论文下载地址:
https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
此外,OpenAI还公布成立了一个1000万美元的“超级对齐”安全专款。主要用于研究大模型的超级对齐,深度研究“弱监督”技术等。个人开发者、研究机构、非盈利机构都能申请该奖金,申请流程非常方便简单。但需要在2024年2月18日之前完成申请。
申请地址:
https://airtable.com/appnIXmOlWAJBzrJp/paghnoKL6EHiKmKbf/form
由于OpenAI公布论文的内容太多,技术概念也比较复杂,我们就用简单易懂的方式为大家解读。
什么是RLHF
需要先简单介绍一下RLHF,以便更好地理解OpenAI提出的“弱监督”技术概念。RLHF的中文译为“人类反馈强化学习”,是一种结合人类指导和自动强化学习的训练方法。人类通过对AI的行为进行评价或指导,帮助其在学习过程中做出更好的决策。由于人类可以通过直觉、视觉和实践经验等来帮助AI,因此,应用RLHF的产品在拟人化方面获得大幅度提升。
简单来说,可以把RLHF看成是一种“妈妈教孩子”的的训练方法。AI相当于刚出生毫无经验的孩子,当他摔倒在地时,母亲(RLHF)会告诉他如何避免摔倒,以及更好的走路方法,孩子可以在这种不断反馈的学习环境中快速成长。
在过去的研究中,“强监督”一直被认为是训练智能模型的最佳方法,通过为模型提供准确的标签来监督其学习过程,RLHF便是最典型的应用。
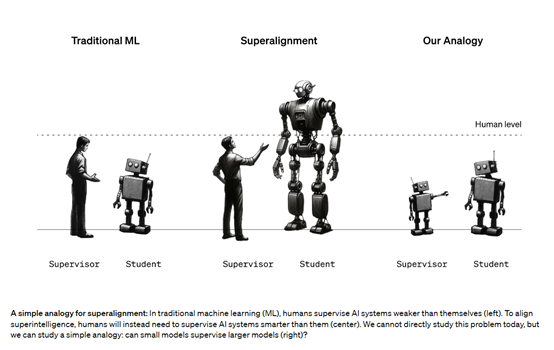
然而,这种方法存在一些限制和挑战。因为,获取准确的标签可能非常困难或耗费大量时间,同时对于一些复杂的任务,人类很难准确地定义标签或出现偏见。例如,最初的ChatGPT等产品会生成歧视内容,数据标签不准确是出现这个情况的主要原因之一。因此,OpenAI提出了“弱监督”,希望用AI替代人工来监督大模型的行为表现。
“弱监督”简单介绍
为了探索“弱监督”应用潜力,研究人员使用了一系列GPT-4系列语言模型,在NLP、国际象棋和奖励建模任务中进行了深度测试。惊奇发现,当使用弱模型生成的标签,对强预训练模型进行微调、指导时,强模型通常比弱监督模型表现更好,这一现象被称为“弱到强的泛化”。简单来说,就是老师教完学生知识,学生居然比老师还强大。
多种增强“弱监督”方法
但是仅通过简单的微调并不能充分发挥强模型的全部性能,因此,研究人员尝试了一些别的方法来改善弱到强的泛化效果,以匹配RLHF训练模型的能力。研究人员分别使用了辅助置信损失、中间模型的引导监督和无监督微调等方法。
辅助置信损失,主要用来更好地指导模型进行学习。例如,在处理具有噪声标签或不确定性很高的数据时,辅助损失可以帮助模型区分易于预测和难以预测的样本。中间模型的引导监督,可以作为一个桥梁,将弱模型的监督信号传递给强模型,帮助其更好地学习弱模型的知识和表现。无监督微调,可使强模型在没有标签监督的情况下进行微调,从而使其能够更好地适应新的任务和数据。
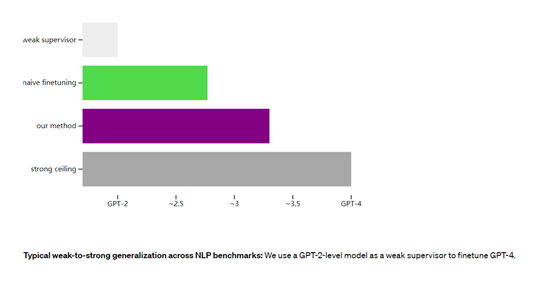
研究人员在NLP等测试任务中进行了实验,结果显示,使用GPT-2作为监督来微调GPT-4模型,并在上述增强功能的帮助下,性能差距仅有20%左右,达到了GPT-3 和GPT-3.5之间的能力。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






