

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

List < Future < Result < List < InfoVO >>> > futures = new ArrayList < > ();
lists.forEach(item - > {
futures.add(enhanceExecutor.submit(() - > feignClient.getTimeList(ids)));
); futures.forEach(
item - > {
try {
Result < List < InfoVO >> result = item.get(10, TimeUnit.SECONDS);
} catch (InterruptedException | TimeoutException | ExecutionException e) {
log.error("error", e);
}
}
);
代码逻辑非常简单,就是将一个Feign接口的调用提交给线程池去并发执行,最终通过Feture.get()同步获取结果,最多等待10s。
在服务下线前该线程池会响应一个event bus消息,然后执行线程池的shutdown方法,本意是服务下线时,线程池不再接收新的任务,并触发拒绝策略。那会不会是这里出现问题呢?
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.MINUTES, new ArrayBlockingQueue < > (1), new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
//到这里就阻塞了
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
那如何期间shutdown了呢?按照网上的很多介绍,如果线程池shutdown了,再提交任务,就触发拒绝策略。这句话本身没有错,但也没有完全对,坑就在这里。 如果你执行下面的代码,会发现和上面是不一样的,第三个submit不会阻塞了。ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.MINUTES, new ArrayBlockingQueue < > (1), new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
//加了这一行
threadPoolExecutor.shutdown();
//这里不会阻塞了...
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
为什么会这样呢,我们跟踪下源码,发现它确实会走到拒绝策略,但在CallerRunsPolicy拒绝策略里面有一个判断,如果线程池不是shutdown的,就直接调用Runnable的run方法,这里使用的是调用者线程,所以调用者线程会阻塞,如果线程池是shutdown的,就什么也不做,相当于任务丢弃了。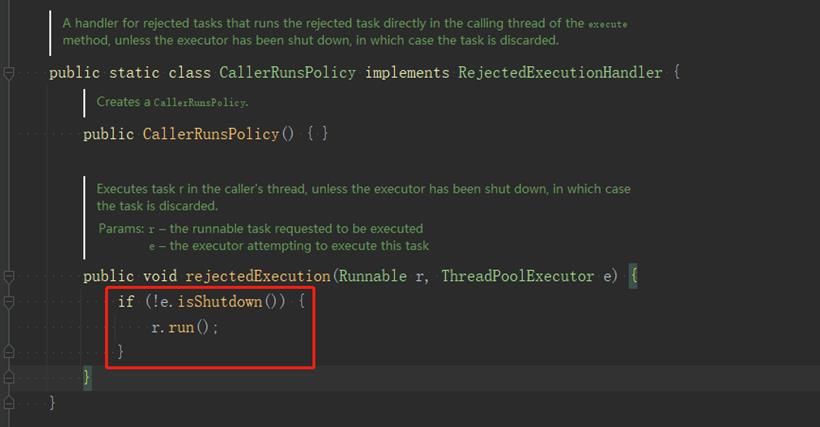
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.MINUTES, new ArrayBlockingQueue < > (1), new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
//加了这一行
threadPoolExecutor.shutdown();
//这里不会阻塞了...
Future future = threadPoolExecutor.submit(() - > {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {}
});
//这里会发生什么?
