蚂蚁集团把一个万亿参数的旗舰大模型,Ling-1T,开源了。
主角是蚂蚁内部一个叫“百灵”的团队。Ling-1T,是全世界已知用FP8这种低精度模式训练出来的最大的基座模型。理论上,神经元越多,大脑就越聪明,能处理的事儿就越复杂。GPT-3刚出来的时候,1750亿参数就震惊了世界,现在蚂蚁直接干到了1万亿。蚂蚁这个Ling-1T,属于他们家一个叫Ling 2.0的模型家族。这个家族里分工明确,有三个主要系列:Ling系列,Ring系列,还有Ming系列。
Ling系列,就是这次发布的Ling-1T所属的系列,定位是“非思考模型”。不思考算什么人工智能?其实这里的“非思考”是相对的,意思是它更擅长处理通用任务,追求的是效率和速度,像个反应敏捷的“快枪手”。Ring系列,则是“思考模型”,是从Ling系列衍生出来的,专门干“深度思考”和复杂推理的活儿,像个深思熟虑的“谋士”。就在一个月前,9月,蚂蚁已经开源了一个叫Ring-1T-preview的万亿参数思考模型,算是给Ling-1T的发布提前探了探路。Ming系列,是搞“多模态”的,能看图、能听声、能看视频,处理的信息类型更丰富。
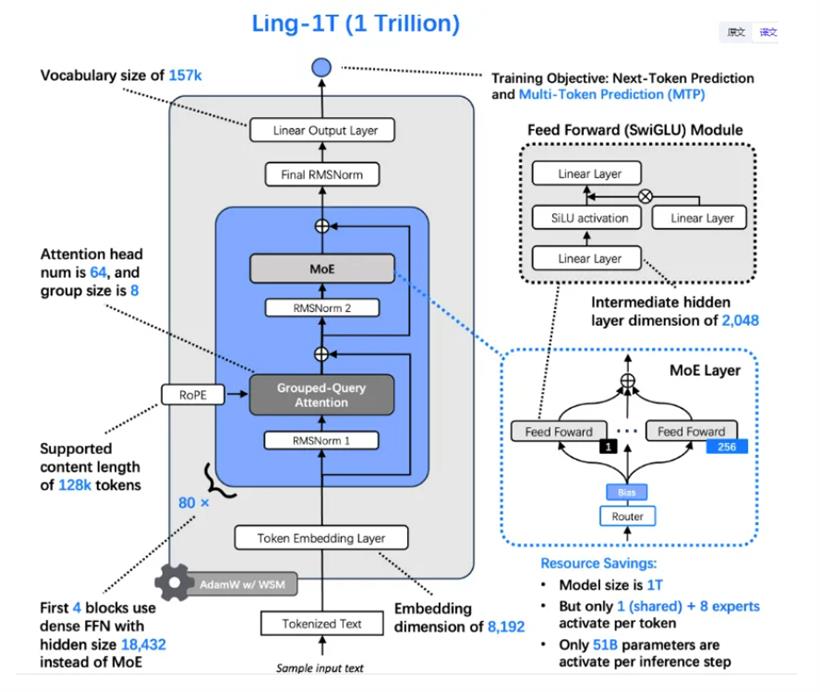
Ling-1T有1万亿的总参数,但每个token,只激活其中大约500亿的参数。这个激活比例是1/32,相当于你雇了32个专家,但每次干活儿只需要其中1个专家出马,大大降低了实际的运算成本。
万亿参数怎么训练
把模型堆到万亿级别,不是简单的“大力出奇迹”,背后有一套复杂的“方法论”。
蚂蚁的团队为这事儿专门搞出了一个“Ling缩放定律”(Ling Scaling Law)。他们做了300多个模型的实验,总结出了一套规律,揭示了MoE架构里,计算效率、专家激活比例和计算预算之间的一种幂律关系。训练这么大的模型,一点小小的波动,可能就导致几百上千万的计算资源打水漂。为了解决这个问题,蚂蚁自研了一个叫WSM(Warmup-Stable and Merge,预热稳定与合并)的学习率调度器。
学习率,可以理解为模型学习新知识的“步子大小”。步子太大,容易“扯着蛋”,学不进去;步子太小,又学得太慢。传统的调度策略就像开手动挡的车,需要小心翼翼地控制油门。而WSM,通过一种叫“checkpoint merging”(检查点合并)的技术,能模拟出各种不同的学习率衰减策略,让模型在训练过程中自己找到最舒服的“档位”,跑得又快又稳。
根据他们自己发的论文数据,用了WSM之后,模型在数学(MATH)、代码(HumanEval)、通用知识(MMLU-Pro)这些硬核测试上的分数,比传统方法高了好几个百分点。除了这些,Ling-1T在架构上还有一些微创新。
比如,为了让模型更擅长组合推理,他们加了个叫MTP(Multi-Head Token Projection Layer,多头令牌投影层)的东西;为了让MoE里的专家们能“自发地”均衡负载,而不是靠额外的“辅助损失”去强行约束,他们设计了S型函数评分专家路由和零均值更新机制;为了保证模型在万亿参数规模下训练不“崩”,他们还在注意力机制里加了QK归一化(Query-Key Normalization,查询-键归一化)。
正是这些一点一滴的改进,才撑起了万亿模型这座大厦。整个训练过程也很有讲究,分了三步走:预训练、中训练、后训练。
