- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

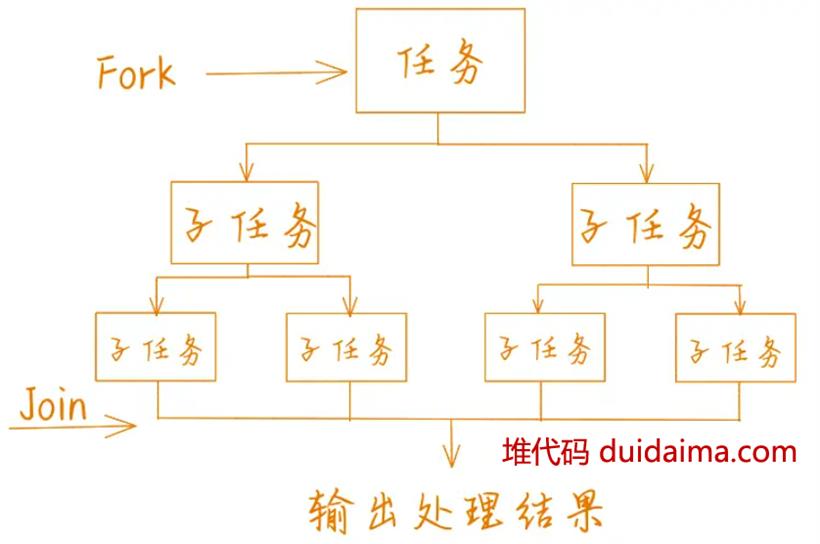
ForkJoinPool 是一个功能强大的 Java 类,用于处理计算密集型任务,使用 ForkJoinPool 分解计算密集型任务,并并行执行它们,能够产生更好的性能。它的工作原理是将任务分解成更小的子任务,使用分而治之的策略进行操作,使其能够并发地执行任务,从而提高吞吐量并减少处理时间。
ForkJoinPool 的独特特性之一是它用于优化性能的工作窃取算法。当工作线程完成分配的任务时,它将从其他线程窃取任务,确保所有线程都有效地工作,并且不会浪费计算机资源。
ForkJoinPool 在 Java 的并行流和 CompletableFutures 中广泛使用,允许开发人员轻松地并发执行任务。此外,其他 JVM 语言(如 Kotlin和 Akka)也使用这个框架来构建需要高并发性和弹性的消息驱动应用程序。
ForkJoinPool 存储着 worker,这些 worker 是在机器的每个 CPU 核心上运行的进程。这些进程中的每一个都存储在一个双端队列(Deque)中。一旦工作线程的任务用完,它就开始从其他工作线程窃取任务。
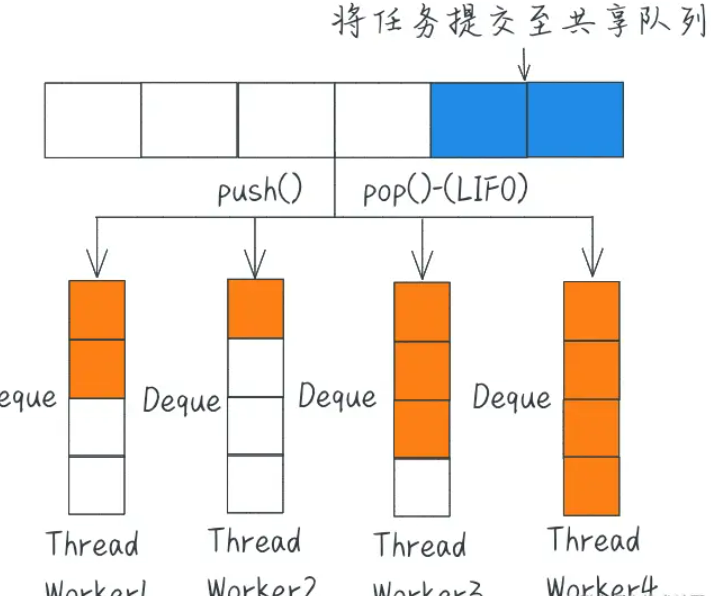
Work-stealing 算法的优点是它可以实现高效的负载平衡和并行计算,同时减少了任务的等待时间。当一个线程完成自己的任务并变得空闲时,它将尝试从另一个线程的队列末端“窃取”任务,与队列数据结构相同,它遵循 FIFO 策略。这种策略将允许空闲线程拾取等待时间最长的任务,从而减少了总体等待时间并提高了吞吐量。
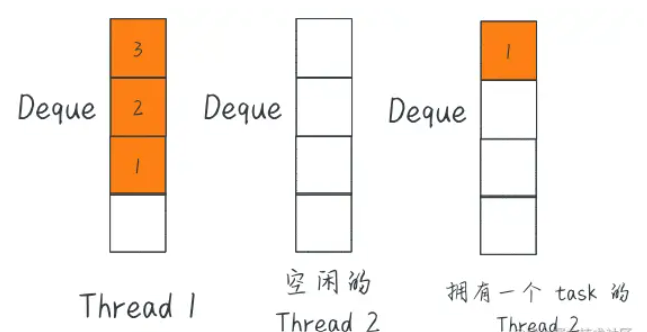
总的来说,ForkJoinPool 的工作窃取算法是一个强大的功能,可以通过确保所有可用的计算资源得到有效利用来显著提高并行程序的性能。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class ForkJoinDoubleAction {
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
int[] array = {1, 5, 10, 15, 20, 25, 50};
DoubleNumber doubleNumberTask = new DoubleNumber(array, 0, array.length);
// 调用compute方法
forkJoinPool.invoke(doubleNumberTask);
System.out.println(DoubleNumber.result);
}
}
class DoubleNumber extends RecursiveAction {
final int PROCESS_THRESHOLD = 2;
int[] array;
int startIndex, endIndex;
static int result;
DoubleNumber(int[] array, int startIndex, int endIndex) {
this.array = array;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
