我看过很多讲编程语言的书,大部分带着开发者入门的书,在讲基础类型系统的时候就讲一下范围然后一笔带过?我不是很理解,既然写都写了为什么不写全,还是作者自己就根本也不懂,东拼西凑写完一本得了那种,有和意义?本篇文章我整理一下,并且解释了基础类型和计算机存储关系,如果读者想了解更深刻建议读一本书《编码》,我没有收取任何广告费,我只是觉得不错,从电路设计,逻辑门开始讲解计算机原理。
数据类型
数据类型很多编程语言都是必备的,特别是一些静态的编译型语言,在编译期的时候就要确定数据类型,多数静态类型语言要求在使用变量之前必须声明数据类型,典型例子:Java、Go、Rust 等。
例如还有一些弱类型的语言,例如:PHP、JavaScript、Unix Shell等,这些对类型系统没有明确要求,动态语言是在运行时来确定数据类型的语言,变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
而强类型反而不一样,在使用的时候必须声明其类型,这样在编译的时候就知道内存占用大小,也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。
二者区别在于:强类型语言一旦被声明那么类型就是确定的,当然现在新语言例如Go和Rust可以自动根据上下文推断出类型,这个就看编译器智能化程度了,弱类型本身就是根据类型上下文确定的,当然有一个典型的例子就是JavaScript,一个变量的存储空间可以放到多种数据类型,准缺来说是没有类型概念,主要用于数据存储大小来分配的...所以后面微软推出了TypeScript,在js基础之上加入了类型系统,但是本身还是一个js超集;只是在编译的时候tsc编译器做了转换而已,在编写的时候可以限制开发者在起到类型约束作用,防止一些bug的产生,这些如果想深入研究大家可以自己去查看相关的书籍,我也是略知皮毛而已。
出现数据类型的原因,在早期计算机中,由机器语言转向高级语言时,原先由人工输入机器码交给计算机进行处理,转变为编译器处理数据,虽然将相应的变量编译为对应的机器码后,编译器并不会识别变量所代表的含义和类型。在斯坦福的课程,如果告诉一个人第一个数字是1,一般下一个数字就是2,但是如果是第一个数字是1.11,下一个数字就不知道到底是多少了,所以就要分类,所以就分了两种类型?所有如果在初始化的时候确定了类型,那就好说了, 在内存分配上,有了类型的定义以后,确定了变量的数据类型,数据的类型编码指令,大大的提高了计算机的处理速度,解决了内存分配大小的问题,避免了空间上的浪费。
