全球排名第一CRM厂商Salesforce开源了,70亿参数的类ChatGPT大语言模型XGen-7B。(开源地址:
https://github.com/salesforce/xgen)
XGen主要亮点功能包括:支持超长8000内容输入长度,同类开源产品多数都在2000左右;在1.5万亿tokens数据集上进行训练,Salesforce认为,参数并不是提升大语言模型性能的唯一标准,在海量优质数据上进行训练同样非常重要;
除了文本、还支持多种代码生成;资源消耗低性能强大,支持Apache-2.0允许商业化。目前,XGen推出了4K、8K两个商业化版,以及8K指令微调(只能用于技术研究)版本。
Salesforce是全球对ChatGPT等生成式AI投入大量资源、最积极的科技巨头之一,非常看好其未来发展。例如,Salesforce成立了一个5亿美元的专注投资生成式AI的基金,并参与了近期多家生成式AI厂商的融资;宣布将在云计算、CRM、人力资源等多个产品矩阵中集成生成式AI等。
XGen-7B的预训练数据
Salesforce在训练XGen-7B时,采用了两个阶段训练策略,并且每个阶段都使用了不同的数据混合来源。
第一阶段,1.37万亿tokens数据,主要包括来自RedPajama提供的普通抓取数据、GitHub、书籍、ArXiv以及C4、维基百科等数据。其中,对来自C4的数据进行了删除重复数据处理;维基百科的数据包括英文本和bg、ca、cs、da,、de、en、es等22种语言其他数据。
第二阶段1100亿tokens数据。该阶段主要来自Starcoder(开源地址:
https://github.com/bigcode-project/starcoder)的代码数据,并与第一阶段的数据进行了混合,使得XGen具备生成代码的能力。此外,开发团队还使用了OpenAI开源的tiktoken(地址:
https://github.com/openai/tiktoken)对数据集进行了标记,包括为连续的空格和制表符添加额外的标记和特殊标记。
XGen-7B的测试结果
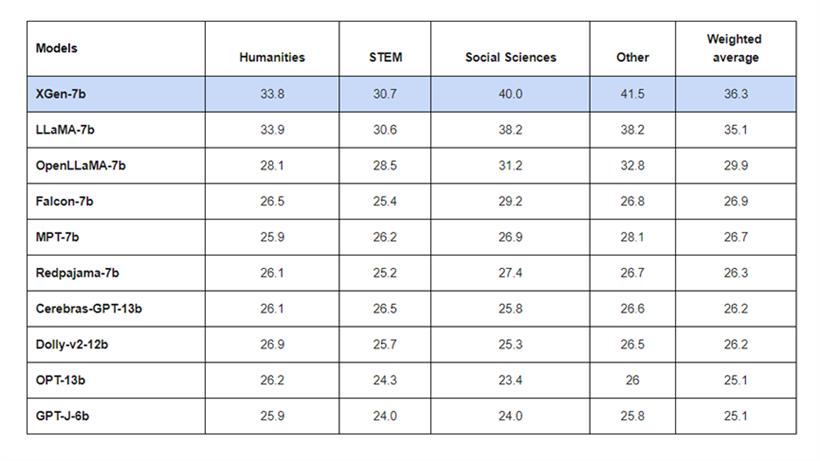
