随着全球急速向部署既高效又安全的 AI 模型迈进,开源 LLM 的需求急剧上升。开源和闭源的 AI 模型都被广泛采用,导致我们理解如何构建这些模型的能力已经远远落后。OLMo 的推出将为业界提供深入探索 AI 模型内部运作的窗口。
今日,艾伦人工智能研究所(AI2)发布了 OLMo 7B,这是一个完全开源的而且非常先进的 LLM,与之配套的还有预训练数据和训练代码,这在目前的开源模型中是独一无二的。这使得研究者和开发者能够利用顶尖的开源模型,共同推动语言模型科学的进步。
Meta 首席 AI 科学家 Yann LeCun 表示:“开放的基础模型对于激发生成式 AI 的创新和发展至关重要。开源社区的活力是构建 AI 未来最快、最高效的途径。”
OLMo 及其框架旨在支持研究人员训练和试验 LLM。它们可通过 Hugging Face 和 GitHub 直接下载,这得益于与哈佛大学的 Kempner 自然与人工智能研究所以及包括 AMD、芬兰科学 IT 中心(CSC)、华盛顿大学 Paul G. Allen 计算机科学与工程学院和 Databricks 等合作伙伴的合作。
Hugging Face:
https://huggingface.co/allenai/OLMo-7B
GitHub:
https://github.com/allenai/OLMo
该框架提供了一套完全开源的 AI 开发工具,涵盖了:
完整预训练数据:模型建立在 AI2 的 Dolma 数据集上,拥有三万亿的开放语料库用于语言模型预训练,包括生成这些训练数据的代码。
训练代码与模型权重:OLMo 框架为四种不同的模型变体提供了完整的模型权重,每种模型都至少经过了 2 万亿次 Token 的训练。此外,还提供了推理代码、训练指标和训练日志。
评估工具:我们发布了开发中使用的评估工具套件,每个模型包含超过 500 个检查点,每训练 1000 步就记录一次,评估工具套件还包括 Catwalk 项目下的评估代码。
在构建强大的开放模型过程中,AI2 借鉴了多个其他开放或部分开放模型的经验,整个项目期间将它们作为与 OLMo 竞争的基准进行了比较 —— 包括 EleutherAI 的 Pythia 套件、MosaicML 的 MPT 模型、TII 的 Falcon 模型以及 Meta 的 Llama 系列模型。
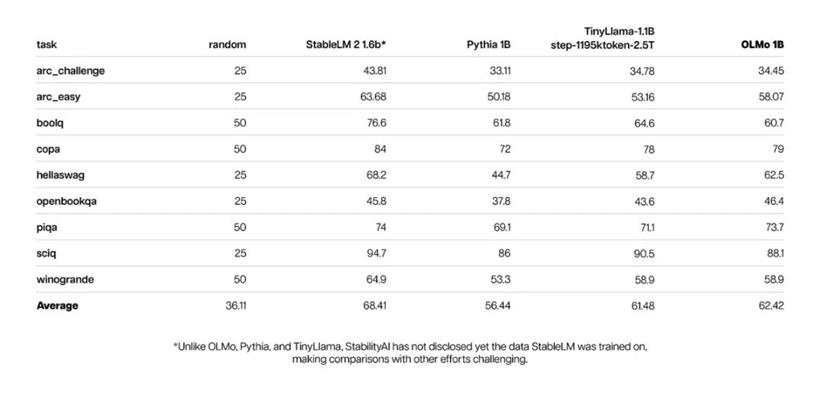
AI2 认为,OLMo 7B 模型是一个与众不同且性能出色的选择,相比于如 Llama 2 这样的热门模型,它在某些方面表现更优,在其他方面则可能有所不足。
下面展示了 OLMo 7B 与其同行模型的评估结果。前九项任务基于 AI2 当前对预训练模型进行的内部评估,而后三项任务则是为了使评估结果在 HuggingFace 的 Open LLM 排行榜上更加完整而加入的。值得注意的是,评估结果的下半部分涉及了不同的比较方法,因此并非所有的数据都能够进行一一对比。