存储和编码
在计算机内部数据运算都是基于二进制表示的,程序在运行的时候都是从外存加载到主层里面进行运算,那数据怎么表示的呢?

数据在底层存储都是以二进制存储的,也就是数据组成是0和1,这就是位的概念,每个二进制数字0或者1就是1个位。而byte字节是一个计量单位,表示数据量是多少。也就是8个位等于一个字节,字节用于计算机存储相关的计量容量单位,表示起来也比bit容易理解,下图为存储计量单位。

计算机的计算完全是靠着CPU工作,而CPU的寄存器存储单位是KB,当打开一个程序的时候程序二进制机器码文件就被加载到内存里面,这里的内存和CPU寄存器差了几个数量级单位,那这和编程语言有什么关系吗?我个人觉得和语言类型就有关系,当程序运行的时候还需要额外的内存辅助,变量就是,变量是有类型的,可以想象一下一个变量就是一个房子,房子大小取决于类型觉得,内存是有限的,当知道在运算的时候需要多少空间占用,那为何不确定内存大小呢?这就回到上面我所说的了,确定了类型那么也就知道了需要多大内存占用提供计算使用。
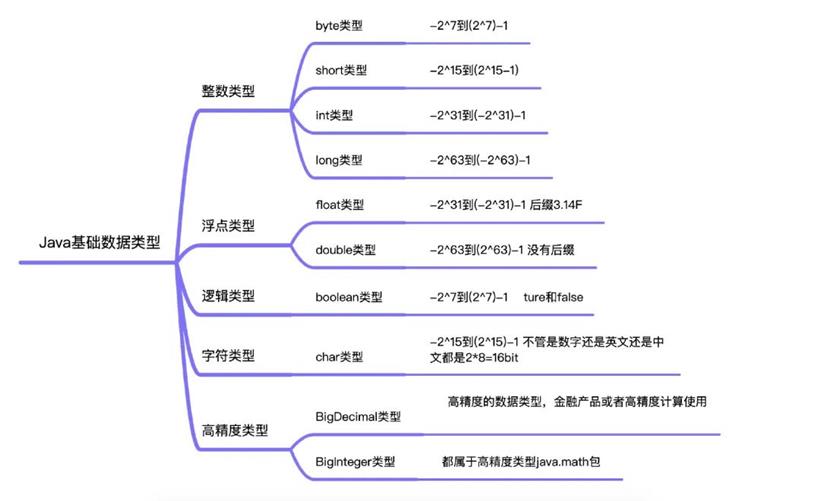
上图是我整理的Java基础数据类型范围,如果超出了就会发生内存溢出异常,或者发生数据精度丢失问题,主要原因就是底层只认识二进制,如果数据bit范围超出就出现了溢出。当某一种类型的数值已经达到了此类型能够保存的最大值之后,再继续扩大,或者达到了最小值后再继续缩小,就会出现数据溢出问题,例如byte范围为-128至127如果存储了十进制的值128那么就发生溢出。
字符串类型
计算机只认识0和1,那么怎么认识字符呢?也就是中文、日语、英文,英文很简单26个字母加26个小写然后加上数字就可以存储了,但是怎么表示呢?
看过电影的都知道电报机,一端发送电报,另外一端接收,转成人类能理解的意思。例如Morse code这个就是一个编码规律和解码规则,计算机为了解决这些问题也引入了相关的概念设计码表ASCII、Unicode、UTF-32、UTF-8,例如下面就是一张码表,通过数字和字符映射达到解码效果。
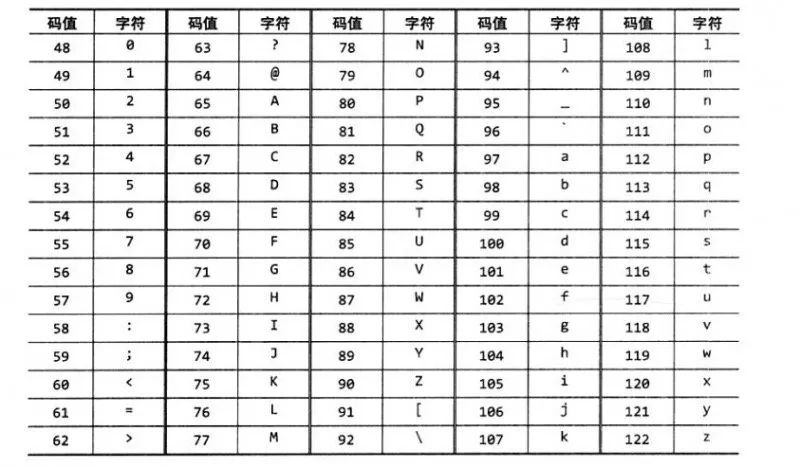
转转成数字就好说了对吧?比较数字是十进制的可以转换成二进制的存储,这就可以解决字符串翻译的问题了,然后所有的计算机默认安装的时候都带有码表,这样传输信息就可以互相解码和编码了。
解决了编码问题,那计算机在底层要分配多少空间去存储一个字符呢?现在的问题就是分配多少存储计量单位存储一个字符?