开发团队在测试XGen-7B的性能时,采用了原始统一的MMLU标准进行了评估。MMLU 5-shot 上下文学习结果:XGen-7B在人文学科、社会科学等栏目中取得了最佳效果,超过了LLaMA-7b、OpenLLaMA-7b、Redpajama-7b、Dolly-v2-12b等知名同类开源项目。
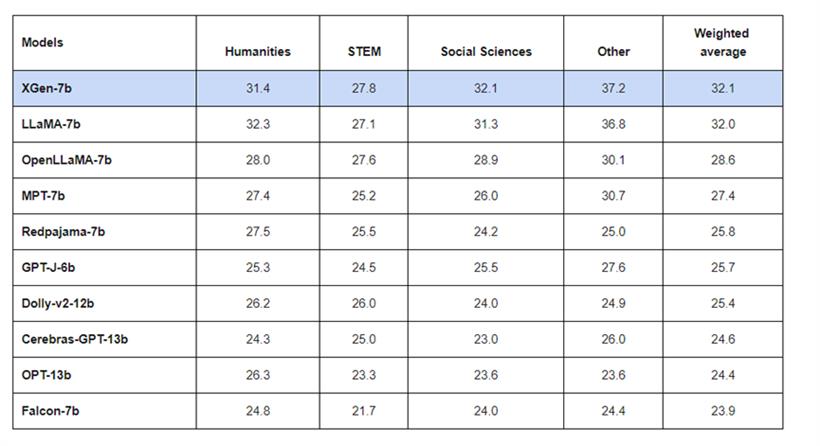
MMLU 0样本测试:在零样本MMLU 上,XGen-7B同样取得了出色的成绩,性能上与LLaMA-7B基本持平。
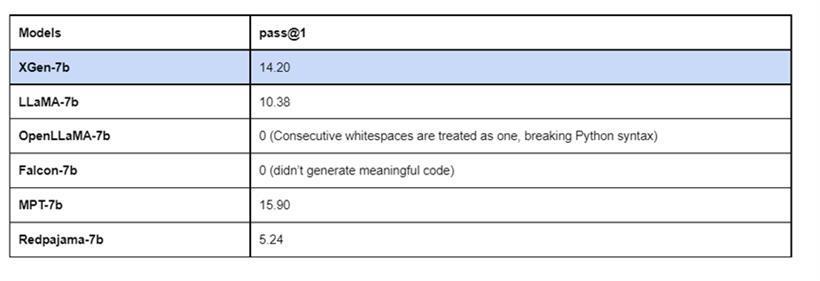
为了测试XGen-7B的代码生成能力,开发团队在著名的HumanEval基准上进行了评估。将采样热度设置为0.2,p设置为 0.95(对于top-p采样),将num_samples_per_task (n) 设置为200。测试结果显示,XGen-7B的代码生成能力超过了LLaMA-7b、Redpajama-7b等,仅次于MPT-7b。
 XGen-7B对话、摘要能力测试
XGen-7B对话、摘要能力测试
为了测试XGen-7B的长对话、文本摘要能力,开发团队使用AMI会议摘要、ForeverDreaming和TMS剧本摘要。这3个数据集的平均长度分别约为5570、6466和 7653,开发团队使用各种指令调整模型专门评估长度小于8000的样本。结果显示,XGen-7B全部取得了出色的结果。
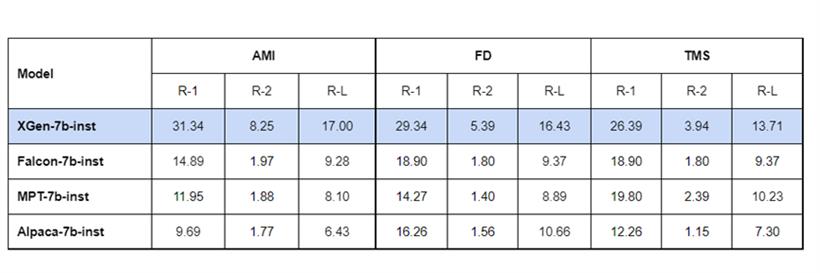
总体来说,对于那些想使用长文本输入,想应用于商业化,算力有限的厂商来说XGen-7B是一个不错的选择。需要注意的是,XGen-7B与其他大语言模型一样,可能会出现幻觉、虚假信息、偏见、非法输出等行为,但Salesforce会持续对其进行优化、迭代战胜这些困难。
关于Salesforce
Salesforce创立于1999年,总部位于美国旧金山,主要提供营销云、服务云、销售云、软件开发等,是全球最大SaaS企业之一。Salesforce在全球拥有近8万名员工,市值约1530亿美元,年收入超过300亿美元。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号