

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

上个月,我被一则寻呼告警惊醒,同时看到 Slack 上一段关于生产环境重大故障的激烈讨论。我们的 AI 智能体输出工整、语法完美,却掩盖了一个极其严重的底层缺陷:智能体正在产生幻觉,并做出错误的业务决策。、问题并不在大语言模型本身。真正的原因是:智能体所依赖的底层知识图谱,与线上实时交易数据库完全不同步。
我所经历的这种问题,在行业内被称为 上下文退化(Context Rot),这是一种严重的架构缺陷,正在大量破坏长会话 AI 系统的稳定性。多项独立研究表明,模型会耗尽其注意力资源,且随着上下文长度增加,性能会显著下降。向量数据库厂商 Chroma 在 2025 年 7 月针对 18 个先进语言模型的研究发现:在上下文达到 32,000 token 时,12 个主流模型中有 11 个的准确率跌破基线水平的 50%。
斯坦福大学 2023 年的经典研究《Lost in the Middle》则证明,大模型呈现 U 型注意力分布:当关键事实被放在提示词中间位置时,准确率会从 75% 暴跌至 55%。此外,2025 年 10 月发表在 arXiv 的一项研究进一步证实:即便语义检索结果 100% 完美,单纯增加上下文长度本身就会带来巨大的 “认知负担”,会让准确率下降最高 13.9%。
检索增强生成(RAG)是一种旨在提升模型准确率的架构模式:它在模型接收提示时实时检索外部数据,从而避免幻觉。然而,在构建持续运行、自主循环的智能体系统时,如果从过时的向量数据库中拉取数据,后果将是灾难性的。
我很快意识到:企业级 AI 规模化落地,本质上是一个极度复杂的数据工程问题。RAG 失效通常不是因为大模型凭空产生幻觉,而是因为数据系统发生漂移。向量嵌入本质上是原始业务数据的物化视图。如果向量库无法实时反映策略更新、库存变动或记录删除,检索质量就会静默式退化。
Apache Iceberg v2 使用基于位置的删除文件,通过显式文件路径与行号追踪被删除的数据,并将其编码为体积庞大的 Parquet 文件。这导致了严重的写入放大与查询性能下降,因为引擎在执行查询时必须合并大量零散的删除文件。无数个夜晚,我都在排查脆弱的工作流、定制重试系统,以及 JVM 内存溢出的问题。
from pyspark import pipelines as dp
import pyspark.sql.functions as F
#堆代码 duidaima.com
@dp.table(name="raw_orders")
def raw_orders():
# 建立与Kafka事件流的持续连接
return spark.readStream.format("kafka").option("subscribe", "orders").load()
@dp.materialized_view(name="transformed_context")
def transformed_context():
# 声明式定义向量同步的目标状态
return spark.table("raw_orders").filter(F.col("status") == "COMPLETED")
对 AI 场景更重要的是,我用上了 SPARK-53736 引入的结构化流实时模式(Structured Streaming Real-Time Mode)。它跳过了传统的微批处理机制,对连续处理实现了亚秒级延迟,无状态任务的延迟更是做到了个位数毫秒。开启 spark.databricks.streaming.realTimeMode.enabled 后,引擎会启动长生命周期的流任务,并发调度执行阶段。数据通过流 Shuffle 在内存中的活动任务之间直接传递,彻底避开了传统磁盘 Shuffle 的延迟瓶颈。
这套现代化的执行流程,彻底解决了时间滞后导致的上下文退化问题:
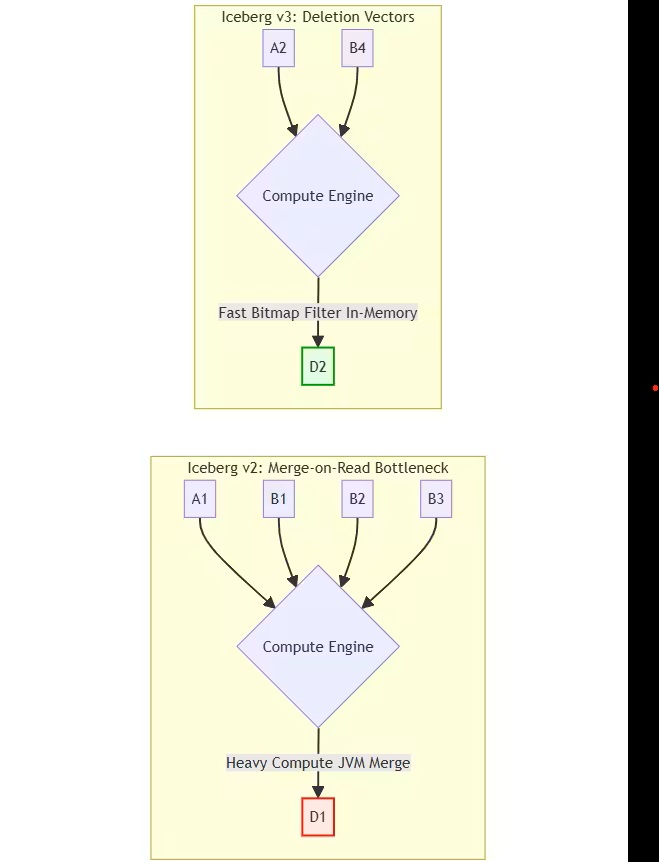
现在,写入时引擎只需要为每个数据文件、每个快照维护一个删除向量。当 Spark 流执行 CDC MERGE 操作时,引擎会在内存中把新增的删除操作,和已有的删除向量做逻辑合并,最后只生成一个更新后的 Puffin 文件。这彻底避开了原来 Parquet 文件和内存表示之间的转换开销。
存储成本和 S3 访问成本也大幅下降,因为新的删除向量会直接替换旧的,再也不会累积元数据垃圾。
# 堆代码 duidaima.com SELECT id, document_chunk, _row_id, _last_updated_sequence_number FROM myns.transformed_context WHERE _last_updated_sequence_number > :last_processed_sequence
只用按更新序号过滤,计算成本就被大幅降低,智能体的知识库也能和真实业务数据完全同步。





