

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

当我们访问一个网页时,浏览器首先会从服务器请求 HTML。服务器返回 HTML 响应,然后 HTML 会告诉浏览器下一步的工作,包括请求 CSS、JavaScript 等资源。等待这些资源返回后,浏览器才会进行真正的渲染动作。
<link rel="prefetch" href="/next-page/">另外一种方式,不仅会预取资源,还会提前进行一定的渲染:
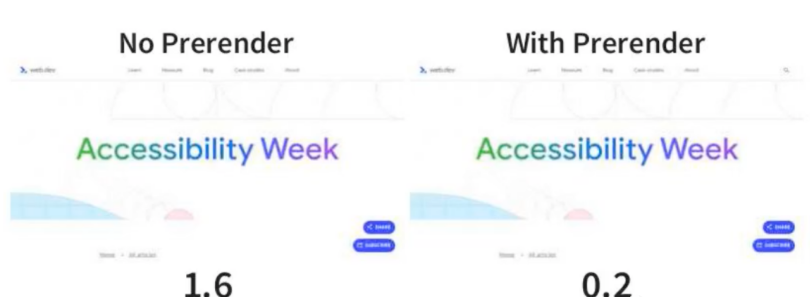
<link rel="prerender" href="/next-page/">但除了 Chrome 之外,这种方式并没有得到广泛支持,而且它不是一个表达能力很强的 API。后来,Chrome 又实现了 NoState Prefetch,它和 <link rel="prefetch" href="/next-page/"> 这种方式类似,会提前获取未来需要加载的页面所需的资源,但不会完全预渲染页面,也不会执行 JavaScript。NoState Prefetch 确实可以通过改善资源加载来帮助我们提高页面性能,但它不会像完整预渲染那样提供即时的页面加载能力。

<script type="speculationrules">
{
"prefetch": [
{
"source": "list",
"urls": ["next.html", "next17.html"]
}
]
}
</script>
Prefetch 的推测规则只会对 HTML 文档进行预取,而不会预取页面上的子资源。与旧的 <link rel="prefetch"> (预取的数据存放在 HTTP 缓存)机制不同,通过 Speculation Rules 进行的预取,数据是保存在内存中的,所以浏览器一旦需要可以更快的访问到这些资源。



<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["next.html", "next17.html"]
}
]
}
</script>
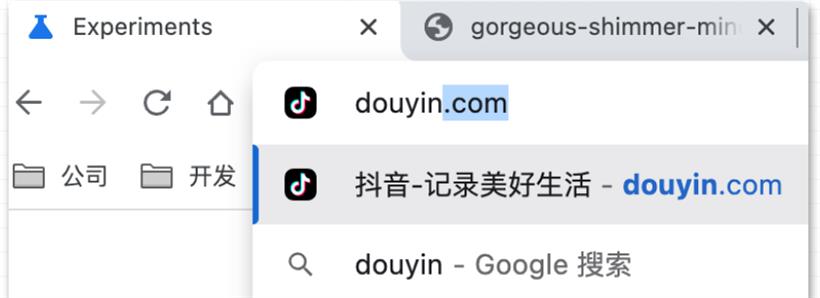
目前浏览器只能支持同站站点的预渲染,例如 https://1.conardli.com 可以预 https://17.conardli.com 上的页面。注意如果是非同源的情况,需要预渲染的页面必须包括一个 Supports-Loading-Mode: credentialed-prerender Header 。但是,与 Prefetch 不同的是,预渲染的请求在 Network 看板里是没办法直接看到的,因为它们是在 Chrome 中的单独渲染进程中获取和渲染的。
// 堆代码 duidaima.com
<script type="speculationrules">
{
"prefetch": [
{
"source": "list",
"urls": ["数据预取17.html"]
}
]
}
</script>
<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["预渲染17.html"]
}
]
}
</script>
同样的,一个推测规则也可以设置为数组:<script type="speculationrules">
{
"prerender": [
{
"source": "list",
"urls": ["17.html"]
},
{
"source": "list",
"urls": ["1717.html"]
}
]
}
</script>
注意:目前浏览器限制一个页面最多预渲染 10 个子页面。// 判断浏览器是否支持 speculationrules
if (HTMLScriptElement.supports &&
HTMLScriptElement.supports('speculationrules')) {
const specScript = document.createElement('script');
specScript.type = 'speculationrules';
specRules = {
prerender: [
{
source: 'list',
urls: ['/17.html'],
},
],
};
specScript.textContent = JSON.stringify(specRules);
console.log('添加预渲染规则: 17.html');
document.body.append(specScript);
}
最后



