

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("connected!");
}
}
运行cargo run,在浏览器中访问http://127.0.0.1:8080,可以看到控制台输出。浏览器中显示链接被重置,无法被访问,因为没有响应任何数据。通过listener.incoming()方法返回一个迭代器,它是客户端与服务端之间打开的连接。称之为stream流,可以用来处理请求、响应。
use std::io::{prelude::*, BufReader};
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
for stream in listener.incoming() {
let mut stream = stream.unwrap();
// 堆代码 duidaima.com
// 处理请求
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
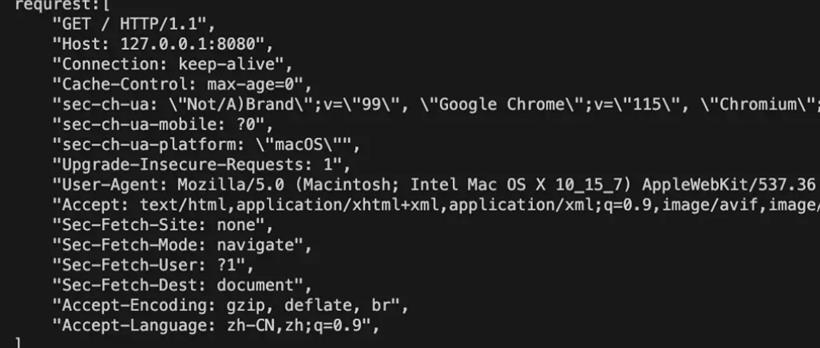
println!("requrest:{:#?}", http_request);
}
}
BufReader 实现了BufReadtrait,提供了lines方法,通过换行符切割数据流返回一个Result<String,std::io::Error>迭代器。通过map获取到每一个结果值,take_while处理值直到为空结束,然后collect收集结果值。
http_request必须指定类型Vec<_>来收集。在闭包那一节中,迭代器适配器,必须调用消费适配器获取结果。
现在尝试给请求作出一个响应,响应状态码200表示成功响应。一个简单的响应头包括了协议、协议版本、响应状态、状态语句。
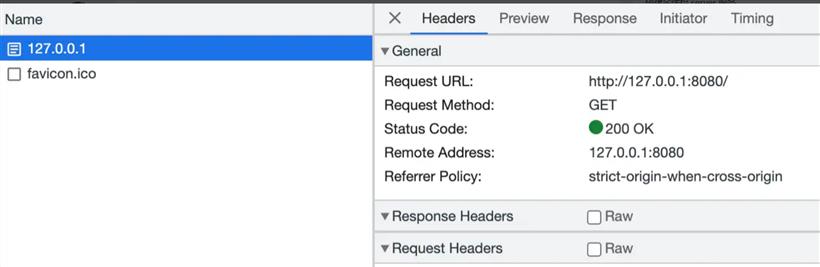
let res = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(res.as_bytes()).unwrap();重新启动,再次浏览器访问地址,可以看到空白页面,F12查看网络请求,可以看到请求成功。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=<device-width>, initial-scale=1.0" />
<title>堆代码 duidaima.com</title>
</head>
<body>
<p>hello world</p>
</body>
</html>
读取index.html文件,并将文件内容作为响应返回let res_status = "HTTP/1.1 200 OK\r\n";
let contents = fs::read_to_string("index.html").unwrap();
let len = contents.len();
let res = format!("{res_status}Content-Length:{len}\r\n\r\n{contents}");
stream.write_all(res.as_bytes()).unwrap();
再次运行,浏览器访问可以看到页面上已经展示信息。现在只要是所有的请求访问都会返回index.html文件,通常我们会根据访问路径来处理响应,比如http://127.0.0.1:8080/home
fn handle_request(mut stream: TcpStream) {
// 处理请求
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
if http_request[0] == "GET / HTTP/1.1" {
let res_status = "HTTP/1.1 200 OK\r\n";
let contents = fs::read_to_string("index.html").unwrap();
let len = contents.len();
let res = format!("{res_status}Content-Length:{len}\r\n\r\n{contents}");
stream.write_all(res.as_bytes()).unwrap();
} else {
let res_status = "HTTP/1.1 404 NOT FOUND\r\n";
let contents = fs::read_to_string("404.html").unwrap();
let len = contents.len();
let res = format!("{res_status}Content-Length:{len}\r\n\r\n{contents}");
stream.write_all(res.as_bytes()).unwrap();
}
}
优化一下if else里的代码,只有响应状态、响应的文件不一样,其他逻辑都一样。let (res_status, file_name) = if http_request[0] == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK\r\n", "index.html")
} else {
("HTTP/1.1 404 NOT FOUND\r\n", "404.html")
