- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

要使用Python下载PDF文件,你可以使用requests库来获取网页上的内容,然后用pdf处理库如pdfplumber或PyPDF2来保存获取到的PDF内容。
代码如下:
from datetime import datetime
import requests
import sys
from pyquery import PyQuery as pq
import os
import time
path='./book'
baseUrl = 'http://124.223.24.112:8083'
host = f'{baseUrl}/'
host1=f'{host}book/'
ls=[]
def count_files_in_directory(directory):
# 堆代码 duidaima.com
# 统计给定目录中的文件个数
return len([f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))])
def downBook():
if not os.path.exists(path):
os.makedirs(path, exist_ok=True)
page =7
headers={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.40'
}
for i in range(1,page+1):
url = f"http://124.223.24.112:8083/page/${page}?data=root&sort_param=stored"
content=requests.get(url,headers=headers)
pq1=pq(content.text).find('.author-name')
for k in pq1:
j=host1+k.attrib['href'].split('/')[-1]
ls.append(j)
if len(ls):
for i in ls:
time.sleep(1)
childUrl(i)
num_files = count_files_in_directory(path)
print(f"所有文件下载完成,'./book' 目录中总共有 {num_files} 个文件。")
def childUrl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.40'
}
content = requests.get(url, headers=headers)
href2 = pq(content.text).find('#btnGroupDrop1pdf').attr('href')
if not href2:
print('没有下载地址')
return
bb1 = baseUrl + href2
js = href2.split('/')[-1]
# 检查文件是否已存在
target_file_path = os.path.join(path, js)
if os.path.exists(target_file_path):
local_file_size = os.path.getsize(target_file_path)
response = requests.head(bb1, headers=headers)
remote_file_size = int(response.headers.get('content-length', 0))
# 检查本地文件和远程文件的大小是否匹配
if local_file_size == remote_file_size:
print(f"文件 {js} 已经存在并且是完整的,跳过下载。")
return
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f'正在下载 {js} 的书籍,当前时间:{current_time}')
response = requests.head(bb1, headers=headers)
file_size = int(response.headers.get('content-length', 0))
down_size = 0
progress_len = 100
bdata = requests.get(bb1, headers=headers, stream=True)
with open(path + '/' + js, 'wb') as f:
for chunk in bdata.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
down_size += len(chunk)
progress = int(progress_len * down_size / file_size)
# 格式化文件大小和已下载大小
formatted_file_size = format_size(file_size)
formatted_down_size = format_size(down_size)
sys.stdout.write(f'\r[{"=" * progress}{"~" * (progress_len - progress)}] {progress}% ({formatted_down_size}/{formatted_file_size})')
sys.stdout.flush()
# 检查是否下载完成
if progress == 100:
print(f'\n下载 {js} 书籍完成')
print(f'\n下载 {js} 书籍完成')
def format_size(bytes):
# 将字节转换为更易读的单位(KB、MB等)
for unit in ['B', 'KB', 'MB', 'GB', 'TB']:
if bytes < 1024.0:
break
bytes /= 1024.0
return f"{bytes:.2f} {unit}"
if __name__ == '__main__':
downBook()
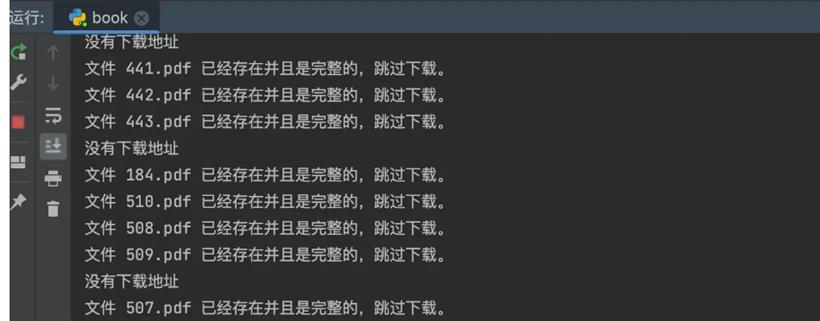
最终截图