过去,想要在本地跑一个大语言模型(LLM),对很多开发者来说都是一件“又爱又恨”的事。爱的是它能带来更快的调试体验、更低的成本,以及更强的数据隐私保障;恨的是配置复杂、依赖繁多、硬件兼容问题层出不穷——光是让模型跑起来,可能就得折腾好几天。但现在,Docker 带来了一个让人眼前一亮的解决方案:Docker Model Runner。
本地跑大模型,终于变简单了
Docker 最近在官方博客宣布推出 Docker Model Runner(模型运行器),目标非常明确:让本地运行 AI 模型像运行一个容器一样简单。你不需要再手动安装一堆推理引擎、配置 CUDA 环境、或者在不同平台之间反复调试。只要你是 Docker 用户,尤其是用 Mac(Apple Silicon 芯片)的开发者,现在只需更新到 Docker Desktop 4.40,就能直接在本地拉取并运行大模型,整个过程几乎“开箱即用”。
更贴心的是,Model Runner 内置了基于 llama.cpp 的推理引擎,并通过大家熟悉的 OpenAI API 接口对外提供服务。这意味着,你现有的 AI 应用代码几乎不用改,就能无缝切换到本地模型上运行。
为什么这很重要?
过去,大模型主要依赖云端推理,虽然方便,但存在几个痛点:
成本高:每次调用都要花钱,频繁调试时费用惊人;
延迟大:网络往返拖慢开发节奏;
隐私风险:敏感数据上传到第三方平台,总有顾虑。
而本地部署能完美避开这些问题。但前提是——部署不能太难。Docker Model Runner 正是要解决这个“前提”。它把模型打包成 OCI Artifacts(一种开放的容器化标准),你可以像拉取 Docker 镜像一样,用一行命令 docker pull 把模型下载到本地。模型来自 Hugging Face、Google 等合作伙伴,已经过优化,专为本地运行而准备。未来,你甚至可以把自己微调后的模型也打包成 OCI 格式,推送到私有仓库,集成进 CI/CD 流程——AI 开发真正融入现代软件工程体系。
生态联手,让 AI 开发更顺滑
Docker 并不是单打独斗。这次 Model Runner 的发布,背后站着一众重量级伙伴:Google、Hugging Face、Spring AI、VMware Tanzu、Continue、Dagger,还有高通(Qualcomm)等硬件厂商。这意味着什么?
.你可以在本地轻松试用 Google 或 Hugging Face 提供的最新模型;
.用 Spring AI 或 Continue 构建的应用能直接对接本地模型;
.在 Apple Silicon 上还能享受 GPU 加速,推理速度更快;
.未来 Windows 用户也能用上 GPU 加速,覆盖更广。
这只是开始
目前 Docker Model Runner 还处于 Beta 阶段,仅支持 Mac(Apple Silicon)。但 Docker 已明确表示,后续将支持更多平台,包括 Windows,并加入对 Docker Compose、Testcontainers 等工具的集成,让 AI 成为开发流程中“自然而然”的一部分。
如何上手?
如果你有一台 M1/M2/M3 芯片的 Mac,只需三步:
1.升级 Docker Desktop 到 4.40 或更高版本;
2..从 Docker 的 Docker Hub 拉取一个模型(比如 docker pull docker/llm:phi3),也可以在Docker Desktop界面完成:
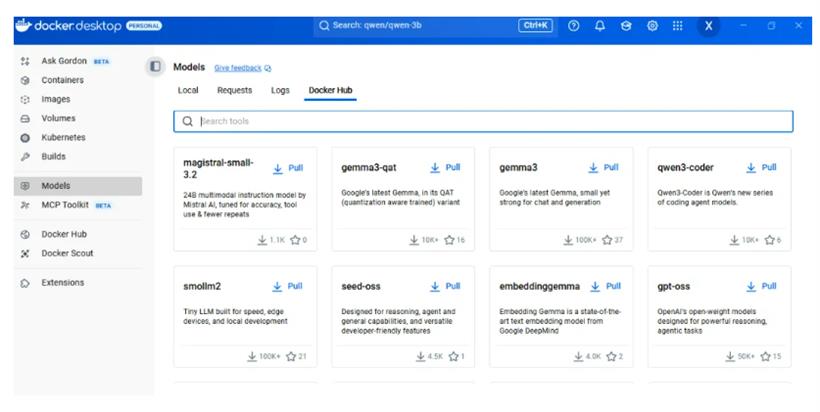
3.启动模型,用熟悉的 OpenAI API 调用它,开始你的本地 AI 实验。
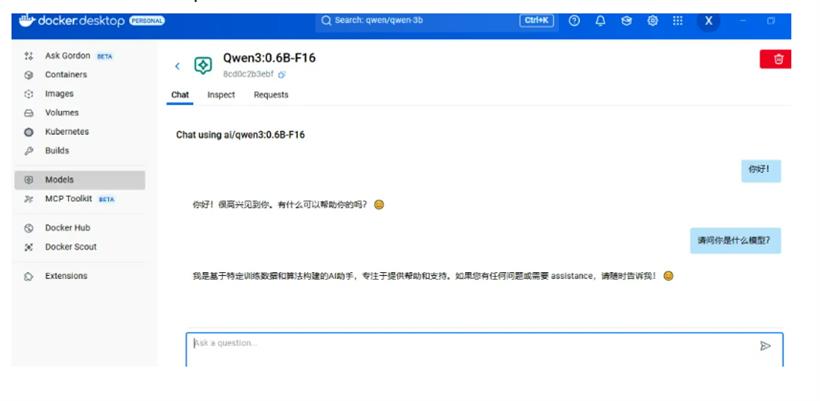
官方还提供了快速入门指南和 YouTube 教程,手把手带你把 Mac 变成“AI 玩具箱”。windows也可以。
结语
Docker 一直致力于“让开发更简单”,如今它把这份初心带进了生成式 AI 领域。本地运行大模型,不再只是极客的专利,而是每个开发者都能轻松上手的日常操作。AI 的未来,或许不在遥远的云端,而在你手边的这台电脑里——而 Docker,正悄悄为你打开这扇门。
文档地址:
https://docs.docker.com/ai/model-runner/


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






