“说实在的,我的梦想就是拥有个几千 star 的 GitHub 项目。”有开发者说道。虽然 GitHub star 数现在可能跟公众号的“阅读量”或者微博的“转发量”一样,是一种虚无飘渺的虚荣心指数,但不妨碍它成为开源社区中展示普遍认同的一大重要指标。项目 star 数也会影响很多重大的高风险决策,包括选择哪些项目、为哪些初创项目注资,甚至选择哪家企业入职等。
但是,现在人们已经不相信 star 数这个指标了。“GitHub 项目的 star 数我倒是不在乎,因为这东西太容易造假了,也代表不了项目的品质。我就不会去跟别人说给我的项目点 star 哦,这种行为在我看来真的 low 得不能再 low 了。”有开发者说道。
事实上,这位开发者说得并没有错。我们总会在 GitHub 上发现一些迅速蹿红的开源项目,刚刚开放,每周就能拿下几百 star。真有那么优秀吗?似乎好得令人难以置信了。还有一些新项目刚上架几天就 star 数猛增,这可是知名老项目在发布新版本或者其他重大公告才能拥有的待遇。最近,开源编排平台 Dagster 分享了在抽查一部分代码仓库后,发现了的几位“嫌疑人”,而在 Dagster 披露后,一些账户已经被删除。
 买了 star 后,项目一夜爆火
买了 star 后,项目一夜爆火
Dagster 的几位研究人员亲身体验了购买 star 给项目带来的优越。Dagster 建立了一个虚构的代码仓库(frasermarlow/tap-bls)并买了一堆 star。然后,Dagster 为该账户设计了个人资料文件,并使用 GitHub REST API(通过 pygithub)和 GitHub Archive 数据库展开了一系列测试。

Dagster 的代码仓库一夜之间就火了……
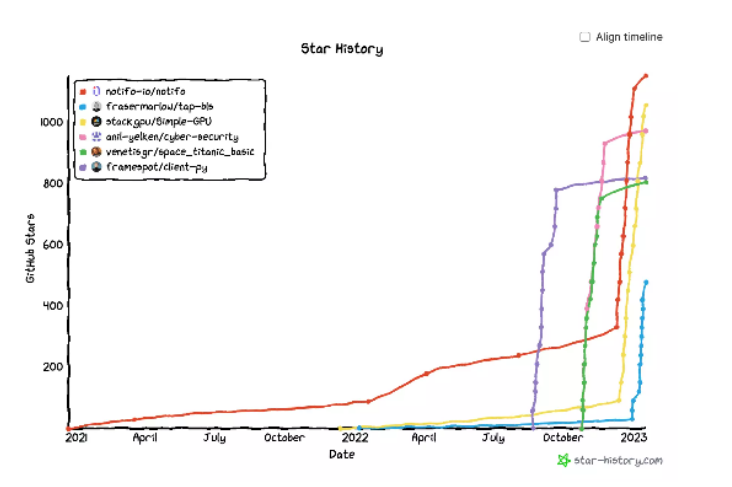
跟它一起“蹿红”的项目还有不少。
GitHub star 在哪里可以买到呢?用不着潜入暗网,直接在谷歌上搜就能找到几十种服务。为了观察这些虚假 GitHub 账户的个人资料,Dagster 通过以下服务买了 star:
Baddhi Shop,低成本伪造各种线上公开影响力指标的专业“服务商”。最低 64 美元,你就能买到 1000 颗 GitHub star。
GitHub24,由 Möller und Ringauf GbR 提供的服务,价格比 Baddhi Shop 要高得多(每 star 0.85 欧元)。
有一说一,这帮家伙还挺讲“诚信经营”:Dagster 买的 star 很快就到账了。GitHub24 在 48 小时内就交付了 100 颗 star。在此之前,Dagster 的代码仓库只有 3 颗 star。由于 Baddhi Shop 的价格更便宜,所以 Dagster 在这个渠道上订购了 500 颗 star,而一周之内对方同样成功履约。
不过,Dagster 表示“一分钱一分货”:一个月后 GitHub24 交付的 24 颗 star 都还在,但纯伪造的 Baddhi Shopstar 只剩下四分之三,那四分之一可能是被 GitHub 的完整性团队撤掉了。
star 数,还重要吗
