- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

cargo install flamegraph然后,你可以使用“cargo flamgraph”命令来测试编译好的二进制文件。
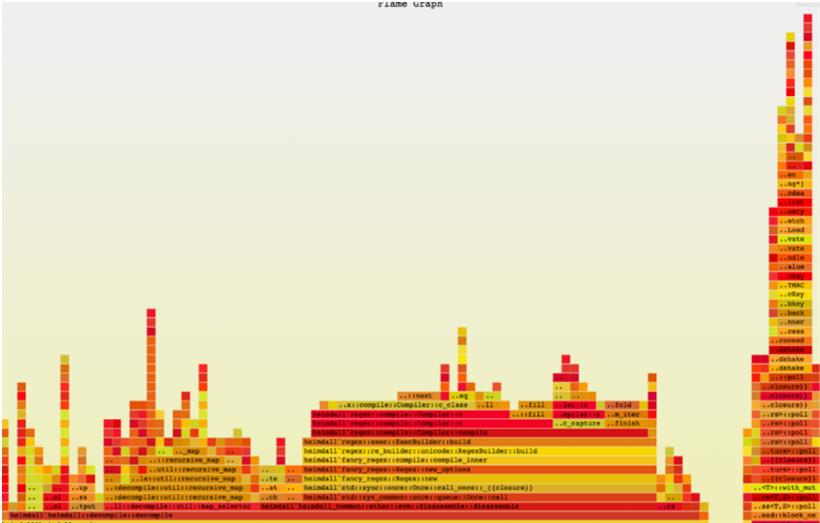
每个框代表一个堆栈帧或一个函数调用。高度表示堆栈深度,最近的堆栈帧位于顶部,较旧的堆栈帧位于底部。子框架驻留在调用它们的函数之上。帧的宽度表示一个函数或它的子函数被处理的总时间。您可以将鼠标悬停在一个框架上以获取更多细节,并单击一个框架展开它以获得更细粒度的视图。每个帧的颜色并不重要,并且是随机的,除非你使用 --deterministic参数,这将在运行期间保持功能/颜色的一致性。
[dev-dependencies]
criterion = { version = "0.5.3", features = ["html_reports"] }
[[bench]]
name = "my_benchmark"
然后,你可以在benches/my_benchmark.rs中编写你的基准测试代码:use criterion::{black_box, criterion_group, criterion_main, Criterion};
fn fibonacci(n: u64) -> u64 {
match n {
0 => 1,
1 => 1,
n => fibonacci(n-1) + fibonacci(n-2),
}
}
fn criterion_benchmark(c: &mut Criterion) {
c.bench_function("fib 20", |b| b.iter(|| fibonacci(black_box(20))));
}
criterion_group!(benches, criterion_benchmark);
criterion_main!(benches);
最后,用以下命令运行这个基准测试:cargo bench在进行优化时,请始终记住对代码进行基准测试,以确保所做的更改确实提高了程序的性能。如果基准测试没有显示出足够显著的速度改进,那么可能就不值得进行优化。
一定要仔细考虑哪种数据结构最适合你的问题,因为选择正确的数据结构会对代码的性能产生巨大影响。
use std::collections::HashMap;
fn get_data_from_database(id: u32, cache: &mut HashMap<u32, String>) -> String {
if let Some(data) = cache.get(&id) {
return data.clone();
}
let data = perform_expensive_database_query(id);
cache.insert(id, data.clone());
data
}
fn perform_expensive_database_query(id: u32) -> String {
// 模拟一个昂贵的数据库查询
println!("Performing database query for ID {}", id);
// ... 数据库访问和数据检索 ...
let data = format!("Data for ID {}", id);
data
}
fn main() {
let mut cache: HashMap<u32, String> = HashMap::new();
// 多次从数据库查询数据
for _ in 0..5 {
let id = 42;
let data = get_data_from_database(id, &mut cache);
println!("Data: {}", data);
}
}
运行上面的代码,我们可以看到数据库查询只执行一次,尽管我们使用相同的输入多次调用get_data_from_database函数。这是因为我们缓存结果并返回它,而不是每次都重新计算它,从而节省了执行不必要的昂贵查找的时间。
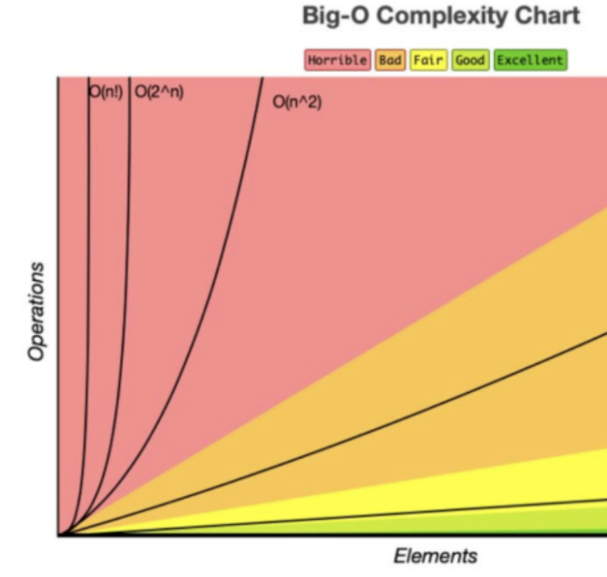
理解算法的时间复杂度对于编写高效代码至关重要。时间复杂度描述了算法的运行时间如何随着输入大小的增加而增长。通过选择具有更好时间复杂度的算法,可以显著提高代码的性能。
如图: