关于SDXL的生态目前还未完全稳定,但是不得不提到的就是SDXL的在VAE,CLIP,UNET三大组件的巨大提升,其101亿的参数量是原本SD的N倍,那么对于SDXL的生态介绍我们再次重复一遍。4G的显存都能跑SDXL意味着将来大模型Lora将降低其大小,炼丹炉压力更小~
SDXL为什么强?
0.1参数训练量为101亿 其中BASE模型35 亿 加REFINER模型66亿 SD的8倍???
0.2对Stable Diffusion原先的U-Net(XL Base U-Net 一共14个模块),VAE,CLIP Text Encoder三大件都做了改进。可以明显减少显存占用和计算量
0.3增加一个单独的基于Latent(潜在)的Refiner(炼制)模型,来提升图像的精细化程度。【新增:对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。】
0.4设计了很多训练Tricks(技巧)(这些Tricks都有很好的通用性和迁移性,能普惠其他的生成式模型),包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。
0.5先发布Stable Diffusion XL 0.9测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用RLHF技术优化迭代推出Stable Diffusion XL 1.0正式版。
0.6采样方法禁用DDIM (保留意见、非绝对),不需要开启CN,随着CN的支持,可以开启CN的XL版本。所有的环境需要都是XL的生态
0.7直接出1024分辨率图片 1024 * 1024 起步

随之而来的就是对大显存的占用,但随着新的PR的提出,或将在4G的测试显存,并在一定的内存占用上解决!!!
A big improvement for dtype casting system with fp8
storage type and manual cast
一个很大的提升对于FP8的内存和手动转换。在 pytorch 2.1.0 之后,pytorch 添加了 2 个新的 dtype 作为存储类型:float8_e5m2、float8_e4m3fn。基于讨论使用 fp8 作为训练/使用 NN 模型的参数/梯度的论文。我认为值得对 fp8 格式进行一些优化。此外,一些扩展也已经支持这个功能。
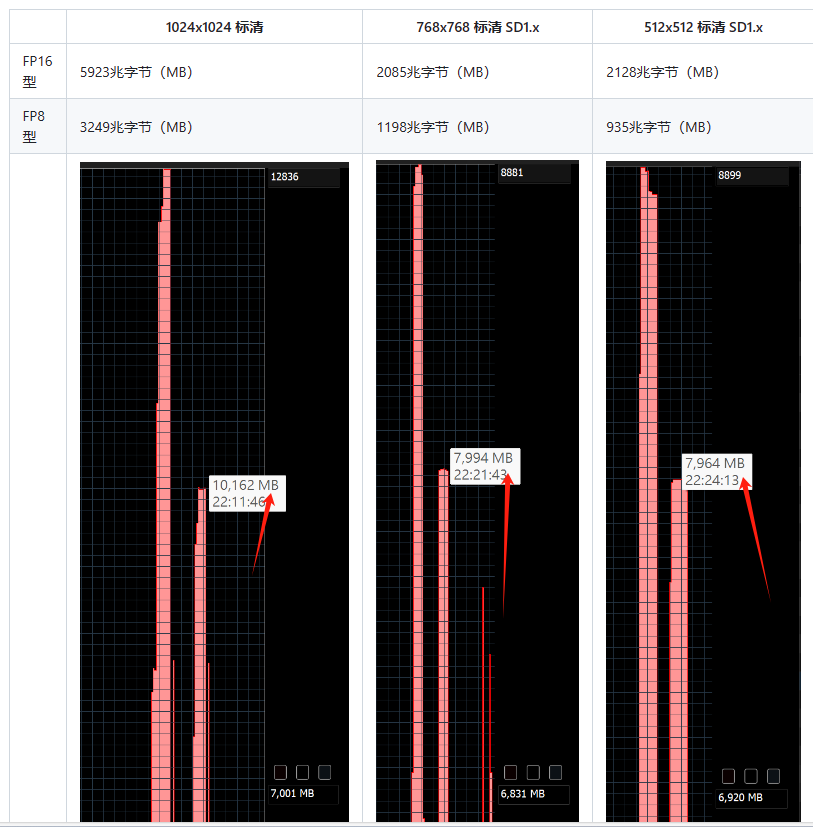 速度提升
速度提升
由于将 FP8 与 FP16 一起使用,因此计算需要一些额外的操作来强制转换 dtype。它会降低速度(特别是对于较小的批量)
|
批量大小
|
768x768 标清1.x fp16
|
768x768 标清1.x fp8
|
1024x1024 SDXL fp16
|
1024x1024 SDXL fp8
|
|
1
|
8.27 秒/秒
|
7.85 秒/秒
|
3.84 秒/秒
|
3.67 秒/秒
|
|
4
|
3.19 秒/秒
|
3.08 秒/秒
|
1.51 秒/秒
|
1.45 秒/秒
|
什么是FP8 FP16?
Fp16:意味模型用16位浮点数存,相对于Fp32更小更快,但是无法用于CPU,因为有的半浮点精度运算在CPU上不支持。通常为了更快的运算,在GPU上我们也会将Fp32转换成Fp16,这个可以在设置里配置。那么随之而来的一个params是8个byte(字节),FP32就是4个byte,FP8就是一个Byte,FP或者BF16相对已经是比较好的出图质量了。
以下测试结果来自原PR作者琥珀青叶,如果你想要尝试,在源码中切换此PR即可
首先SD1的时候FP16存下来是2G,SDXL因为参数变多了FP16也要5G,这样很多显卡就hold不住了。所以青叶做了个事情,就是load的时候用FP8放在显存里,这样SDXL存在显存是2.5G。但是在每一层运算的时候把对应的FP8转到FP16,所以整个计算流程看起来是是一致的。同时整个流程的显存占用也下来的。

