在 Python 中,进程/线程是个非常重要的概念,特别是 Python 还有 GIL(同一时刻只有一个线程在执行 Python bytecode)限制,使得 Python 线程并不那么好用。但 GIL 更多的是影响 CPU 密集型任务,实际业务场景更多的是 IO 密集型任务,多线程还是适用绝大多数场景。不过话又说回来,很多时候不太好判断是 IO 密集型多还是 CPU 密集型多,需要在多进程、多线程环境下分别验证。
但多线程和多进程手写起来还是有点差别,好在 multiprocessing.Pool 提供了统一的接口,可以无缝切换:
# 进程池
from multiprocessing import Pool
# dummy(假)的进程,线程池
from multiprocessing.dummy import Pool as ThreadPool
下面介绍下 Pool 类如何使用。
首先是构造函数:
class multiprocessing.Pool([processes[, initializer[, initargs[, maxtasksperchild]]]])
接收 processes initializer initargs maxtasksperchild 4个参数:
processes,就是池里有多少个进程,可以不传,默认 CPU 个数,可以按需多设置几倍
initializer、initargs,如果设置了参数,则会在每个进程初始化的时候调用 initializer(*initargs)。这个非常有用,比如可以在初始化的时候建立连接,连接重用。
maxtasksperchild,用于设置每个子进程执行多少个任务后重启。虽然很简单粗暴,但这是防止内存溢出、资源未释放等问题的常见手段,类似 PHP-FPM 的 pm.max_requests 参数。线程池无此参数。
def _send_request(sql):
"""
发送单个请求
:param request:
:return:
"""
# 取出绑定的数据库连接
db_conn = _send_request.db_conn
db_conn.execute(sql)
def _initializer(func):
"""
线程初始化工作
:param func:
:return:
"""
# 堆代码 duidaima.com
# 绑定建立的数据库连接到请求函数的属性上
func.db_conn = mysql.connector.connect()
pool = ThreadPool(10, initializer=_initializer, initargs=(_send_request))
result = pool.map(func=_send_request, request_list)
pool.close()
pool.join()
这里有一个 hack 技巧,将初始化的数据库连接,绑定在了请求函数上,这样调用请求函数发送请求时,就不用重新建立连接,直接使用即可。
我们一般使用线程池有两个场景,一是关注执行结果,比如我们并行去 redis mysql 各个地方请求数据,然后整合这些数据,二是不关注执行结果,比如新开一个线程打印一个请求的审计日志,不阻塞主进程返回数据。这里主要是介绍下 apply 和 apply_async 的区别,其它的都类似。
apply(func[, args[, kwds]]),主要是传一个执行函数和参数,阻塞并得到返回结果。
apply_async(func[, args[, kwds[, callback]]]),也是主要传执行函数和参数,但返回的是一个 multiprocessing.pool.AsyncResult 对象,AsyncResult 主要有 get([timeout])、wait([timeout])、ready()、successful() 4 个方法,都很好理解,用的比较多的是 get 方法,给定超时时间内获取执行的结果,如果超时抛出 multiprocessing.TimeoutError 异常。如果 timeout 是 None,则一直就等待,行为就和 apply 一致了,实际上 apply 也是调用的 apply_async get:
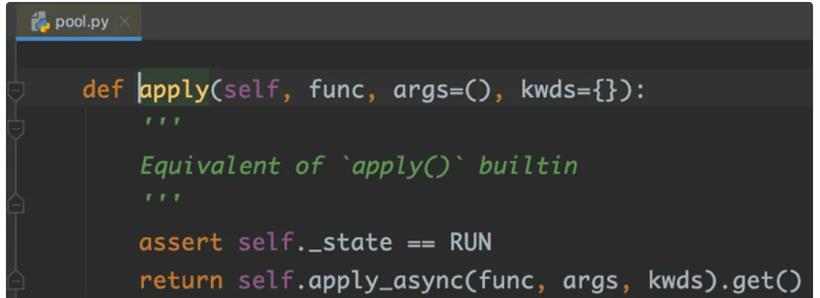
apply_async 还有一个有用的参数 callback,相对于异步回调了,一般用于上述的场景二。下面是一些示例:
#!/usr/bin/env python
# -*- coding: utf-8 -*
from multiprocessing.dummy import Pool
import time
callback_start_time = 0
def f_sleep(x):
time.sleep(3)
return x*x
def callback_func(result):
print 'callback result:%s use:%s' % (result, current_time_millis() - callback_start_time)
def current_time_millis():
"""
当前时间戳 ms
:return:
"""
return int(round(time.time() * 1000))
if __name__ == '__main__':
pool = Pool(processes=10)
t1 = current_time_millis()
result = pool.apply(f_sleep, (10,))
t2 = current_time_millis()
print 'apply result:%s use:%s' % (result, t2 - t1)
result = pool.apply_async(f_sleep, (10,))
t3 = current_time_millis()
print 'apply_async result:%s use:%s' % (result, t3 - t2)
result = result.get(timeout=4)
t4 = current_time_millis()
print 'apply_async result2:%s use:%s' % (result, t4 - t3)
callback_start_time = current_time_millis()
result = pool.apply_async(f_sleep, (10,), callback=callback_func)
time.sleep(4) # 看回调结果
运行结果:
apply result:100 use:3001
apply_async result:<multiprocessing.pool.ApplyResult object at 0x10876dc50> use:0
apply_async result2:100 use:3041
callback result:100 use:3002
注意代码的最后一行,这里不仅仅是为了看回调结果,还因为回调是回调到主进程执行,如果主进(线)程已经退出了,那就处理不到回调了,实际使用需要注意运行环境。
最后,multiprocessing 模块的 pool 功能只是其中很小的一部分,但比较实用,后面有新的心得再介绍其它功能。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






