引言
随着AIGC技术的快速发展,其中以Stable Diffusion模型为代表的的文生图技术已经在内容生成领域产生了应用价值,用户只需要提供一段文本输入,就能通过AI模型快速生成大量美观的图片,实现了低成本高效率的内容生成。由于文本提供的信息有限,生成的图像内容难以完全对齐用户的意图,生成的图片有时完全不是用户心中想要的内容。为了让用户用起来更加得心应手,最近一年涌现出来了大量关于控制技术的研究。比如Controlnet技术,通过将额外的多样化控制条件(如线稿图、深度图以及分割图等额外信息)应用于文生图扩散模型,可以生成对应结构和布局的图片,用户可以由此更加便捷的对生成图像进行编辑。
参考物体作为图像生成过程时的另一个控制维度,同样受到了广泛关注。基于参考物体的图像生成技术允许用户将参考图像中的物体融入到生成的图像中,同时保留参考物体的身份特征,实现对生成图像中物体的定制化控制。这种技术毫无疑问有广阔的商业价值和应用潜力,比如一个最直接的应用场景就是虚拟试穿。用户只需要提供若干张包含目标服饰的图片,以及自己身材的图片,就可以通过AI模型快速得到目标服饰穿在自己身上的效果,引起用户的购物兴趣。

我们团队一直深耕家装家居导购场景,这种技术同样能够应用于该领域。例如,用户可以通过选择家具或家居装饰品的参考图像,并将其特征融入到生成的家居场景图像中。这样,用户可以在生成的图像中预览所选家具放置在自己家的家居环境中的效果,从而更好地进行家具导购和决策。这种技术的应用实践为用户提供了一种直观、沉浸式的体验,帮助他们更好地理解和评估家居产品的外观和布局,从而进行购物决策。
相关研究
过去,文生图模型引发了一股人工智能热潮,通过给定文本,使合成图像更加高质量和多样化。这些模型将大量图像与文本配对,利用先验学习将词组与图像关联起来,以实现生成具有不同姿势效果的图像。然而,这些模型仍然难以模仿指定参考对象的外观,并且缺乏在不同背景下合成该参考对象的新颖图片。
这主要是因为这种方法的表达能力有限,只能对图像内容进行粗略的变化。即使对图像进行详细的文字描述,仍然难以通过描述准确地重建图像内容或指定对象的外观。换句话说,虽然给定图像可以与文本对应,但文本很难与给定图像一一对应。应对这个问题,本段主要选取两篇相关研究进行详细介绍:基于迭代优化的Dreambooth[1]方法,以及基于物体编码的Blip-diffusion[2]方法。
Dreambooth方法:在Dreambooth论文中,提出了一种名为“个性化”的新方法,以适应用户特定的生成需求。其具体原理是扩展文生图模型的词典,将新的文本标识符与用户想要生成的特定对象联系起来。通过这项技术,能够在不同场景中合成指定参考对象的图像,甚至是在参考图像中没有出现的姿势、视图、照明条件下合成图像。这包括但不限于改变对象所在的位置,以及调整对象的姿势和表情。

该方法的大致思路是,给定一个参考对象(比如某只小狗)的 3-5 张随意拍摄的图像,再为这几张输入图片给定一个文本 prompt 为“a [identifier] [class noun]”,其中[class noun]是参考对象的大类,例如dog,可在个性化生成时利用此大类别的先验知识。而 [identifier] 是连接该参考对象的唯一标识符,为避免受通用词组的先验知识影响,拟定一个相对稀有的标识符来表示,例如[V]。那么本例的 prompt 就是 a [V] dog,其中 dog 指各种各样的小狗,而[V] dog 就特指参考图片中的小狗。使用图片和prompt对预训练文生图模型进行训练微调后,该参考对象与其对应的唯一标识符就被扩展到了文生图模型的词典中。在应用时,输入 a [V] dog in a bucket 就能生成该指定小狗坐在桶中的图像。

Dreambooth方法同时也存在某些缺点,比如耗时的优化过程和在只提供单个图像时容易出现过拟合的倾向。
Blip-diffusion方法:由于Dreambooth方法对于每个参考对象,需要进行耗时长的迭代优化过程,这导致其难以应用于实践。因此,研究人员开始探索基于物体编码的方法。该种方法只需要训练编码器来明确表示对象的视觉概念。一旦训练完成,通过对参考物体的图像进行编码得到的概念嵌入可以直接在推理过程中输入到去噪过程中,实现与标准扩散模型采样过程相当的速度。
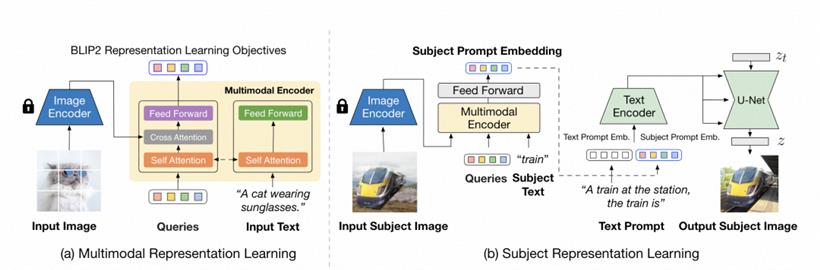
Blip-diffusion方法主要包含两个阶段。第一个阶段是训练一个视觉-文本编码器(Blip2 [3]),具体地说,输入一张包含目标对象的图片及其对应的文本prompt(A cat wearing sunglasses),通过大量这种图像文本对训练 Blip2 编码器,学习与文本空间对齐的图片特征,并同时以高保真度捕捉目标对象的视觉特征。在第二个阶段,通过上一阶段训练好的Blip2 编码器得到文本对齐的对象视觉特征后,对预训练扩散模型进行微调,学习如何在新场景合成目标对象的图片。
在完成两个阶段的训练之后,Blip-diffusion可以对没有见过的参考对象进行 zero-shot 图像合成。此外,当与Controlnet 结合使用时,可以实现带有各种附加结构控制的目标对象驱动生成。
困难挑战与应用实践
在家居导购场景中,用户可以上传自己家的场景图片,然后选择目标家具商品的白底图,得到该家具放置在自己家的效果图。这个过程包含许多的挑战与困难,比如:
角度问题,白底图中的家具视角和用户家场景图的视角存在偏差,如何合成角度和谐的商品效果图?
尺寸问题,2D图片不包含家具的尺寸信息,如何在3D的家中生成尺寸合适的目标家具?
数据质量问题,线上的大量家具商品往往只包含一张白底图,且质量有高有低。以及其它许多问题给技术的实践应用带来了极大的挑战。
得益于我们团队在家装家居领域多年来的数据和技术积累,我们结合3D和AIGC技术解决了上述部分问题,在家居导购领域初步应用了该类技术。以下展示部分场景的效果。
 总结与讨论
总结与讨论
本文深入探讨了基于参考物体的人工智能图像生成(AIGC)技术的最新进展。首先概述了该类技术如何发展至今,然后着重分析了两篇重要的相关学术论文。随后,文章针对家居导购领域的特殊应用场景,讨论了运用此项技术时遭遇的挑战和取得的最新效果。
通过AIGC技术将淘宝商品与用户意图结合起来,基于参考物体的图像生成技术在电商平台中展现出创造性的潜力。此项技术不仅能够提升用户体验,还能优化商品展示效果,因此在未来的电商发展中显示出持续研究与探索的重要价值。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