预训练阶段,就是给模型“喂”海量数据,Ling-1T吃了超过20万亿个token的高质量数据,其中超过40%都是推理密集型的语料。
中训练阶段,则开始“加小灶”,专门喂高质量的思维链(Chain-of-Thought)推理数据,提前“激活”模型的推理能力,让它学会一步一步地思考问题。
后训练阶段,用的是一种叫“演进式思维链”(Evolutionary Chain-of-Thought)的技术,让模型在可控的成本下,不断地自我迭代,提升推理的精度和效率。
全程,训练都用的是FP8混合精度。相比于主流的BF16(16位浮点数),FP8能给Ling-1T带来超过15%的端到端加速,而且在训练了1万亿个token后,和BF16的精度损失偏差小于0.1%,几乎可以忽略不计。这是目前已知的,全世界用FP8训出来的最大的模型。
Ling-1T与其他模型比较
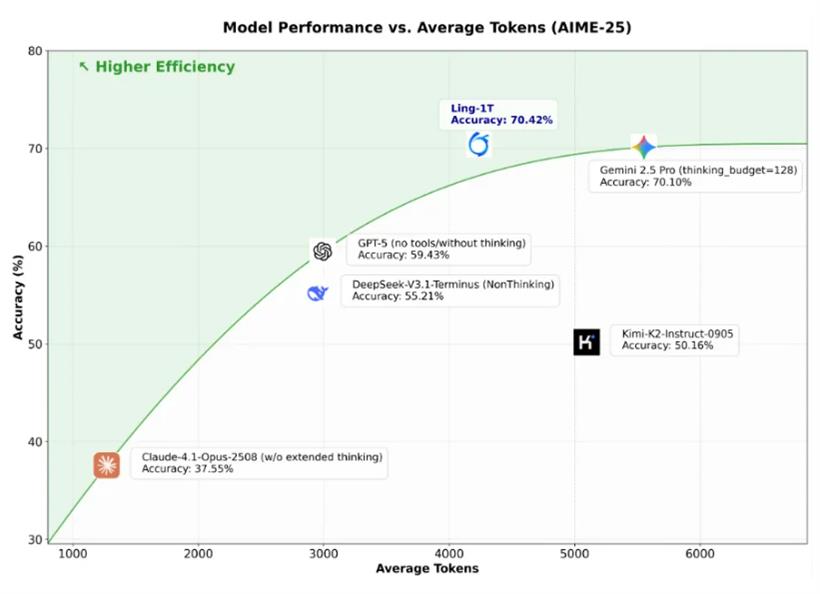
蚂蚁把Ling-1T跟市面上主流的开源和闭源模型都比了比。开源最强,甚至多项测试集上超越了gpt-2-main和Gemini-2.5-Pro(lowthink)。在数学推理上,AIME 25测试集,Ling-1T的准确率达到了70.42%。Ling-1T扩展了推理准确性与推理长度之间的帕累托前沿,展示了其在“高效思考和精确推理”方面的优势。
代码能力也是一大亮点。ArtifactsBench的AI代码生成评测标准上,Ling-1T在所有开源模型里排第一。它不仅能写出功能正确的代码,还能兼顾“视觉美感”,比如让前端页面的布局更合理、更好看。这背后是一种混合了语法、功能、美学的三重奖励机制在起作用。在另一个叫BFCL V3的工具调用测试中,Ling-1T只经过了轻度的指令微调,就在没怎么见过相关数据的情况下,达到了大约70%的准确率。
Ling-1T已经在知识、代码、数学、推理、代理和对齐基准上进行了广泛评估。它目前是最好的开源旗舰非思考模型,在复杂推理方面可以与闭源API相媲美。
跑分强,干实事更强
社区测试表现亮眼。比如,生成小球在六边形里滚动,物理规律遵循非常好。
再比如,模拟宇宙演化史。
来源:@赛博禅心
Ling-1T虽然厉害,但也有它的局限。有技术团队指出,它目前使用的分组查询注意力(Grouped-Query Attention, GQA)架构,在处理超长上下文(比如超过128K)的时候,成本还是比较高。蚂蚁自己的团队也承认了这一点,并表示正在研究混合注意力架构来解决这个问题。
开源地址:
HuggingFace:https://huggingface.co/inclusionAI/Ling-1T
ModelScope:
https://modelscope.cn/models/inclusionAI/Ling-1T
GitHub:
https://github.com/inclusionAI/Ling-V2
体验地址(国内):https://ling.tbox.cn/chat
参考资料:
https://arxiv.org/abs/2507.17702
https://arxiv.org/abs/2507.17634


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