};
let contents = fs::read_to_string(file_name).unwrap();
let len = contents.len();
let res = format!("{res_status}Content-Length:{len}\r\n\r\n{contents}");
stream.write_all(res.as_bytes()).unwrap();
main方法中的简化,调用处理请求的函数。fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
for stream in listener.incoming() {
let mut stream = stream.unwrap();
// 处理请求
handle_request(stream);
}
}
现在一个简易的 web 服务就好了,可以处理请求、可以处理响应。在这过程出现的错误我们都用unwrap方法处理,只要遇到错误,直接停止程序,而在真实环境中,需要处理这些错误,避免程序的不可访问。
已经构建了单线程的服务,但是它每次只能处理一个请求,只要完成上一个请求之后才能处理下一个连接。如果请求很多,则需要等待,这种表现使得服务性能很差。
use std::thread::{self};
use std::time::Duration;
fn handle_request(mut stream: TcpStream) {
// ...
// 将if部分改为match匹配,增加/sleep 路径匹配,用以堵塞线程
let (res_status, file_name) = match &http_request[0][..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK\r\n", "index.html"),
"GET /sleep HTTP/1.1" => {
// 线程堵塞5s
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "index.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// ...
}
然后我们打开两个浏览器的 tab 页,访问不同的地址带路径/sleep和不带路径/的,先访问带路径的,可以看到浏览器正在加载,再访问不带路径的也发现浏览器正在加载。等 5 秒过后,全部加载完成,如果直接访问不带路径/则瞬间访问成功。为了处理这种情况,我们尝试为每一个请求都分配一个线程独立去处理请求任务。
fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_request(stream);
});
// handle_request(stream);
}
}
现在可以再次尝试请求/sleep和/,可以发现/瞬间就响应了,/sleep还需要等待 5s。如果有上千、上万个请求,我们就要开同等数量的线程,在占用完所有资源后,就会使系统奔溃。通过线程池,创建有限的线程数量。在处理请求时,内部执行的方法execute会检测空闲的线程并执行之后的请求任务,如果请求超过线程池线程数量,则排队等待。
fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
// 创建线程池
let threadPool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
// thread::spawn(|| {
// handle_request(stream);
// });
threadPool.execute(|| {
handle_request(stream);
})
// handle_request(stream);
}
}
pub struct ThreadPool;
impl ThreadPool {
/// 创建线程池
///
/// 线程池中线程的数量
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
定义完之后,回到项目rust-web项目,引入依赖,在Cargo.toml,[dependencies]
thread_pool = {path="../rust-lib/thread_pool"}
然后在src/main.rs使用依赖use thread_pool::ThreadPool;, 运行程序cargo run,没有报错正常运行。在new方法中要保证初始化的线程数是一个有效的值,即size不能为分数或等于 0.这没有意义。然后初始化 vector 实例来存储线程实例,thread::spawn()执行后返回的类型为thread::JoinHandle,它可以管理并等待创建的线程完成任务。use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
/// 创建线程池
///
/// 线程池中线程的数量
///
/// # Panics
///
/// `new`函数在size为0 时panicthread_pool
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// 创建对应数量的线程,并把它们存储到vec中
}
ThreadPool { threads }
}
// ...
