从PDF中提取内容能帮助我们获取文件中的信息,以便进行进一步的分析和处理。此外,在遇到类似项目时,提取出来的文本或图片也能再次利用。要在Python中通过代码提取PDF文件中的文本和图片,可以使用 Spire.PDF for Python 这个第三方库。来看一下具体操作吧!
安装 Spire.PDF for Python
Python PDF库支持在各种 Python 程序中创建、读取、编辑、转换和保存 PDF 文档。要安装该库,可使用以下 pip 命令。
pip install Spire.PDF
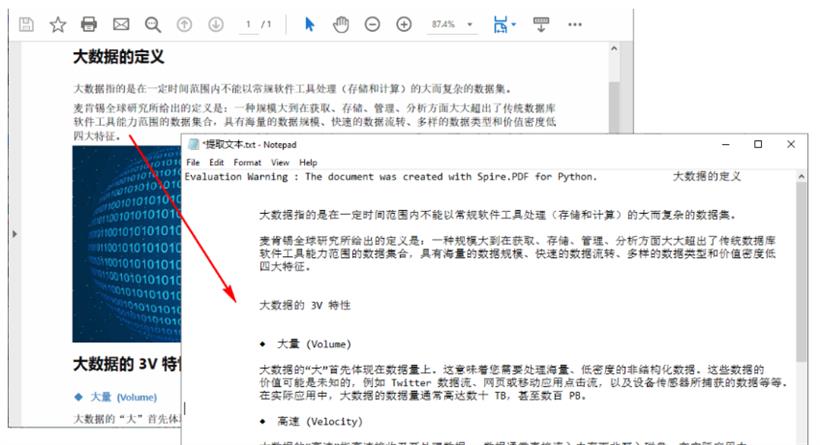
使用 Python 提取PDF文本
Spire.PDF for Python 提供的 PdfPageBase.ExtractText() 方法能提取一个 PDF 页面中文本。根据你的具体需求,你可以选择仅提取某页中的文本,或者遍历所有页面以提取整个PDF文件中的文本。完整Python代码如下:
from spire.pdf import *
from spire.pdf.common import *
# 堆代码 duidaima.com
# 创建PdfDocument类的实例
pdf = PdfDocument()
# 加载PDF文档
pdf.LoadFromFile("大数据.pdf")
# 创建一个TXT文件来保存提取的文本
extractedText = open("Output/提取文本.txt", "w", encoding="utf-8")
# 遍历文档的每一页
for i in range(pdf.Pages.Count):
# 获取页面
page = pdf.Pages.get_Item(i)
# 从页面提取文本
text = page.ExtractText()
# 将文本写入TXT文件
extractedText.write(text + "\n")
extractedText.close()
pdf.Close()
 使用 Python 提取PDF页面中指定矩形区域的文本
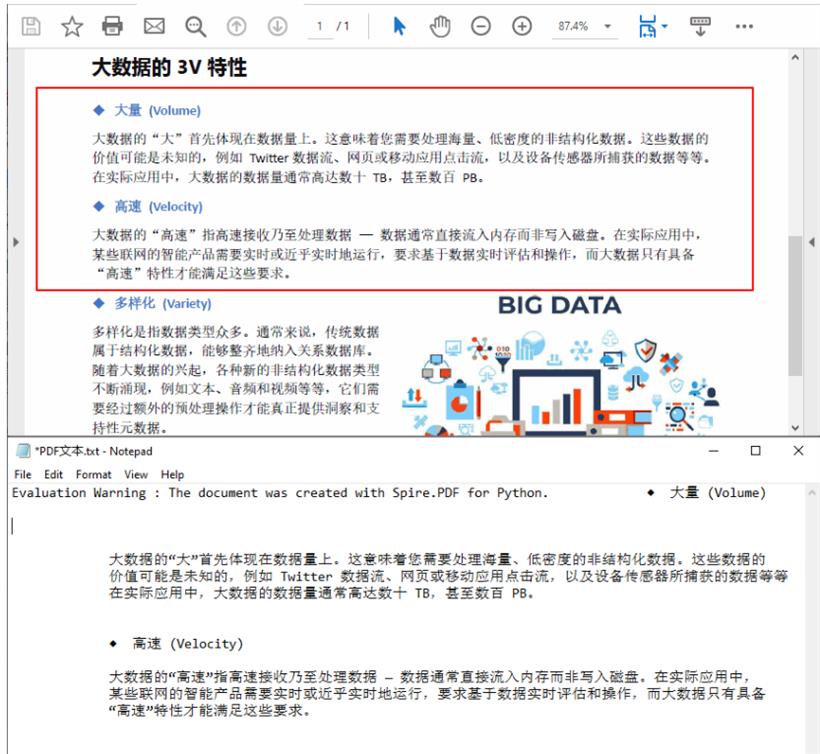
使用 Python 提取PDF页面中指定矩形区域的文本
如果你只需要提取某个PDF页面中指定区域的文本,你可以指定一个矩形范围然后使用 PdfPageBase.ExtractText(RectangleF rectangleF) 方法提取其中的文本内容。完整Python代码如下:
from spire.pdf import *
from spire.pdf.common import *
# 创建PdfDocument类的对象
pdf = PdfDocument()
# 加载PDF文档
pdf.LoadFromFile("大数据.pdf")
# 获取第一页
page = pdf.Pages.get_Item(0)
# 从页面的指定矩形区域提取文本
text = page.ExtractText(RectangleF(0.0, 400.0, 770.0, 180.0))
# 将提取的文本保存到TXT文件中
extractedText = open("Output/PDF文本.txt", "w", encoding="utf-8")
extractedText.write(text)
extractedText.close()
pdf.Close()
 使用 Python 提取PDF图片
使用 Python 提取PDF图片
除了提取文本外,Spire.PDF for Python 还提供了 PdfPageBase.ExtractImages() 方法来提取PDF文件中的图片。要提取一个PDF文件中的所有图片并保存到指定路径,参考以下Python代码。
from spire.pdf import *
from spire.pdf.common import *
# 创建PdfDocument类的实例
pdf = PdfDocument()
# 加载PDF文档
pdf.LoadFromFile("大数据.pdf")
# 创建一个列表来存储图篇
images = []
# 遍历文档的每一页
for i in range(pdf.Pages.Count):
# 获取页面
page = pdf.Pages.get_Item(i)
# 从页面提取图片并存储在创建的列表中
for img in page.ExtractImages():
images.append(img)
# 保存图像
i = 0
for image in images:
i += 1
image.Save("Output/图片/图片-{0:d}.png".format(i), ImageFormat.get_Png())
pdf.Close()



 闽公网安备 35020302035485号
闽公网安备 35020302035485号