“我的前雇主在他们的工作描述和招聘推介中使用了 GitHub stars。他们定期鼓励员工去 GitHub 上为公司的存储库加注星标。在全体会议上,GitHub stars 是他们报告的重点工作之一:我们在 GitHub stars 中超过了 X(鼓掌)。”网友“penguin_booze”爆料道。
当 stars 数成为企业关注的重点时,压力就给到了员工或者求职者。“能在 GitHub 上拿到三位数的 Star 的本科生至少进 BAT 毫无压力。”有网友称。这也导致了国内前几年开源项目刷 star 泛滥。
当 star 造假越来越多,有些开发者在评价开源项目的时候也会越来越少地真正在意 star 数。“就我个人而言,我从不看 star 数,因为即使这是合理的,它也没有让我比从 repo 中看到其它更有用的东西。”网友“ziml7”说道。
ziml7 表示,“我倾向于检查最早和最新提交之间的时间差异,这可以让我确定这不是一个某人花了几周时间编写代码、放在 GitHub 上,然后就被遗忘了的项目。我也会检查 issues。我会寻找比正在显示更多的、已经解决的 issues ,但我会快速浏览下来大致了解有多少是真正有意义的 issues 。我还从自述文件和文档中获得线索。如果这些 issues 存在就容易通过(检测),但如果它们不仅存在,并且既清晰又详细,那肯定对我的判断会有帮助。
但 ziml7 的观点也得到了一些质疑。网友“imadj”表示,许多维护人员只是将问题隐藏起来了,并没有真正解决。许多人以 0 个未解决的 issues 而自豪,好像这意味着什么。但如果他们会玩这个游戏,那么世界上任何软件都可以有 0 个 issues。“因此,除非您真的精通该项目并花了一些时间关注它,否则 star 数实际上可能是判断项目质量和声誉的更好指标。”
另外,在评估几个不同的 repos 以选择特定工具工作时,一些开发者会用 star 数进行判断。“如果其中一个 repo 有更多的 star,我在选择时会仔细权衡。提交的新鲜度绝对重要,但对我来说,有许多人加注星标这一事实表明,这个 repo 是吸引人眼球的和活跃的。”网友“cdiamand”表示。
对于 ziml7 提出的查看日期,也有开发者表示反对:“提交日期可以任意更改。”
网友“debarshri”指出,在评估 OSS 项目时,关键指标是社区活动。“GitHub stars 是一个很弱的社区活动指标。首先,它可以被造假。此外,Stars 的操作门槛非常低,为该项目加星的人并不真的会使用它。”
“debarshri”认为有两个社区活动指标非常重要:GitHub issues 和 slack/discord/discourse 评论。“在我看来,GitHub issues 的一个关键是,如果 GitHub issues 主要由核心团队提出,那不是一个好兆头。您需要来自客户或用户而不是团队的大量问题。如果项目正在解决实际问题,这是一个很好的指标。Stars 操作门槛极低。松散的评论也一样,它应该既有分量又有新鲜感。
无论如何,可以看出,Star 数目前在一些开发者心中依然有很重的分量。我们还无法完全抛弃这个衡量指标。但现在,大多数 GitHub 的 star 分析工具和相关讨论文章都没有解决 star 数灌水的问题。那么,还有其它办法吗?
如何识别假 star?