在多个生成式任务或阅读理解(如 truthfulQA 这类任务)上,OLMo 7B 在性能上略微超越了 Llama 2。然而,在诸如 MMLU 或 Big-bench Hard 这样的知名问答任务上,OLMo 7B 的表现则略有不及。
对于 1B 版本的 OLMo 模型:
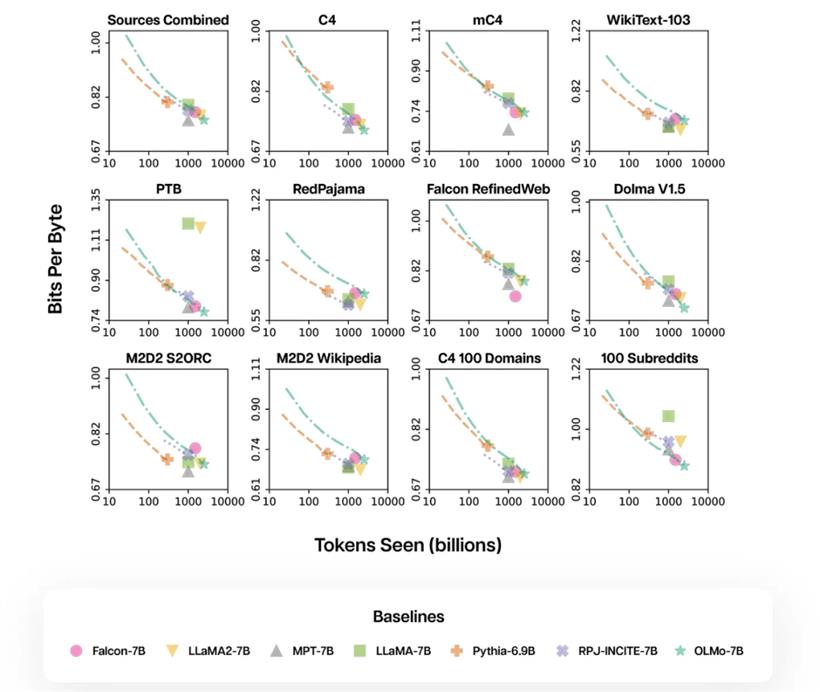
通过使用 AI2 的 Paloma 工具和 GitHub 上提供的代码检查点,AI2 探讨了模型在语言预测上的表现与其规模因素(例如,训练使用的 Token 数量)之间的联系。Paloma 的目标是通过从各个领域平等地抽样,更公平地反映出在 LLM 应用中可能接触到的广泛领域。这种方法与传统基于网页抓取的数据集(例如,由 Common Crawl 精选出的 C4 数据集)所混合的多领域数据进行评估的方式相比,提供了一种全新的视角。
如下所示,较低的 Bits per Byte(每字节位数)意味着更好的性能,OLMo 7B 在这方面与其他流行模型持平,而 Llama 模型则位于 OLMo 的训练轨迹之上。
AI2 在架构、数据处理,以及其他相关领域进行了众多实验,以打造出这个初版模型。模型架构采纳了近期研究中的多项技术,包括不使用偏置项(以增强模型的稳定性,如同 PaLM 中的做法)、采用了 PaLM 和 Llama 所用的 SwiGLU 激活函数、旋转位置嵌入(RoPE),以及一种从 GPT-NeoX-20B 改进而来的基于 BPE 的 Tokenizer,这种改进旨在减少模型处理数据时产生的个人可识别信息。
为了了解在模型开发过程中遇到的问题、考虑的模型架构,以及未来如何有效训练 LLM,建议阅读 OLMo 7B 技术报告:
https://allenai.org/olmo/olmo-paper.pdf
微软首席科学官兼 AI2 科学顾问委员会创始成员 Eric Horvitz 表示:“我非常期待 OLMo 能被 AI 研究人员所使用。这个新资源延续了艾伦 AI 提供宝贵开源模型、工具和数据的传统,这些资源已经推动了全球社区中的众多 AI 的发展。”
AI2 通过将 OLMo 及其训练数据完全公开,迈出了向合作打造世界上最佳开放语言模型的重要一步。在接下来的几个月中,AI2 将继续完善 OLMo,引入更多的模型大小、模态、数据集和功能。
“如今,许多语言模型发布时缺乏足够的透明度。研究人员如果没有访问训练数据,就无法科学地理解模型的工作机制。这就像在没有临床试验的情况下进行药物发现,或在没有望远镜的情况下研究太阳系一样。”OLMo 项目负责人、AI2 高级 NLP 研究主任及华盛顿大学艾伦学院教授 Hanna Hajishirzi 说。“通过我们的新框架,研究人员终于可以深入研究 LLM 的科学原理,这对于开发下一代安全可靠的 AI 至关重要。”
