

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

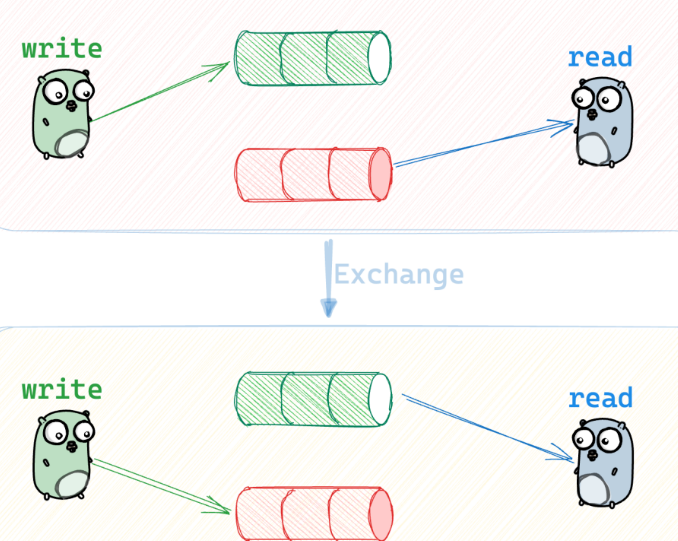
2.右边的 reader 还没有读完 buffer2,那么左边的 writer 就会阻塞,直到右边的 reader 读完 buffer2,然后交换。 周而复始。
2.左边的 writer 还没有写完 buffer1,那么右边的 reader 就会阻塞,直到左边的 writer 写完 buffer1,然后交换。 周而复始。
5.在交换完之前,阻塞的 goroutine 不可能调用Exchange方法两次
type Exchanger[T any] struct {
leftGoID, rightGoID int64
left, right chan T
}
你必须使用 NewExchanger 创建一个Exchanger,它会返回一个Exchanger的指针。 初始化的时候我们把 left 和 right 的 id 都设置为-1,表示还没有 goroutine 使用它们,并且不会和所有的 goroutine 的 id 冲突。 同时我们创建两个 channel,一个用来左边的 goroutine 写,右边的 goroutine 读,另一个用来右边的 goroutine 写,左边的 goroutine 读。channel 的 buffer 设置为 1,这样可以避免死锁。func NewExchanger[T any]( "T any") *Exchanger[T] {
return &Exchanger[T]{
leftGoID: -1,
rightGoID: -1,
left: make(chan T, 1),
right: make(chan T, 1),
}
}
Exchange方法是核心方法,它用来交换数据,它的实现如下:func (e *Exchanger[T]) Exchange(value T) T {
goid := goroutine.ID()
// left goroutine
isLeft := atomic.CompareAndSwapInt64(&e.leftGoID, -1, goid)
if !isLeft {
isLeft = atomic.LoadInt64(&e.leftGoID) == goid
}
if isLeft {
e.right <- value // send value to right
return <-e.left // wait for value from right
}
// right goroutine
isRight := atomic.CompareAndSwapInt64(&e.rightGoID, -1, goid)
if !isRight {
isRight = atomic.LoadInt64(&e.rightGoID) == goid
}
if isRight {
e.left <- value // send value to left
return <-e.right // wait for value from left
}
// other goroutine
panic("sync: exchange called from neither left nor right goroutine")
}
当一个 goroutine 调用的时候,首先我们尝试把它设置为left,如果成功,那么它就是left。 如果不成功,我们就判断它是不是先前已经是left,如果是,那么它就是left。 如果先前,或者此时left已经被另一个 goroutine 占用了,它还有机会成为right,同样的逻辑检查和设置right。如果既不是left也不是right,那么就是第三者插入了,我们需要 panic,因为我们不希望第三者插足。 buf1 := bytes.NewBuffer(make([]byte, 1024))
buf2 := bytes.NewBuffer(make([]byte, 1024))
// 堆代码 duidaima.com
exchanger := syncx.NewExchanger[*bytes.Buffer]( "*bytes.Buffer")
var wg sync.WaitGroup
wg.Add(2)
expect := 0
go func() { // g1
defer wg.Done()
buf := buf1
for i := 0; i < 10; i++ {
for j := 0; j < 1024; j++ {
buf.WriteByte(byte(j / 256))
expect += j / 256
}
buf = exchanger.Exchange(buf)
}
}()
var got int
go func() { // g2
defer wg.Done()
buf := buf2
for i := 0; i < 10; i++ {
buf = exchanger.Exchange(buf)
for _, b := range buf.Bytes() {
got += int(b)
}
buf.Reset()
}
}()
wg.Wait()
fmt.Println(got)
fmt.Println(expect == got)
在这个例子中 g1负责写,每个 buffer 的容量是 1024,写满就交给另外一个读 g2,并从读 g2 中交换过来一个空的 buffer 继续写。 交换 10 次之后,两个 goroutine 都退出了,我们检查写入的数据和读取的数据是否一致,如果一致,那么就说明我们的Exchanger实现是正确的。