为了搞清楚 GitHub 上的 star 造假问题有多严重,Dagster 与垃圾邮件和滥用专家 Alana Glassco 一起深入研究了数据模式,分析了 GitHub Archive 数据库中的公共事件数据。机器学习可以帮忙吗?比如买点假 star,然后训练分类器来识别真 star 和假 star。Dagster 表示,这种方法存在几个问题:
1.GitHub star 卖家非常小心谨慎,而且会主动回避检测,所以很难根据名称、个人简介等直观特征对其出做分类。
2.标记及时性。为了避免被发现,卖家会不断调整自己的行动策略。因此,标记数据不仅难以获得,而且就在模型训练的过程中,这些数据内容可能就已经过时。
注:检测工作中,经常会将机器学习与启发式方法结合使用来识别恶意行为者,本次研究最终采用了启发式的检测思路。
在买下假 star 之后,这些假 star 又可以分成两类:
1.一眼为假。卖家根本就不加掩饰,只要点开个人资料,就能马上看出这帮给 star 的用户根本不是真人。
2.用心造假。另一个群体则复杂得多,账户上有很多相当真实的活动,借此掩盖了其属于假账户的事实。
于是,团队最终通过两种相互独立的启发式方法来识别这两类群体。
“一看就是假的”
在调查期间,Dagster 团队发现了很多一次性的个人资料:它们的存在就是为了伪造 GitHub 账户并为买家的 GitHub 代码仓库“加 star”。这类账户只有一天的活动记录(也就是账户创建当天,因此可以证明它们就是为了加 star 才存在的),别无其他。于是,Dagster 团队使用 GitHub API 收集了这类账户的更多信息,并发现了它们清晰的运作模式。这类账户的特点就是活动量极低:
1.创建时间为 2022 年或更晚
2.关注者 <=1
3.所关注者 <= 1
4.公开 gists == 0
5.公开 repos <=4
6.电子邮件、雇用信息、简历、博客和 Twitter 用户名均为空
7.投 star 日期=账户创建日期=账户更新日期
通过这种简单的“低活动”启发式方法,Dagster 团队检测到了大量可疑的虚假账户。这些账户只为同一组代码仓库投过 star,而且都是通过 GitHub API 来操作的。
 “用心造假”
“用心造假”
另一类假账户会更难发现,他们有比较真实的操作,比如个人资料照片、简历和贡献提交。相较前边一眼就能看出来的假账户,这类假账户的情况比较复杂。那么,应该如何做有效甄别呢?
聚类直觉
Dagster 团队最终选择了无监督聚类技术,相当于是为每个账户都构建一组特征。照理来说,正常用户的特征应该比较分散,就是说其每项特征都比较独特,不会遵循某个大聚类的整体趋势。但虚假用户的特征则有相似性,所以在可视化之后会聚集在一起。通过这种办法,应该能检测出目标账户是否属于可疑聚类。
举个更容易理解的例子:假定我们关注“活动日期”,GitHub 上的大多数用户并不会每天都有公开活动。如果某个账户每月有几天会使用 GitHub,而且具体日期跟另一个账户完全相同,甚至连分享的活动内容都差不多,那就表明这两个账户很可能是由相同的底层脚本在控制。根据这类账户的活动分享日期数(x 轴)和所交互的代码仓库总数(y 轴)可得出下图:
这里列出的就是 Dagster 那个“钓鱼”代码仓库的统计结果,项目得到的 star 几乎 100%是假的:
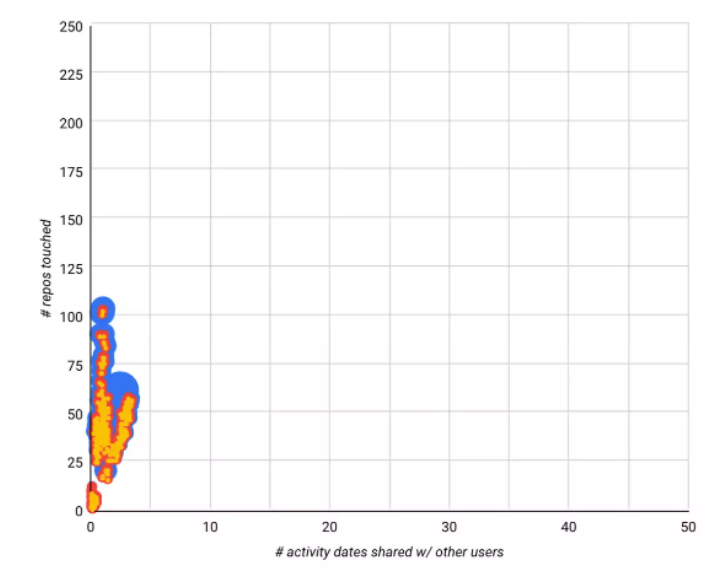