}
之前一直在使用thread::spawn()来创建线程,并执行任务。现在在线程池中,需要提前创建线程,等待任务传入后再执行。标准的 rust 库中没有这样的定义,仍需要自己实现,可以称之为Worker数据结构,这样我们在ThreadPool存储的是Worker实例,在 worker 实例中存储一个单独的JoinHandle<()>实例,并赋予该实例一个唯一的id,方便日志和调用栈区分。
use std::thread;
pub struct ThreadPool {
// threads: Vec<thread::JoinHandle<()>>,
workers: Vec<Worker>,
}
impl ThreadPool {
/// 创建线程池
///
/// 线程池中线程的数量
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
// let mut threads = Vec::with_capacity(size);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
// 创建对应数量的线程,并把它们存储到vec中
workers.push(Worker::new(id))
}
ThreadPool { workers }
}
// ...
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}
运行我们的代码,正常运行。现在需要解决的是向创建的线程传递要处理的请求任务,通过之前文章中学过的channel信道来传递信息.在ThreadPool中存在一个信道实例充当发送者;并新建一个Job结构体存放用于向信道发送的闭包;execute方法会发送期望执行的任务。use std::{sync::mpsc, thread};
pub struct ThreadPool {
// threads: Vec<thread::JoinHandle<()>>,
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
// let mut threads = Vec::with_capacity(size);
let mut workers = Vec::with_capacity(size);
// 创建信道实例,提供一个发送者、接收者
let (sender, receiver) = mpsc::channel();
for id in 0..size {
// 创建对应数量的线程,并把它们存储到vec中
workers.push(Worker::new(id,receiver))
}
ThreadPool { workers, sender }
}
}
ThreadPool实例存储信道发送者对象sender,需要将接受者实例receiver传递给Worker用于接收传递的信息。impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}
这会有一个错误信息,因为在 rust 中信道实现是多生产者、单消费者,不能将receiver接受者传递多个 work 实例。我们希望有一个任务列表,每个任务只允许处理一次。已经解决过在线程间共享状态,通过线程安全智能指针Arc<Mutex<T>>,多个线程共享所有权并允许线程修改其值。Arc使得多个 worker 拥有接受端,而Mutex确保一次只有一个 worker 能接收到任务。
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
// let mut threads = Vec::with_capacity(size);
let mut workers = Vec::with_capacity(size);
let (sender, receiver) = mpsc::channel();
// 通过`Arc<T>`创建多所有者,Mutex<T>共享数据
let receiver = Arc::new(Mutex::new(receiver));
for id in 0..size {
// 创建对应数量的线程,并把它们存储到vec中
workers.push(Worker::new(id, Arc::clone(&receiver)))
}
ThreadPool { workers, sender }
}
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// ...
