想象一下,如果你和一个AI生成的虚拟人聊天,它不光能对口型,还能跟你“眉来眼去”,甚至能根据你的话“思考人生”,跟你情绪交流!这画面是不是有点赛博朋克味儿了?这还真不是科幻,字节跳动 (ByteDance) 智能创作实验室给我们搞出来的大活儿——OmniHuman-1.5。这玩意儿让人惊掉下巴。直接宣告“数字人新王”登基了!
数字人从“提线木偶”到“真人”
在OmniHuman-1.5还没出生之前,市面上的那些AI数字人,几乎都是“精致的提线木偶”。它们可以根据你的声音,把嘴巴对得严丝合缝,手势也舞得像模像样。但是,这些都停留在卡尼曼大神《思考,快与慢》里说的“System 1”层面——也就是那种“条件反射式”的快反应,自动、无意识。它们缺的是啥?是“System 2”啊!是那种需要你动脑子、花力气去逻辑推理、去深思熟虑的慢反应。

那些老一代数字人,动作再逼真,也总觉得差点意思,像是少了点“灵魂”。口型是对上了,表情和动作仍然“抽风”一样很不自然。字节跳动这波OmniHuman-1.5,就是冲着这个根本性问题去的!姜建文 (Jianwen Jiang) 大佬领衔的团队,直接搬出了“双系统理论”,作为这项技术的底层逻辑。
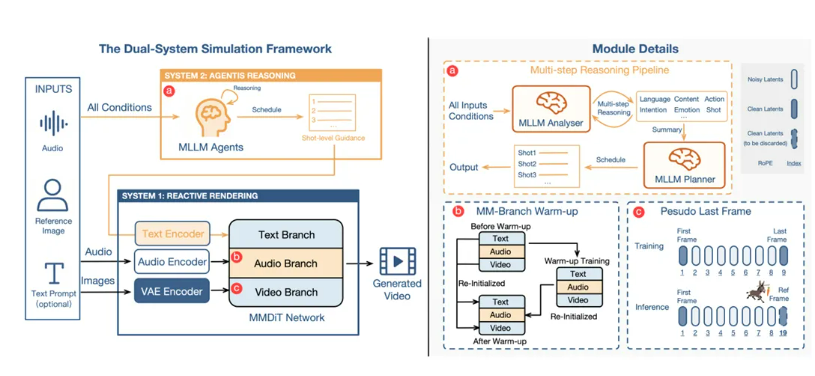
那么,他们是怎么做的呢?核心操作就是构建了一个“认知引擎”。上来就用强大的多模态大语言模型 (MLLM) 充当了虚拟人的“思考系统”(System 2)。你给它一张人物照片、一段音频,甚至再加点文字提示,这个“引擎”可不是直接就去驱动动作,它会先来一场“头脑风暴”!
它会分析脸长啥样,然后猜猜可能是啥性格、说话是啥风格;它会仔细听音频,理解说的是啥,情绪是咋样,有啥潜在目的。然后,它把所有信息一整合,就像一个老谋深算的导演,给你规划出一个逻辑严密的“动作剧本”!这个剧本可不简单,它会详细到视频的哪个时间点,人物该做啥表情、该比划啥手势,甚至连怎么跟周围环境互动都给你安排得明明白白。比如,如果你说“拿起信封并仔细阅读”,那它就会给你安排一套连贯的动作:伸手、拿起、拆开、看信,而不是随便给你来个搓手的动作。
“剧本”出来了,接下来就轮到专门设计的多模态扩散Transformer (MMDiT) 架构登场了,它就是那个负责把剧本变成视频的“执行系统”(System 1)。这步操作贼复杂,要把“思考系统”出来的文字指令、原始音频信号、还有人物的视觉特征,全都给它深度融合起来。
技术活儿:伪最后帧和对称融合
为了解决多模态信息融合这个老大难问题,OmniHuman-1.5掏出了两大“核武器”:一个是颠覆性的“伪最后帧”(Pseudo Last Frame)设计,另一个是对称的多模态分支架构。
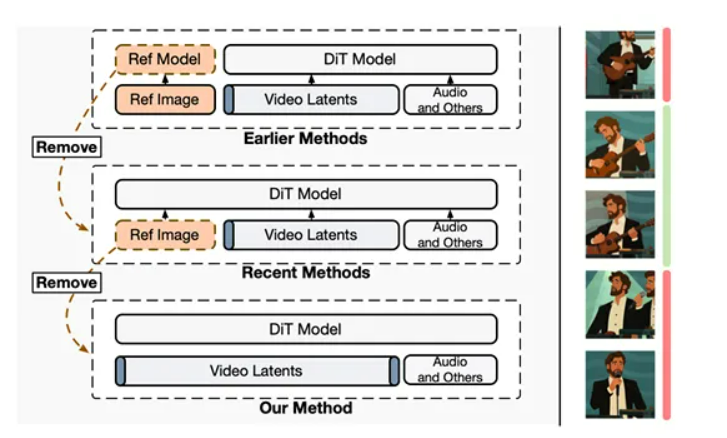
以前的那些数字人视频生成模型啊,为了让人脸保持一致,总喜欢把一张静态的参考图,像个“祖宗牌位”一样,从头到尾供着。结果呢?字节团队发现,这根本就是个“坑”!这会让模型产生一种错觉,觉得生成出来的视频必须时刻“回归”到那张静态图上,结果就是动作变得僵硬,没啥变化。
为了破这个局,他们直接来了一招“釜底抽薪”:在训练的时候,干脆把参考图给扔了!取而代之的是,模型被训练成根据视频片段的“第一帧”和“最后一帧”来预测中间的所有帧。到了实际用的时候,你给的那个参考图,就被他们“心机”地放在了“最后一帧”的位置,变成了一个“伪最后帧”。这招有多高明?它就像在驴子眼前吊了一根胡萝卜,一直引导模型向参考图的身份特征靠近,但又从不强制它在任何一帧里完全照抄。这样一来,既保证了人物身份的稳定,又给动作释放了无限的自由度,简直是神来之笔!