据实验团队所知,Dagster 项目应该没买过 star,所以他们用 Dagster 代码仓库做了对比。请注意左下角的小黄点,代表了少量误报账户(误报率=0.17%):

最后,我们再来看看纯假和纯真之间的情况。这个开源代码仓库既有真 star,也包含大量疑似假 star,黄色部分标出了可疑的投 star 群体。
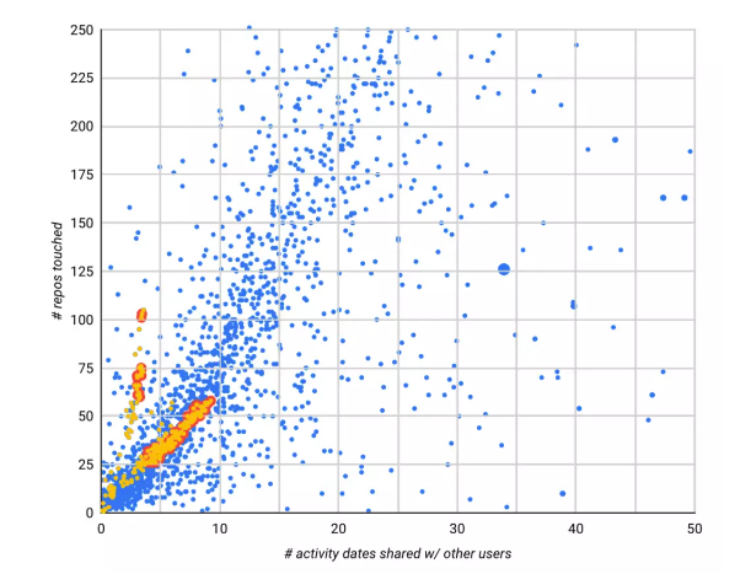 改进聚类
改进聚类
虽然这项技术挺有意思,但实际表现还不足以对假账户做高置信度判断,还需要再做改进。初步通过直觉完成数据挖掘之后,Dagster 团队又发现了另一种模式。虽然这些复杂的假账户都会以逼真的方式做交互,但这类假账户往往只跟少部分代码仓库互动。从本质上讲,各个假账户似乎都属于整体“可疑代码仓库”的一个子集。
遗憾的是,Dagster 团队没办法直接汇总出可疑代码仓库的列表,因为卖家会不断轮换新的代码仓库来回避跟踪。但 Dagster 可以使用无监督聚类技术自动识别出新的可疑代码仓库,再根据其是否存在、存在多少可疑交互来判断哪些账户确系伪造。下面来看实验团队对可疑用户判定方法:
首先,列出所有曾给可疑代码仓库投过 star 的用户。之后,根据与该组内其他用户的高度重叠性,确定出一组潜在的可疑代码仓库。注意,因为这些用户初步入选的理由是给同一个代码仓库投过 star,所以如果它们同样也为另一代码仓库投过 star,则代表值得怀疑。(但仅仅是值得怀疑,正常情况下也存在这种广泛的投 star 重叠,所以下面的附加步骤才格外重要!)
最后,要找出活动水平相对较低的账户,挑出其中绝大多数活动都仅仅指向之前确定的可疑代码仓库、且缺乏其他合法活动的账户,这些就是认定的假账户。在对已知假 star 做这一启发测试时,虽然计算量很大,但假账户的检测效果确实很好,准确率高达 98%、召回率为 85%。那么,这种方法在真实代码仓库中表现如何?
将这两种方法结合起来,实验团队能够更全面地了解给定 GitHub 代码仓库中的可疑投 star 和相应召回率:
脚注:受计算成本的限制,实验团队在 BigQuery 上进行的 GitHub Archive 分析仅限从 2022 年 1 月 1 日起的得 star。对于 GitHub Archive 分析,团队使用了另一种略有不同的方法来识别 GitHub API 分析中的“低活动”可疑账户。这些账户与通过聚类方法识别出的其他可疑账户相加,就得到了疑似假 star 的总数。
如果大家也想用这样的逻辑分析其他 GitHub 代码仓库,可点击下面链接:
https://github.com/dagster-io/fake-star-detector
其中,简单启发式算法是用 Python 实现的,只需要一个 GitHub 账户加访问令牌即可使用;无监督聚类方法则是用 dbt 项目实现的,需要 Google Cloud BigQuery 账户才能运行。请注意,用后者方式检测大型代码仓库可能会带来高昂的成本。
幸运的是,根据 Dagster 团队的研究,从投入产出的情况来看,买 star 行为在 GitHub 上还不是那么普遍,这也体现出开源社区积极向上的整体价值观。开源社区的长期发展还需要每个开发者的努力。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





