

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

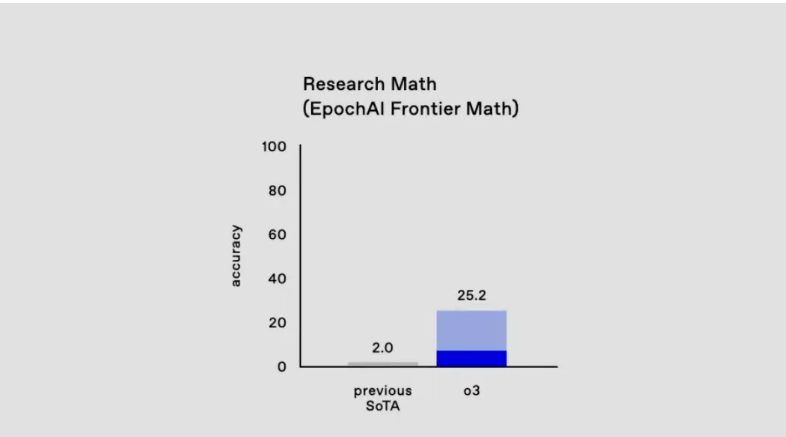
FrontierMath 是一个分量极重的高级数学推理能力评估基准。它由 Epoch AI 联手 60 多位顶级数学家共同打造,参与者包括多位菲尔兹奖得主和国际数学奥林匹克竞赛的资深命题人。该基准包含数百个原创且极具挑战性的数学问题,覆盖现代数学的多个主要分支,如数论、实分析、代数几何、范畴论等。2006 年菲尔兹奖得主、数学天才陶哲轩曾评价 FrontierMath 的问题「极其具有挑战性」,并认为这些问题只能由领域专家来解决。

本表明 o3 在高级数学推理方面有巨大进步的成绩单,却在承包商的爆料后迎来了风评反转。
面对争议,Epoch AI 副主任兼联合创始人之一 Tamay Besiroglu 很快在 X 平台承认了此事。我们犯了一个错误,没有更早披露 OpenAI 在 FrontierMath 中的参与。我们的合同在 o3 发布前禁止我们这么做。事后看来,我们确实应该更努力地争取更早的透明性。我们承认这一点,并承诺未来做得更好。事态进一步发酵,斯坦福大学数学博士生 Carina Hong 声称,在 Epoch AI 的安排下,OpenAI 拥有对 FrontierMath 的特权访问权。
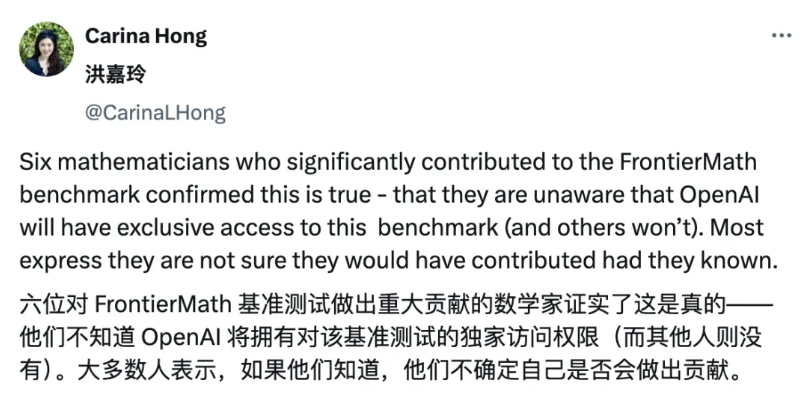
面对质疑声浪,Tamay Besiroglu 也通过博客表达歉意,承诺将在未来采用更高的透明度标准。博客强调 OpenAI 的资金支持仅限于 FrontierMath 的开发,并未干预测试内容,同时声明所有数据和问题均来自独立贡献者并经过独立专家审核。
关于训练使用:我们承认 OpenAI 确实可以访问大部分 FrontierMath 问题和解决方案,但不包括 OpenAI 无法访问的保留集,这使我们能够独立验证模型功能。此外,我们有一个口头协议,这些材料不会用于模型训练。相关 OpenAI 员工的公开沟通将 FrontierMath 描述为「严格保留」的评估集。虽然这种公开立场与我们的理解一致,但我还要进一步强调,实验室从拥有真正未受污染的数据集中获益匪浅。
[编辑:澄清了 OpenAI 的数据访问 - 他们无权访问作为独立验证额外保护措施的单独保留集。]
他将 OpenAI 的 o3 演示描述为一场「绝望的、操纵的、误导性的、科学上粗制滥造的展示」,认为这更像是一次过度炒作而非真实突破。一个生动的打比方是,如果有人提前获得了试题和答案,而其他人只能靠实力应考,这样的比较显然缺乏公平性。OpenAI 不仅获得了问题和解决方案的访问权,而其他竞争对手如 xai、DeepMind 以及学术团队却无法获得相同资源。
更重要的是,Gary Marcus 认为 OpenAI 对这一关键背景事实只字未提,同时也选择性地隐藏了关键信息。他们既未公布在具体问题上的成功与失败案例,也没有提供相应的推理过程记录,更未说明哪些问题出现在训练集中。同时,他们也没有允许 Epoch 对保留测试集进行验证。而回归到这场愈演愈烈的风波,很大程度上源于网友们对 OpenAI 无休止炒作的厌倦。疑似「造假」的行为,也再次触及了许多网友敏感的神经。





