半个月前,美团出人意料扔出了LongCat-Flash-Chat大模型。性能强悍,令人称赞。 升级版LongCat-Flash-Thinking又来了。通过精心设计的训练流程,从长思维链(CoT)数据冷启动到大规模强化学习(RL),实现了在复杂推理任务上的卓越表现,同时保持了极高的效率。
这模型什么来头?
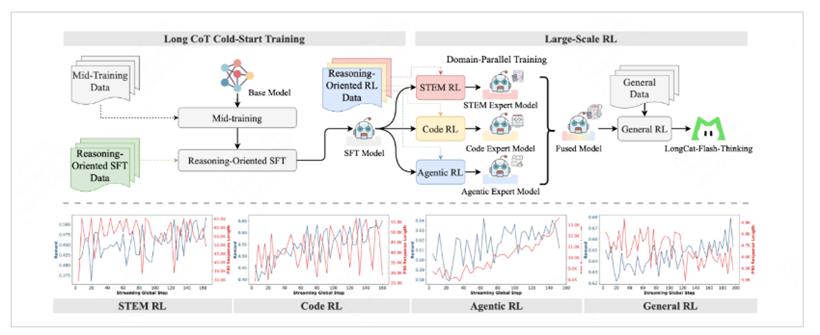
LongCat-Flash-Thinking模型的总参数量达到了5600亿,MoE架构,平均激活参数为270亿。团队设计了领域并行训练方案,将STEM、编程和智能体任务等不同领域的优化解耦,分别训练专家模型,然后将这些专家融合成一个接近帕累托最优的单一模型。这种方法不仅解决了传统混合领域RL训练的不稳定性,还使最终模型在各个专业领域都表现出色。
团队开发了DORA(Dynamic ORchestration for Asynchronous rollout)系统,这是一个大规模RL框架,在数万加速器上比同步方法实现了超过三倍的速度提升。该系统采用弹性共置和高效的KV缓存重用等创新特性,为RL训练提供了强大的工业级支持。LongCat-Flash-Thinking在广泛且高效的先进推理方面取得显著进展,特别是在形式证明和智能体推理等关键领域建立了明显优势。在AIME-25基准测试上,模型将平均token消耗减少了64.5%(从19,653降至6,965),同时保持了任务准确性。
训练过程主要分两步走。先冷启动,再强化学习。冷启动阶段的目的,是让模型先有基本的推理能力。因为通用语料里数学、编程这类推理密集型数据比例太少,更缺长链式推理的示例,模型天然短板。团队于是构建了高质量数据集,涵盖数理化和算法编程,经过严格清洗,大幅提升了模型在各类推理基准上的表现。
随后,通过监督微调进一步对齐推理方式:一方面广泛收集STEM、逻辑、编程和QA数据,让模型能遵循高质量的指令模式;另一方面在形式推理上,借助一个8B参数的自动形式化模型,把自然语言转成逻辑表达,并通过迭代扩展数据,逐步增强自动定理证明的能力;同时,他们还识别哪些问题确实需要外部工具辅助,再生成相应的解题轨迹,从而提升模型作为“智能体”时的推理深度。
等模型有了推理地基,就进入大规模强化学习。这一步是核心,也是难点:RL往往训练不稳、算力消耗巨大。团队专门设计了DORA系统,用解耦和流式架构提升效率,保证数万加速器几乎无闲置,整体速度比传统方式快三倍。算法上,他们改造了GRPO,针对异步场景去掉KL散度项,用更细粒度的token级损失,并通过裁剪和截断采样缓解分布漂移。
奖励机制则因任务而异:创意写作用判别模型,STEM任务用能解释过程的生成式奖励,编程任务则依托大规模沙盒集群并行运行上百万段代码。最后,通过“先分领域、再融合、再整体微调”的三阶段方案,把专家模型整合为一个稳健的通用智能体。
整体来看,这套两步走的方法,前半段像打地基,补足推理数据的稀缺,后半段则用精细化的RL系统把楼层拔高,让模型既能解数学题、写代码,也能在更广泛任务中展现稳定的推理力。
表现非常抢眼
LongCat-Flash-Thinking在各大权威评测中确实表现非常棒。在通用推理能力上,它在一个叫ARC-AGI的基准测试里,拿了50.3分,把OpenAI的o3、谷歌的Gemini2.5 Pro这些闭源的顶尖高手都甩在了身后。在数学能力上,它在MATH500这种测试里拿到了99.2分,在更难的HMMT和AIME数学竞赛相关的基准上,成绩更是超越了OpenAI o3,和另一个国产顶尖模型Qwen3-235B-A22B-Thinking水平相当。
在代码能力上,它在LiveCodeBench这个评估高难度编程竞赛能力的榜单上,拿了79.4分,不仅在开源模型里是第一,甚至和顶级的闭源模型GPT-5的表现差不多。在OJBench基准测试里,得分也很有竞争力,紧追Gemini2.5-Pro。在智能体能力,也就是调用工具解决复杂问题的能力上,它在一个叫τ2-Bench的测试里拿了平均分74.0,刷新了开源模型的记录。
最夸张的是它的ATP(自动定理证明)形式化推理能力。在一个叫MiniF2F-test的基准测试里,它的pass@1得分是67.6,这个分数可以说是一骑绝尘,把所有其他参与评估的模型都远远甩开了。这证明了它在生成结构化证明方面的绝对优势。安全性方面也做得不错,在有害内容、犯罪、错误信息和隐私保护等测试中,得分都在93分以上,说明模型有很强的“避坑”能力。
美团两次开源,就走在了开源大模型的前列。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