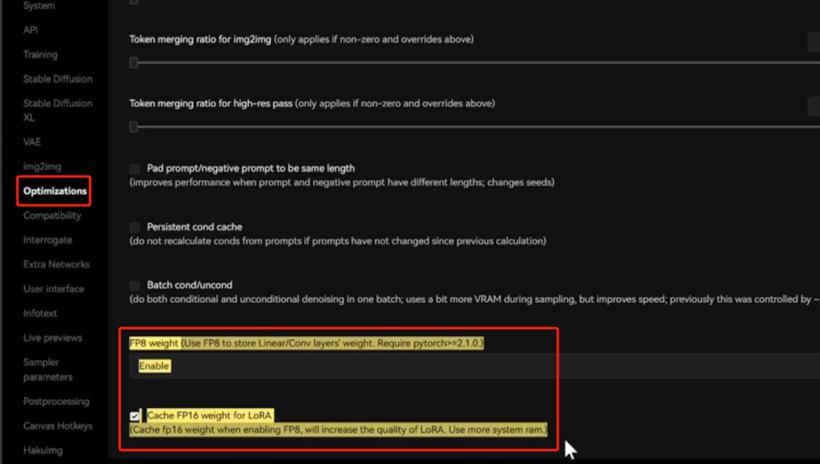
正常启动测试
开启FP8并开启内存缓存优化
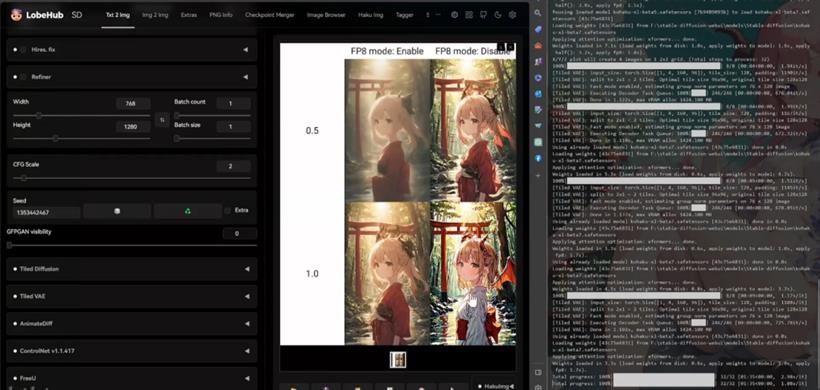
XYZ测试关闭前后对比
起初的静态内存占用为5.3
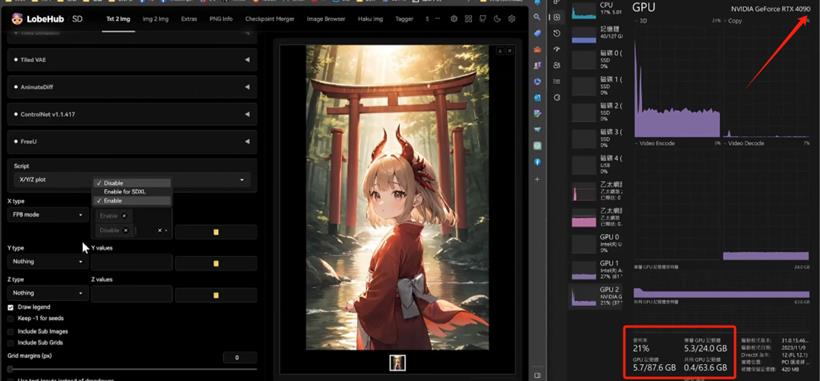
运行后稳定在6.4左右
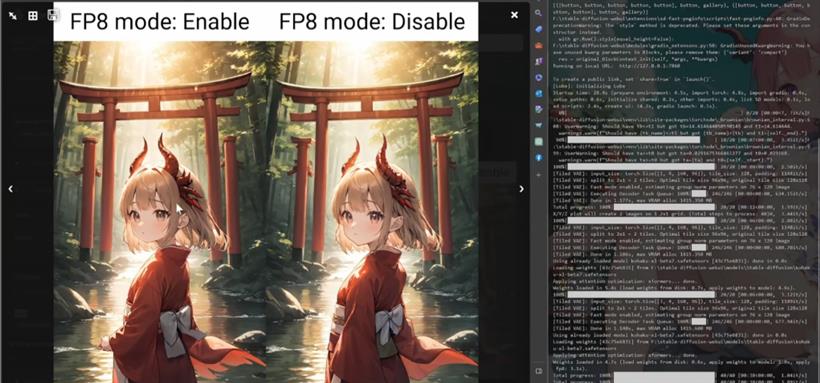
开启前后对图片直连影响很小,有细微细节差距
搭配LCM测试
当前所有的PR审核已经通过,或将在测试后在1.7进行升级推出正式版本


 闽公网安备 35020302035485号
闽公网安备 35020302035485号