光有这个还不够,为了更好地融合音频和文字信息,OmniHuman-1.5直接放弃了以前那种“简单粗暴”的音频注入方式。它给音频专门构建了一个和视频分支对称、独立的音频处理分支。文字、音频、视频这三种信息,在MMDiT架构的每一层,都通过共享的自注意力机制进行互动和对齐,保证它们能一起进步,最终融合到一个统一的语义空间里。为了让这个庞大的系统能稳定训练,团队还搞了个“两阶段预热”策略:先让音频分支学好唇形同步这些基本功,然后再把它和强大的预训练视频、文本分支结合起来,最终实现各司其职、完美协作!
数字人界的“影帝”诞生了!
技术再牛,最终还得看效果!根据官方论文和各种评测,OmniHuman-1.5在各种指标上,都把老一代技术和竞争对手们甩了好几条街。
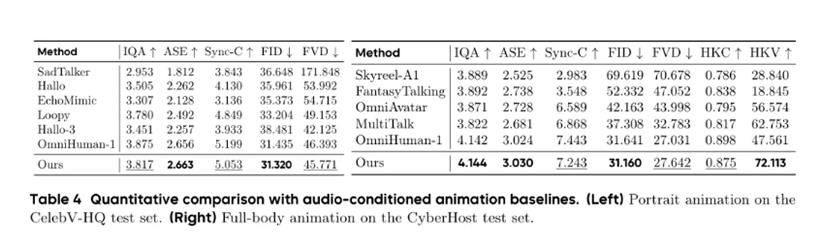
从客观数据上看,无论是衡量视频整体质量的FID、FVD,还是看唇音同步的Sync-C,甚至测量手部动作自然度和丰富度的HKC和HKV,OmniHuman-1.5都是妥妥的领先!尤其是在那种需要全身大动作的复杂场景里,它的HKV分数简直碾压其他模型,证明它在生成各种大幅度、多变肢体动作方面,那是一绝!
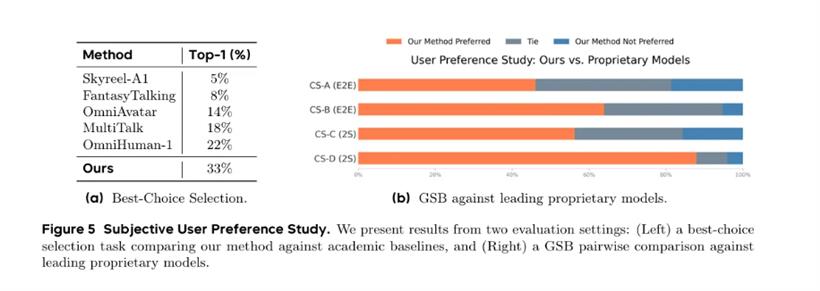
但真正让OmniHuman-1.5封神的,是它在主观评测里的表现,简直是吊打!在用户偏好度调查中,让大家在OmniHuman-1.5和其他顶尖模型生成的视频里选“最佳”,OmniHuman-1.5以33%的“最佳选择率”遥遥领先!用户普遍反馈,它生成的视频在“动作自然度”和“语义一致性”上,有着“肉眼可见的优势”。
比如说,虚拟人说“看这个发光的水晶球”,视频里真的会出现一个发光的水晶球,而且它的手势还会自然地指过去;对话换人了,没说话的角色也会自然地“待机”,而不是傻愣愣地杵在那儿。更让人惊掉下巴的是,OmniHuman-1.5这能力,可不是只针对单人!它稍微扩展一下,就能搞定复杂的多人互动场景,给每个角色安排不同的“戏份”,生成协调一致的群体表演。
甚至,它连非人类角色都能驾驭,比如动物、动漫人物,都能让它们表演得活灵活现,完全符合它们的“人设”!而且,它生成的视频能长达一分钟以上,还能通过自回归的方式无缝衔接,用来做演讲、MV这种长视频,简直是绝配!
看看下面的demo视频:

内容产业的“万能钥匙”来了!
OmniHuman-1.5这技术一发布,有望彻底引爆一个全新的内容创作时代,商业前景那是一片蓝海!在电影电视圈,它能帮你快速生成高质量的预告片、分镜动画,甚至给虚拟角色注入灵魂,再也不是梦!教育行业呢?搞出永不疲倦、还能根据学生反馈调整教学方式的“AI名师”,让学习变得更生动、更个性化!
营销和电商?品牌可以轻松搞定专属的虚拟代言人,24小时直播带货,表情、动作跟产品卖点完美结合!游戏和社交应用里,NPC (Non-Player Character) 不再是傻子,它们行为会更智能,让游戏沉浸感直线飙升!OmniHuman-1.5的出现,把内容创作的门槛直接拉低到了史无前例的程度,让“一个人就是一个团队”的梦想,照进现实!
AI数字人技术,正在从之前的“看着像”彻底进化到了“有神韵”。它不再是个只会鹦鹉学舌的模仿者,而是一个能主动思考、规划、表达的“智慧生命”。万物皆“活”起来了!
信息来源:
https://arxiv.org/abs/2508.19209v1
https://omnihuman-lab.github.io/v1_5/


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