future.get(10, TimeUnit.SECONDS);
结果是超时了,报了TimeoutException,如下图: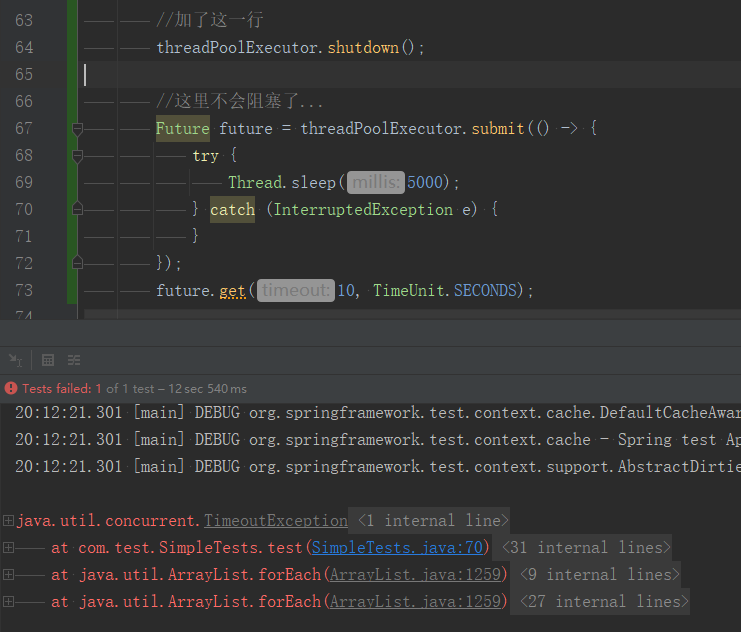
Future字面意思是未来的意思,很符合语意。当我们使用异步执行任务的时候,在未来某个时刻想知道任务执行是否完成、获取任务执行结果,甚至取消任务执行,就可以使用Future。Future是一个接口,FutureTask是它的一个实现类,同时实现了Future和Runnable接口,也就是说FutureTask即可以作为Runnable执行,也可以通过它拿到结果。
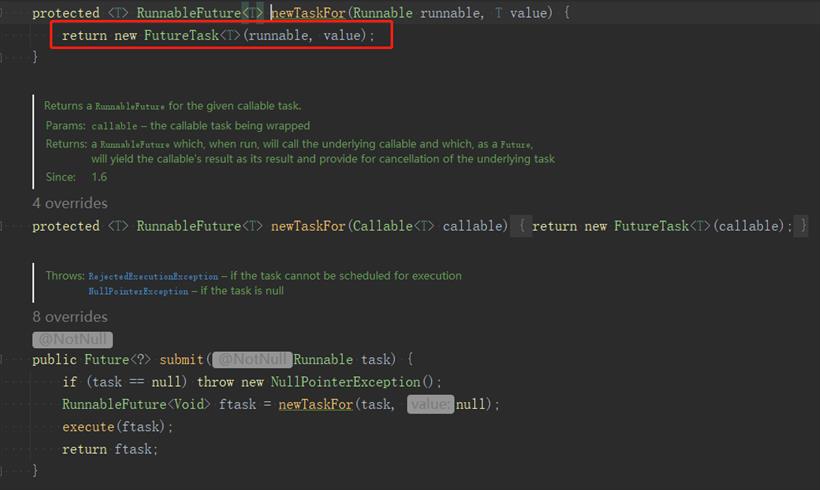
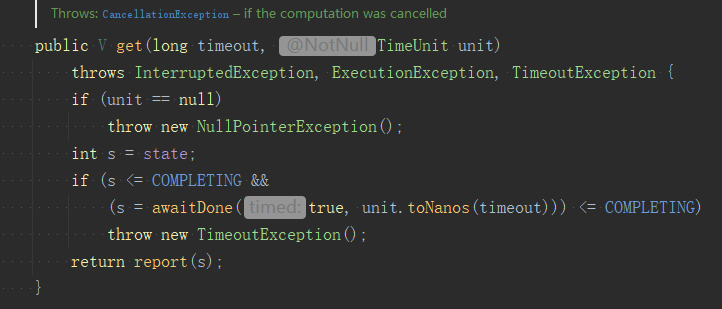
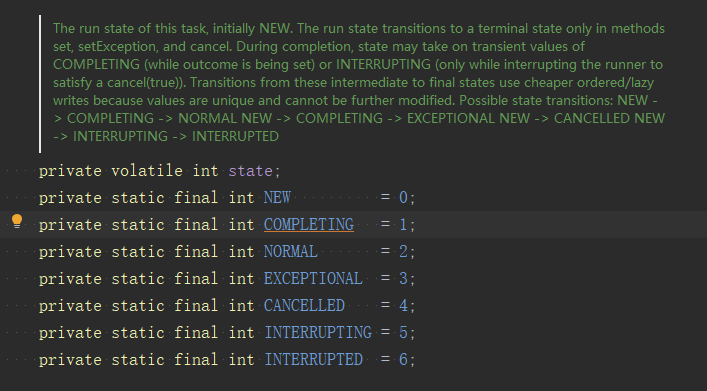

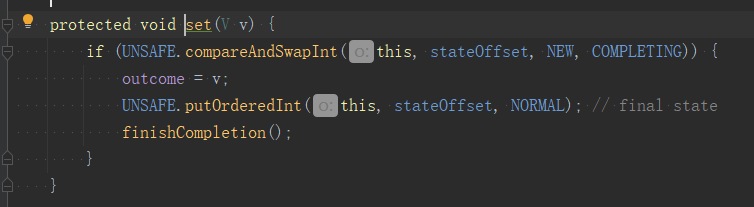
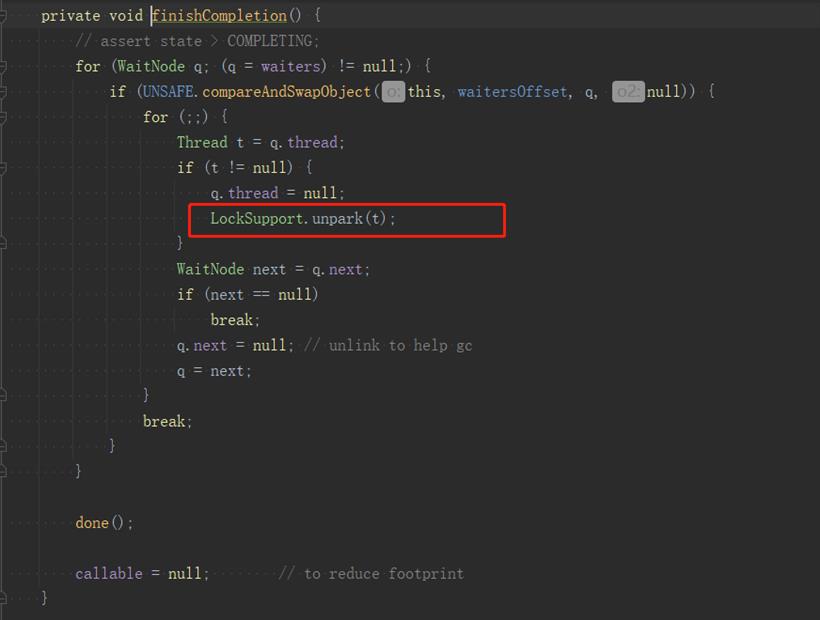
当我们线程shutdown后,再submit任务确实会触发拒绝策略,但CallerRunsPolicy会判断线程池状态是否是shutdown,如果不是,就直接调用Runnable.run()方法,相当于在调用线程执行。
如果是shutdown状态就什么都不做,问题就出在这里,我们是要依靠它的执行来恢复阻塞的,现在什么都不做,就无法恢复了。同样的DiscardPolicy,DiscardOldestPolicy也会有这个问题,AbortPolicy是直接抛出异常,调用线程在submit就抛异常了,走不到Future.get()方法。
但java为什么要这么做呢?这个拒绝策略的本意就是使用调用者线程执行,但这种情况下却将任务丢弃了。我看了jdk17的源码,这个逻辑并没有改变,也就是有一定的合理性。
线程池关闭当线程池已经shutdown,则意味着其不能再接收新任务,如果它shutdown了还使用调用线程执行,其实本质上还是在接收新任务,这违背了线程池规定的shutdown以后不再接收新任务的语意。