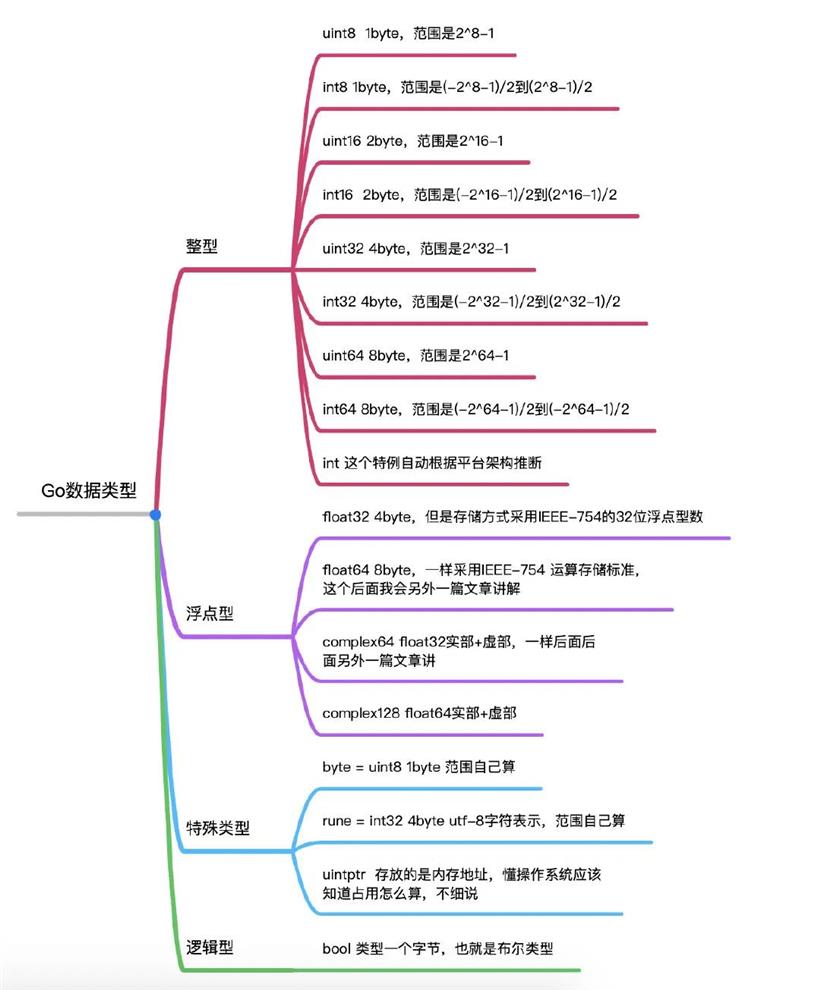
上图为Go一些基础类型整理,对着最上面Java的图,来看看两个语言字符类型怎么处理的。Java中的char是两个字节去存储一个字符;而在Go语言中有一个类型rune其实就是一个int32的别名,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型,那在Go里面中需要去存储一个字符需要4个字节。另外在Go语言中的其他字符例如ASCII码,这里Go使用的是uint8也是byte类型也就是一个字节,来表示一个ASCII字符。
在Go里面byte类型是uint8的别名,对于只占用1个字节的传统ASCII编码的字符来说,完全没有问题,例如 var ch byte = 'A',字符使用单引号括起来。但是如果是字符中文默认就是采用Unicode UTF-8,因此字符同样称为Unicode代码点或者runes。
v := 'n' // 这里!
fmt.Printf("v is of type %T\n", v) //v is of type int32
s := "hello 世界" // 堆代码 duidaima.com
fmt.Println(s[0]) //104
fmt.Println(len(s)) //12
fmt.Println(s) //hello 世界
fmt.Println(reflect.TypeOf(s[0]))//uint8
fmt.Println(string(s[0])) //h
输出单引号的变量,发现其类型是int32,go语言使用一个特殊类型rune表示字符型,rune为int32的别名,它完全等价于int32,习惯上用它来区别字符值和整数值,rune 表示字符的Unicode码值。另外在Go里面字符串是一个值类型,底层有byte数组,实际存储的是这个字符的字节,一个字符串包含了任意个byte,它并不限定Unicode,UTF-8或者任何其他预定义的编码,中文字符在unicode下占2个字节,在utf-8编码下占3个字节,而golang默认编码正好是utf-8。
小结
本篇文章笔者水平有限如果有什么问题,可以指正!


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