通过 OLMo,AI 研究人员和开发者将能够:
提高精度:完全了解模型背后的训练数据,研究人员可以更快地工作,无需再依赖对模型性能的感性判断,而是能够进行科学的测试。
减少碳排放:目前,一次模型训练的碳排放量相当于九个美国家庭一年的排放量。通过开放完整的训练和评估生态系统,我们大幅度减少了开发过程中的重复工作,这对于 AI 的碳减排至关重要。
实现持久成果:保持模型及其数据集开放,而不是封闭在 API 后面,使研究人员能够借鉴以往的模型和成果进行学习和构建。
“OLMo 真正实现了开放,这意味着 AI 研究社区的每个人都将能够全面接触到模型创建的所有方面,包括训练代码、评估方法和数据等,”OLMo 项目负责人、AI2 高级 NLP 研究主任以及华盛顿大学艾伦学院教授 Noah Smith 表示。“AI 曾是一个以开放研究社区为中心的领域,但随着模型规模的增加、成本的上升,并开始转向商业产品,AI 的开发逐渐转入了封闭的空间。通过 OLMo,我们希望逆转这一趋势,赋予研究社区以科学的方式更好地理解和参与语言模型的开发,引领更负责任的 AI 技术,使其惠及每一个人。”
AI2 在自然语言处理方面的深厚知识,加上 AMD 的高性能计算能力,使得在 AMD EPYC™ CPU 和 AMD Instinct™ 加速器支持下的 LUMI 超级计算机开发的 OLMo 模型,为 AI 的实验和创新提供了前所未有的扩展机会,推动了整个行业的发展。这个新的开放框架为全球 AI 研究社区提供了可靠的资源和一个平台,使他们能够直接对语言模型做出贡献。
——AMD AI 解决方案高级总监 Ian Ferreria
我们很高兴能够通过提供 LUMI 超级计算机的计算资源及我们的专业知识,为这一重要倡议做出贡献。公共超级计算机如 LUMI 在构建开放和透明的 AI 基础设施中发挥着关键作用。
——CSC 科学与技术总监 Pekka Manninen 博士
芬兰的 LUMI 超级计算机由 CSC 托管,由 EuroHPC 联合企业和 10 个欧洲国家共有,是欧洲最快的超级计算机,以完全无碳运营而著称,对 OLMo 的预训练工作提供了关键支持。
我们很高兴能与艾伦人工智能研究所合作发布他们的 OLMo 开源模型和框架。OLMo 为开放所代表的真正意义树立了新标准。无论是学术界、工业界还是更广泛的社区,都将从这种开放中获得巨大的收益,不仅仅是模型本身,还包括所有训练细节,如数据、代码和中间检查点。我特别自豪这个模型是在我们的 Mosaic AI 模型训练平台上开发的。正如所有伟大的开源发布一样,现在这些工具和资料已经交到了社区手中,最精彩的部分即将到来。
——Databricks 神经网络首席科学家 Jonathan Frankle


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