protected void compute() {
if (endIndex - startIndex <= PROCESS_THRESHOLD) {
for (int i = startIndex; i < endIndex; i++) {
result += array[i] * 2;
}
} else {
int mid = (startIndex + endIndex) / 2;
DoubleNumber leftArray = new DoubleNumber(array, startIndex, mid);
DoubleNumber rightArray = new DoubleNumber(array, mid, endIndex);
// 递归地调用compute方法
leftArray.fork();
rightArray.fork();
// Joins
leftArray.join();
rightArray.join();
}
}
}
计算的结果输出是 252。因此,RecursiveAction 和 ForkJoinPool 应该用于计算密集型任务,在这些任务中,工作的并行化可以显著提高性能。否则,由于线程的创建和管理,性能会变得更差。
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinSumArrayTask extends RecursiveTask<Integer> {
private final List<Integer> numbers;
public ForkJoinSumArrayTask(List<Integer> numbers) {
this.numbers = numbers;
}
@Override
protected Integer compute() {
if (numbers.size() <= 2) {
return numbers.stream().mapToInt(e -> e).sum();
} else {
int mid = numbers.size() / 2;
List<Integer> list1 = numbers.subList(0, mid);
List<Integer> list2 = numbers.subList(mid, numbers.size());
ForkJoinSumArrayTask task1 = new ForkJoinSumArrayTask(list1);
ForkJoinSumArrayTask task2 = new ForkJoinSumArrayTask(list2);
task1.fork();
return task1.join() + task2.compute();
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
List<Integer> numbers = List.of(1, 3, 5, 7, 9);
int output = forkJoinPool.invoke(new ForkJoinSumArrayTask(numbers));
System.out.println(output);
}
}
在上面的代码中,我们递归地分解数组,直到它达到基本条件。最后输出结果为 25。