}
}
最后处理execute方法,它接受的闭包需要分配给空闲的线程并执行,修改Job结构体,它不是一个结构体,是接受execute方法接受的闭包类型的类型别名。// struct Job; type Job = Box<dyn FnOnce() + Send + 'static>;在execute方法被调用后,新建Job实例,将任务从信道发送端发出,因为发送可能会失败,所以需要unwrap处理错误的发生。
impl ThreadPool {
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
继续优化接受端执行任务的逻辑,在接收到任务后,通过lock获取互斥器来锁定资源,防止其他地方使用资源。通过unwrap处理错误时的情况,在获取了互斥器锁定了资源后,调用recv()方法接受任务Job,这会阻塞当前线程,所有如果当前线程没有任务,则会一直等待直到有用的任务。Mutex<T>可以确保一次只有一个 Worker 线程请求任务。impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("开始执行任务{id}");
job();
});
Worker { id, thread }
}
}
通过loop循环执行闭包,一直向信道的接受端请求任务,并在得到任务时执行它们。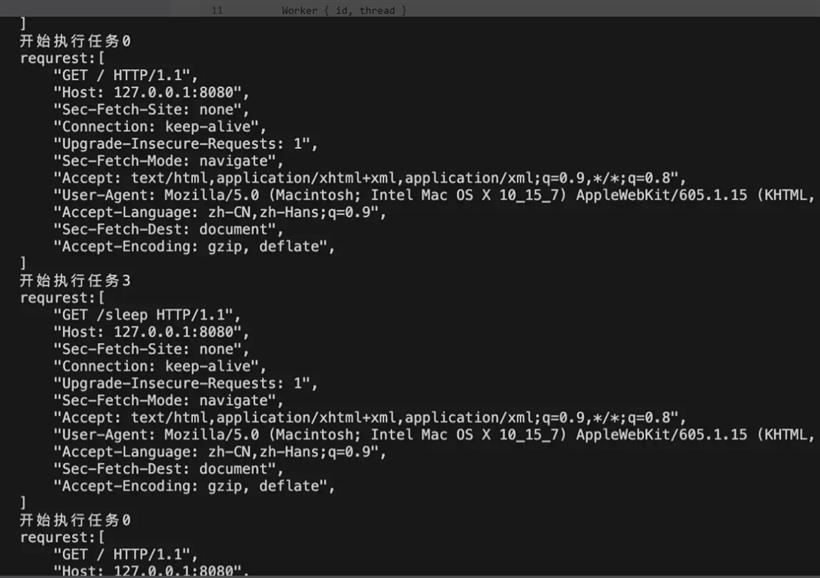
不能使用其他循环,比如while let \ if let \ match是因为它们循环时相关的代码块结束都不会丢弃临时值,导致锁守护的资源不能释放,不能被访问。
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("stop worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
这里会有一个错误,不能编译,提示没有 worker 所有权,因为我们只得到了一个可变借用,不能调用join来消费线程。通过修改来使得thread实例成为一个Option值,这样就可以通过take方法来获取到其中Some成员值进行处理。清理时可以直接将thread赋值为Nonestruct Worker {
id: usize,
// thread: thread::JoinHandle<()>,
thread: Option<thread::JoinHandle<()>>,
}
通过 rust 代码检测提示信息来修改其他需要调整的地方。Workernew 方法创建实例时,接收thread使用Some(thread)impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("stop worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
正常逻辑来说调用了join()之后会关闭线程,但是由于之前的线程逻辑是循环闭包调用等待接受任务,也就是会导致线程一直不会执行完毕,导致阻塞。一直阻塞在第一个线程结束上。通过修改ThreadPool的Drop方法来显式丢弃sender。为了转移sender所有权,同样的使用Option类型来传递pub struct ThreadPool {
// threads: Vec<thread::JoinHandle<()>>,
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
// ...
// ...
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
// self.sender.send(job).unwrap();
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
// 显示的丢弃sender
drop(self.sender.take());
for worker in &mut self.workers {
println!("stop worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
Drop()方法调用显示的丢弃sender后,这会关闭信道,表明了后续不会有消息发送,这时在Worker中无限循环调用接受消息的方法都会返回错误,此时可以修改逻辑在遭遇错误后退出循环。impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("开始执行任务{id}");
job();
}
Err(_) => {
println!("worker {id} disconnected");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}
现在可以正常清理、停机了,如果希望在服务停止前再处理几个请求,通过take()方法模拟只两个请求进行处理,来验证停机的逻辑。它是Iteratortraitfn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
// 创建线程池
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_request(stream);
})
}
}
现在运行程序cargo run,同时在浏览器请求三次,看看控制台如何打印信息,第三个请求不会被执行。可以看到只执行完了两次请求,在第一次请求处理完成后,调用了Drop方法显示的丢弃了信道发送者sender,这样整个就导致所有 worker 关闭连接。




